
機器學習-周志華-個人練習11.1
阿新 • • 發佈:2019-01-05
11.1 試程式設計實現Relief演算法,並考察其在西瓜資料集3.0上的執行結果。
本題採用Relief演算法處理二分類任務,雖然書上只要求對連續屬性歸一化,但我將離散屬性的值轉化為了1,2,3,如果不對離散屬性歸一化,顯然在查詢近鄰時連續屬性不能有效發揮作用,因此需要將資料的離散屬性和連續屬性都進行歸一化。另外,在計算連續屬性的相關統計量時,本題是二元分類,因此可以對書上公式11.3進行化簡,得到下式,可稍微簡化計算:
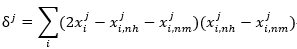
顯然,本題主要分為三步:1、資料歸一化;2、求取各點近鄰near-hit和near-miss;3、求得相關統計量。
由輸出結果可見,分類能力最強的屬性是紋理,其次是根蒂,……很明顯,與其他人用未歸一化離散屬性的結果有所差異,這也說明此方法採用距離得到近鄰來計算統計量,在維數較高,資料複雜時的效果可能不是太好。
程式碼如下:
輸出如下:# -*- coding: utf-8 -*- # 特徵選擇方法:Relief import numpy as np label = {0:'色澤', 1:'根蒂', 2:'敲聲', 3:'紋理', 4:'臍部', 5:'觸感', 6:'密度', 7:'含糖率'} D = np.array([ [1, 1, 1, 1, 1, 1, 0.697, 0.460, 1], [2, 1, 2, 1, 1, 1, 0.774, 0.376, 1], [2, 1, 1, 1, 1, 1, 0.634, 0.264, 1], [1, 1, 2, 1, 1, 1, 0.608, 0.318, 1], [3, 1, 1, 1, 1, 1, 0.556, 0.215, 1], [1, 2, 1, 1, 2, 2, 0.403, 0.237, 1], [2, 2, 1, 2, 2, 2, 0.481, 0.149, 1], [2, 2, 1, 1, 2, 1, 0.437, 0.211, 1], [2, 2, 2, 2, 2, 1, 0.666, 0.091, 0], [1, 3, 3, 1, 3, 2, 0.243, 0.267, 0], [3, 3, 3, 3, 3, 1, 0.245, 0.057, 0], [3, 1, 1, 3, 3, 2, 0.343, 0.099, 0], [1, 2, 1, 2, 1, 1, 0.639, 0.161, 0], [3, 2, 2, 2, 1, 1, 0.657, 0.198, 0], [2, 2, 1, 1, 2, 2, 0.360, 0.370, 0], [3, 1, 1, 3, 3, 1, 0.593, 0.042, 0], [1, 1, 2, 2, 2, 1, 0.719, 0.103, 0]]) m = len(D) # 資料歸一化 temp = D[:,:-1] D[:,:-1] = (temp-np.min(temp,axis=0)) / np.ptp(temp, axis=0) # 按照順序儲存各樣本的nh和nm近鄰 data = D[:,:-1] nh_set, nm_set = [],[] for i in range(m): data -= data[i,:] li = np.argsort(np.linalg.norm(data, axis=1)) for order in range(1,m): # li[0]代表其本身的id,因此索引應該從1開始 if D[li[order],-1] == D[i,-1]: nh_set.append(li[order]) break for order in range(1,m): # li[0]代表其本身的id,因此索引應該從1開始 if D[li[order],-1] != D[i,-1]: nm_set.append(li[order]) break # 計算相關統計量 n = len(label) score = [0]*n for attr in range(n-2): for i in range(m): if data[i, attr] != data[nh_set[i], attr]: score[attr] -= 1 if data[i, attr] != data[nm_set[i], attr]: score[attr] += 1 for attr in [-2,-1]: for i in range(m): a = 2*data[i, attr] - data[nh_set[i], attr] - data[nm_set[i], attr] b = data[nh_set[i], attr] - data[nm_set[i], attr] score[attr] += a*b # 由大到小輸出各個特徵 output = sorted([(label[i],k) for i,k in enumerate(score)], key=lambda li: -li[1]) print(output)
[('紋理', 11), ('根蒂', 4), ('含糖率', 1.7657963416588451), ('敲聲', 1),
('臍部', 0), ('密度', -0.60651295746574851), ('觸感', -2), ('色澤', -5)]