
Python點滴(三)—pandas資料分析與matplotlib畫圖
本篇博文主要介紹使用python中的matplotlib模組進行簡單畫圖功能,我們這裡畫出了一個柱形圖來對比兩位同學之間的不同成績,和使用pandas進行簡單的資料分析工作,主要包括開啟csv檔案讀取特定行列進行加減增加刪除操作,計算滑動均值,進行畫圖顯示等等;其中還包括一段關於ipython的基本使用指令,比較naive歡迎各位指正交流!
mlp.rc動態配置
你可以在python指令碼或者python互動式環境裡動態的改變預設rc配置。所有的rc配置變數稱為matplotlib.rcParams 使用字典格式儲存,它在matplotlib中是全域性可見的。rcParams可以直接修改,如:
import matplotlib as mpl
mpl.rcParams['lines.linewidth'] = 2
mpl.rcParams['lines.color'] = 'r'
Matplotlib還提供了一些便利函式來修改rc配置。matplotlib.rc()命令利用關鍵字引數來一次性修改一個屬性的多個設定:
import matplotlib as mpl
mpl.rc('lines', linewidth=2, color='r')
這裡matplotlib.rcdefaults()命令可以恢復為matplotlib標準預設配置。
在日常的資料統計分析的過程當中,大量的資料無法直觀的觀察出來,需要我們使用各種工具從不同角度側面分析資料之間的變化與差異,而畫圖無疑是一個比較有效的方法;下面我們將使用python中的畫圖工具包matplotlib.pyplot來畫一個柱形圖,通過一個小示例的形式熟悉瞭解一下mpl的基本使用:
ipython中程式執行結果:<span style="font-size:14px;">#!/usr/bin/env python # coding: utf-8 #from matplotlib import backends import matplotlib.pyplot as plt import matplotlib as mpl mpl.use('Agg') import numpy as np from PIL import Image import pylab custom_font = mpl.font_manager.FontProperties(fname='C:\\Anaconda\\Lib\\site-packages\\matplotlib\\mpl-data\\fonts\\ttf\\huawenxihei.ttf') # 必須配置中文字型,否則會顯示成方塊 # 所有希望圖表顯示的中文必須為unicode格式,為方便起見我們將字型檔案重新命名為拼音形式 custom_font表示自定義字型 font_size = 10 # 字型大小 fig_size = (8, 6) # 圖表大小 names = (u'小剛', u'小芳') # 姓名元組 subjects = (u'物理', u'化學', u'生物') # 學科元組 scores = ((65, 80, 72), (75, 90, 85)) # 成績元組 mpl.rcParams['font.size'] = font_size # 更改預設更新字型大小 mpl.rcParams['figure.figsize'] = fig_size # 修改預設更新圖表大小 bar_width = 0.35 # 設定柱形圖寬度 index = np.arange(len(scores[0])) # 繪製“小明”的成績 index表示柱形圖左邊x的座標 rects1 = plt.bar(index, scores[0], bar_width, color='#0072BC', label=names[0]) # 繪製“小紅”的成績 rects2 = plt.bar(index + bar_width, scores[1], bar_width, color='#ED1C24', label=names[1]) plt.xticks(index + bar_width, subjects, fontproperties=custom_font) # X軸標題 plt.ylim(ymax=100, ymin=0) # Y軸範圍 plt.title(u'彩虹班同學成績對比', fontproperties=custom_font) # 圖表標題 plt.legend(loc='upper center', bbox_to_anchor=(0.5, -0.03), fancybox=True, ncol=2, prop=custom_font) # 圖例顯示在圖表下方 似乎左就是右,右就是左,上就是下,下就是上,center就是center # bbox_to_anchor左下角的位置? ncol就是numbers of column預設為1 # 新增資料標籤 就是矩形上面的成績數字 def add_labels(rects): for rect in rects: height = rect.get_height() plt.text(rect.get_x() + rect.get_width() / 2, height, height, ha='center', va='bottom') # horizontalalignment='center' plt.text(x座標,y座標,text,位置) # 柱形圖邊緣用白色填充,為了更加清晰可分辨 rect.set_edgecolor('white') add_labels(rects1) add_labels(rects2) plt.savefig('scores_par.png') # 圖表輸出到本地 #pylab.imshow('scores_par.png') pylab.show('scores_par.png') # 並列印顯示圖片 </span>
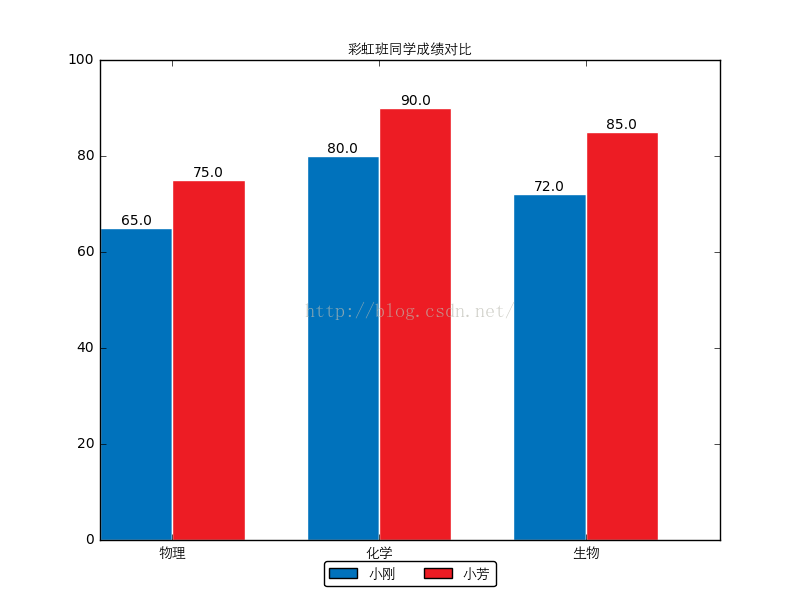
ipython:
run命令,
執行一個.py指令碼, 但是好處是, 與執行完了以後這個.py檔案裡的變數都可以在Ipython裡繼續訪問;
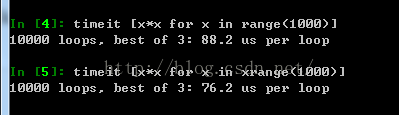
timeit命令,
可以用來做基準測試(benchmarking),
測試一個命令(或者一個函式)的執行時間,
debug命令: 當有exception異常的時候, 在console裡輸入debug即可開啟debugger,在debugger裡, 輸入u,d(up, down)檢視stack, 輸入q退出debugger;
$ipython
notebook會開啟瀏覽器,新建一個notebook,一個非常有意思的地方;
alt+Enter:
執行程式, 並自動在後面新建一個cell;
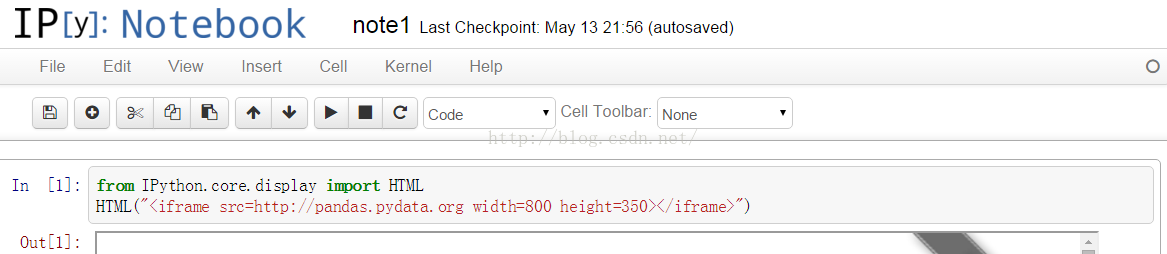
在notebook中是可以實現的
<span style="font-size:14px;">from IPython.core.display import HTML
HTML("<iframe src=http://pandas.pydata.org width=800 height=350></iframe>")</span>
<span style="font-size:14px;">import datetime
import pandas as pd
import pandas.io.data
from pandas import Series, DataFrame
pd.__version__</span><span style="font-size:14px;">
Out[2]:
'0.11.0'
In [3]:
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rc('figure', figsize=(8, 7)) # rc設定全域性畫圖引數
mpl.__version__</span><span style="font-size:14px;">
Out[3]:
'1.2.1'</span><span style="font-size:14px;">labels = ['a', 'b', 'c', 'd', 'e']
s = Series([1, 2, 3, 4, 5], index=labels)
s
Out[4]:
a 1
b 2
c 3
d 4
e 5
dtype: int64
In [5]:
'b' in s
Out[5]:
True
In [6]:
s['b']
Out[6]:
2
In [7]:
mapping = s.to_dict() # 對映為字典
mapping
Out[7]:
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
In [8]:
Series(mapping) # 對映為序列
Out[8]:
a 1
b 2
c 3
d 4
e 5
dtype: int64</span>pandas自帶練習例子資料,資料為金融資料;
aapl = pd.io.data.get_data_yahoo('AAPL', start=datetime.datetime(2006, 10, 1), end=datetime.datetime(2012, 1, 1)) aapl.head()Out[9]:
| Open | High | Low | Close | Volume | Adj Close | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2006-10-02 | 75.10 | 75.87 | 74.30 | 74.86 | 25451400 | 73.29 |
| 2006-10-03 | 74.45 | 74.95 | 73.19 | 74.08 | 28239600 | 72.52 |
| 2006-10-04 | 74.10 | 75.46 | 73.16 | 75.38 | 29610100 | 73.80 |
| 2006-10-05 | 74.53 | 76.16 | 74.13 | 74.83 | 24424400 | 73.26 |
| 2006-10-06 | 74.42 | 75.04 | 73.81 | 74.22 | 16677100 | 72.66 |
df = pd.read_csv('C:\\Anaconda\\Lib\\site-packages\\matplotlib\\mpl-data\\sample_data\\aapl_ohlc.csv', index_col='Date', parse_dates=True) df.head()Out[11]:
| Open | High | Low | Close | Volume | Adj Close | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2006-10-02 | 75.10 | 75.87 | 74.30 | 74.86 | 25451400 | 73.29 |
| 2006-10-03 | 74.45 | 74.95 | 73.19 | 74.08 | 28239600 | 72.52 |
| 2006-10-04 | 74.10 | 75.46 | 73.16 | 75.38 | 29610100 | 73.80 |
| 2006-10-05 | 74.53 | 76.16 | 74.13 | 74.83 | 24424400 | 73.26 |
| 2006-10-06 | 74.42 | 75.04 | 73.81 | 74.22 | 16677100 | 72.66 |
df.indexOut[12]:
<class 'pandas.tseries.index.DatetimeIndex'> [2006-10-02 00:00:00, ..., 2011-12-30 00:00:00] Length: 1323, Freq: None, Timezone: None
ts = df['Close'][-10:] #擷取'Close'列倒數十行 tsOut[13]:
Date 2011-12-16 381.02 2011-12-19 382.21 2011-12-20 395.95 2011-12-21 396.45 2011-12-22 398.55 2011-12-23 403.33 2011-12-27 406.53 2011-12-28 402.64 2011-12-29 405.12 2011-12-30 405.00 Name: Close, dtype: float64
df[['Open', 'Close']].head() #只要Open Close列Out[18]:
| Open | Close | |
|---|---|---|
| Date | ||
| 2006-10-02 | 75.10 | 74.86 |
| 2006-10-03 | 74.45 | 74.08 |
| 2006-10-04 | 74.10 | 75.38 |
| 2006-10-05 | 74.53 | 74.83 |
| 2006-10-06 | 74.42 | 74.22 |
New columns can be added on the fly.
In [19]:df['diff'] = df.Open - df.Close #新增新一列 df.head()Out[19]:
| Open | High | Low | Close | Volume | Adj Close | diff | |
|---|---|---|---|---|---|---|---|
| Date | |||||||
| 2006-10-02 | 75.10 | 75.87 | 74.30 | 74.86 | 25451400 | 73.29 | 0.24 |
| 2006-10-03 | 74.45 | 74.95 | 73.19 | 74.08 | 28239600 | 72.52 | 0.37 |
| 2006-10-04 | 74.10 | 75.46 | 73.16 | 75.38 | 29610100 | 73.80 | -1.28 |
| 2006-10-05 | 74.53 | 76.16 | 74.13 | 74.83 | 24424400 | 73.26 | -0.30 |
| 2006-10-06 | 74.42 | 75.04 | 73.81 | 74.22 | 16677100 | 72.66 | 0.20 |
...and deleted on the fly.
del df['diff'] df.head()
| Open | High | Low | Close | Volume | Adj Close | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2006-10-02 | 75.10 | 75.87 | 74.30 | 74.86 | 25451400 | 73.29 |
| 2006-10-03 | 74.45 | 74.95 | 73.19 | 74.08 | 28239600 | 72.52 |
| 2006-10-04 | 74.10 | 75.46 | 73.16 | 75.38 | 29610100 | 73.80 |
| 2006-10-05 | 74.53 | 76.16 | 74.13 | 74.83 | 24424400 | 73.26 |
| 2006-10-06 | 74.42 | 75.04 | 73.81 | 74.22 | 16677100 | 72.66 |
close_px = df['Adj Close']In [22]:
mavg = pd.rolling_mean(close_px, 40) #計算滑動均值並擷取顯示倒數十行 mavg[-10:]Out[22]:
Date 2011-12-16 380.53500 2011-12-19 380.27400 2011-12-20 380.03350 2011-12-21 380.00100 2011-12-22 379.95075 2011-12-23 379.91750 2011-12-27 379.95600 2011-12-28 379.90350 2011-12-29 380.11425 2011-12-30 380.30000 dtype: float64
close_px.plot(label='AAPL') mavg.plot(label='mavg') plt.legend() # 圖示
import pylab
pylab.show() # 顯示圖片Out[25]:
<matplotlib.legend.Legend at 0xa17cd8c>
df = pd.io.data.get_data_yahoo(['AAPL', 'GE', 'GOOG', 'IBM', 'KO', 'MSFT', 'PEP'], start=datetime.datetime(2010, 1, 1), end=datetime.datetime(2013, 1, 1))['Adj Close'] df.head()Out[26]:
| AAPL | GE | GOOG | IBM | KO | MSFT | PEP | |
|---|---|---|---|---|---|---|---|
| Date | |||||||
| 2010-01-04 | 209.51 | 13.81 | 626.75 | 124.58 | 25.77 | 28.29 | 55.08 |
| 2010-01-05 | 209.87 | 13.88 | 623.99 | 123.07 | 25.46 | 28.30 | 55.75 |
| 2010-01-06 | 206.53 | 13.81 | 608.26 | 122.27 | 25.45 | 28.12 | 55.19 |
| 2010-01-07 | 206.15 | 14.53 | 594.10 | 121.85 | 25.39 | 27.83 | 54.84 |
| 2010-01-08 | 207.52 | 14.84 | 602.02 | 123.07 | 24.92 | 28.02 | 54.66 |
rets = df.pct_change()In [28]:
plt.scatter(rets.PEP, rets.KO) # 畫散點圖 plt.xlabel('Returns PEP') plt.ylabel('Returns KO')
import pylab
pylab.show()
Out[28]:
<matplotlib.text.Text at 0xa1b5d8c>