
Spark-SparkSQL深入學習系列二(轉自OopsOutOfMemory)
Spark SQL的核心執行流程我們已經分析完畢,可以參見Spark SQL核心執行流程,下面我們來分析執行流程中各個核心元件的工作職責。
本文先從入口開始分析,即如何解析SQL文字生成邏輯計劃的,主要設計的核心元件式SqlParser是一個SQL語言的解析器,用scala實現的Parser將解析的結果封裝為Catalyst TreeNode ,關於Catalyst這個框架後續文章會介紹。
一、SQL Parser入口
Sql Parser 其實是封裝了scala.util.parsing.combinator下的諸多Parser,並結合Parser下的一些解析方法,構成了Catalyst的元件UnResolved Logical Plan。先來看流程圖:
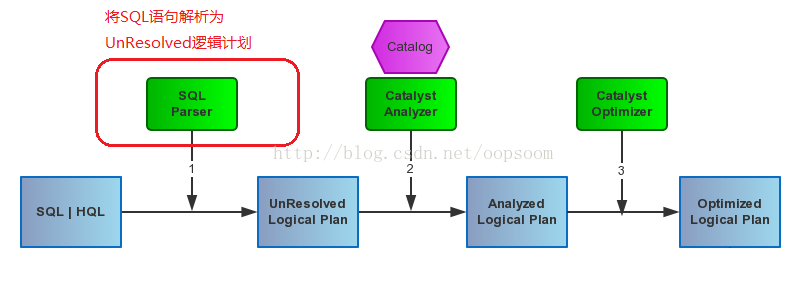
一段SQL會經過SQL Parser解析生成UnResolved Logical Plan(包含UnresolvedRelation、 UnresolvedFunction、 UnresolvedAttribute)。
在原始碼裡是:
- def sql(sqlText: String): SchemaRDD = new SchemaRDD(this, parseSql(sqlText))//sql("select name,value from temp_shengli") 例項化一個SchemaRDD
-
protected[sql] def parseSql(sql: String): LogicalPlan = parser(sql) //例項化SqlParser
- class SqlParser extends StandardTokenParsers with PackratParsers {
- def apply(input: String): LogicalPlan = { //傳入sql語句呼叫apply方法,input引數即sql語句
- // Special-case out set commands since the value fields can be
-
// complex to handle without RegexParsers. Also this approach
- // is clearer for the several possible cases of set commands.
- if (input.trim.toLowerCase.startsWith("set")) {
- input.trim.drop(3).split("=", 2).map(_.trim) match {
- case Array("") => // "set"
- SetCommand(None, None)
- case Array(key) => // "set key"
- SetCommand(Some(key), None)
- case Array(key, value) => // "set key=value"
- SetCommand(Some(key), Some(value))
- }
- } else {
- phrase(query)(new lexical.Scanner(input)) match {
- case Success(r, x) => r
- case x => sys.error(x.toString)
- }
- }
- }
1. 當我們呼叫sql("select name,value from temp_shengli")時,實際上是new了一個SchemaRDD
2. new SchemaRDD時,構造方法呼叫parseSql方法,parseSql方法例項化了一個SqlParser,這個Parser初始化呼叫其apply方法。
3. apply方法分支:
3.1 如果sql命令是set開頭的就呼叫SetCommand,這個類似Hive裡的引數設定,SetCommand其實是一個Catalyst裡TreeNode之LeafNode,也是繼承自LogicalPlan,關於Catalyst的TreeNode庫這個暫不詳細介紹,後面會有文章來詳細講解。
3.2 關鍵是else語句塊裡,才是SqlParser解析SQL的核心程式碼:
- phrase(query)(new lexical.Scanner(input)) match {
- case Success(r, x) => r
- case x => sys.error(x.toString)
- }
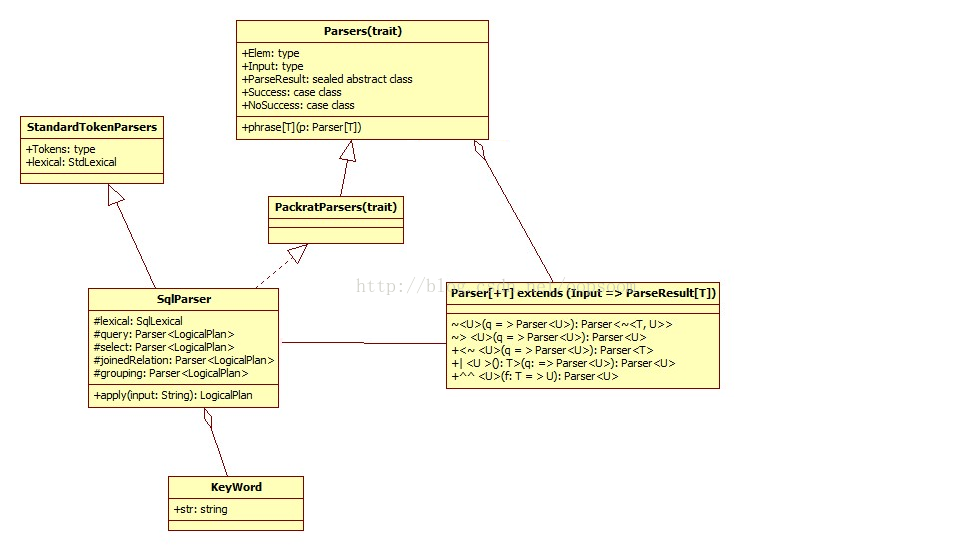
SqlParser類繼承了scala內建集合Parsers,這個Parsers。我們可以看到SqlParser現在是具有了分詞的功能,也能解析combiner的語句(類似p ~> q,後面會介紹)。
Phrase方法:
- /** A parser generator delimiting whole phrases (i.e. programs).
- *
- * `phrase(p)` succeeds if `p` succeeds and no input is left over after `p`.
- *
- * @param p the parser that must consume all input for the resulting parser
- * to succeed.
- * @return a parser that has the same result as `p`, but that only succeeds
- * if `p` consumed all the input.
- */
- def phrase[T](p: Parser[T]) = new Parser[T] {
- def apply(in: Input) = lastNoSuccessVar.withValue(None) {
- p(in) match {
- case s @ Success(out, in1) =>
- if (in1.atEnd)
- s
- else
- lastNoSuccessVar.value filterNot { _.next.pos < in1.pos } getOrElse Failure("end of input expected", in1)
- case ns => lastNoSuccessVar.value.getOrElse(ns)
- }
- }
- }
Phrase是一個迴圈讀取輸入字元的方法,如果輸入in沒有到達最後一個字元,就繼續對parser進行解析,直到最後一個輸入字元。
我們注意到Success這個類,出現在Parser裡, 在else塊裡最終返回的也有Success:
- /** The success case of `ParseResult`: contains the result and the remaining input.
- *
- * @param result The parser's output
- * @param next The parser's remaining input
- */
- caseclass Success[+T](result: T, override val next: Input) extends ParseResult[T] {
所以上面判斷了Success的解析結果中in1.atEnd? 如果輸入流結束了,就返回s,即Success物件,這個Success包含了SqlParser解析的輸出。
二、Sql Parser核心
在SqlParser裡phrase接受2個引數:
第一個是query,一種帶模式的解析規則,返回的是LogicalPlan。
第二個是lexical詞彙掃描輸入。
SqlParser parse的流程是,用lexical詞彙掃描接受SQL關鍵字,使用query模式來解析符合規則的SQL。
2.1 lexical keyword
在SqlParser裡定義了KeyWord這個類:- protectedcaseclass Keyword(str: String)
- protected val ALL = Keyword("ALL")
- protected val AND = Keyword("AND")
- protected val AS = Keyword("AS")
- protected val ASC = Keyword("ASC")
- protected val APPROXIMATE = Keyword("APPROXIMATE")
- protected val AVG = Keyword("AVG")
- protected val BY = Keyword("BY")
- protected val CACHE = Keyword("CACHE")
- protected val CAST = Keyword("CAST")
- protected val COUNT = Keyword("COUNT")
- protected val DESC = Keyword("DESC")
- protected val DISTINCT = Keyword("DISTINCT")
- protected val FALSE = Keyword("FALSE")
- protected val FIRST = Keyword("FIRST")
- protected val FROM = Keyword("FROM")
- protected val FULL = Keyword("FULL")
- protected val GROUP = Keyword("GROUP")
- protected val HAVING = Keyword("HAVING")
- protected val IF = Keyword("IF")
- protected val IN = Keyword("IN")
- protected val INNER = Keyword("INNER")
- protected val INSERT = Keyword("INSERT")
- protected val INTO = Keyword("INTO")
- protected val IS = Keyword("IS")
- protected val JOIN = Keyword("JOIN")
- protected val LEFT = Keyword("LEFT")
- protected val LIMIT = Keyword("LIMIT")
- protected val MAX = Keyword("MAX")
-
相關推薦
Spark-SparkSQL深入學習系列二(轉自OopsOutOfMemory)
Spark SQL的核心執行流程我們已經分析完畢,可以參見Spark SQL核心執行流程,下面我們來分析執行流程中各個核心元件的工作職責。 本文先從入口開始分析,即如何解析SQL文字生成邏輯計劃的,主要設計的核心元件式SqlParser是
Spark-SparkSQL深入學習系列七(轉自OopsOutOfMemory)
我們都知道一段sql,真正的執行是當你呼叫它的collect()方法才會執行Spark Job,最後計算得到RDD。 lazy val toRdd: RDD[Row] = executedPlan.execute() Spark Plan基本包含4種操作型別
Spark-SparkSQL深入學習系列九(轉自OopsOutOfMemory)
Spark SQL 可以將資料快取到記憶體中,我們可以見到的通過呼叫cache table tableName即可將一張表快取到記憶體中,來極大的提高查詢效率。 這就涉及到記憶體中的資料的儲存形式,我們知道基於關係型的資料可以儲存為基於行儲存結構 或 者基於列儲存結構,或者基於行和列的
Spark-SparkSQL深入學習系列十一(轉自OopsOutOfMemory)
上週Spark1.2剛釋出,週末在家沒事,把這個特性給瞭解一下,順便分析下原始碼,看一看這個特性是如何設計及實現的。 /** Spark SQL原始碼分析系列文章*/ 一、Sources包核心 Spark SQL在Spark1.2中提供了Exte
多線程學習系列二(使用System.Threading)
設定 進行 運行時 art lowest 模擬 state 執行 png 一、什麽是System.Threading.Thread?如何使用System.Threading.Thread進行異步操作 System.Threading.Thread:操作系統實現線程並提供各
Java學習路線圖[二](轉)
<br />一)、工具篇<br />一、 JDK (Java Development Kit) <br />JDK是整個Java的核心,包括了Java執行環境(Java Runtime
Maven學習筆記二(配置本地倉庫)
maven學習筆記 Maven的默認本地倉庫在: ${user.home}/.m2/repository; 如果需要自定義倉庫路徑,可以找到maven文件夾下的conf下的setting.xml文件進行修改, 以下自定義倉庫路徑為E:\java\Maven\apache-maven-3
python 學習筆記二 (列表推導式)
2018年年初寫了第一篇部落格,說要做一個認真的技術人 https://www.cnblogs.com/yingchen/p/8455507.html 今天已經是11月19日了,這是第二篇部落格,看來堅持確實是個好難的東西。雖然沒寫筆記,今年一年對python的使用還是可以的, 今天繼續:
SVN初學者學習使用文章(轉自文件)
方法/步驟 簽出原始碼到本機 在本機建立資料夾StartKit,右鍵點選Checkout,彈出如下圖的窗體: 在上圖中URL of Repository:下的文字框中輸入svn server中的程式碼庫的地址,其他預設,點選OK按鈕,就開始簽出原始碼了。 說明:上
資料庫系統實現學習筆記二(資料庫關係建模)--by穆晨
前言 ER建模環節完成後,需求就被描述成了ER圖。之後,便可根據這個ER圖設計相應的關係表了。 但從ER圖到具體關係表的建立還需要經過兩個步驟: 邏輯模型設計:將ER圖對映為邏輯意義上的
JUC學習系列八(訊號量 Semaphore)
一個計數訊號量。從概念上講,訊號量維護了一個許可集。Semaphore 通常用於限制可以訪問某些資源(物理或邏輯的)的執行緒數目。通常,應該將用於控制資源訪問的訊號量初始化為公平的,以確保所有執行緒都可訪問資源。為其他的種類的同步控制使用訊號量時,非公平排序的吞吐量優勢通常要
JUC學習系列十(非同步計算 FutureTask)
public interface Future<V> Future 表示非同步計算的結果。它提供了檢查計算是否完成的方法,以等待計算的完成,並獲取計算的結果。計算完成後只能使用 get 方法來獲取結果,如有必要,計算完成前可以阻塞此方法。取消則由 cancel 方
SVN 學習筆記二(一口氣學會SVN)
我打算一口氣講完SVN的使用,所以,在看之前呢,請先深深的吸一口氣(怎麼聽著像黑龍公主),當然吸完後還是要撥出來的。不要憋著了。 我們可能希望一來就直接操作。列出一堆命令。詳細的命令引數等資訊,我們都可以加入 --help 選項獲取,下面不會詳細介紹。除非必要。現在先看下
Fiddler抓包工具總結二(轉自小坦克)
修改用戶名 ins 結果 包含 tomat asp.net 優化 視頻教程 了解 -- 此文章是轉載小坦克的;直接復制文章的目的是因為原文章地址經常被重置,找不到原來的文章。小坦克博客園主頁:https://home.cnblogs.com/u/TankXiao/ 目錄
資料結構與算法系列二(複雜度分析)
1.引子 1.1.為什麼要學習資料結構與演算法? 有人說,資料結構與演算法,計算機網路,與作業系統都一樣,脫離日常開發,除了面試這輩子可能都用不到呀! 有人說,我是做業務開發的,只要熟練API,熟練框架,熟練各種中介軟體,寫的程式碼不也能“飛”起來嗎? 於是問題來了:為什麼還要學習資料結構與演算法呢?
HTTP狀態碼大全(轉自wiki)
成對 節點 而是 沒有 redirect port multiple 許可 sta 1xx消息 這一類型的狀態碼,代表請求已被接受,需要繼續處理。這類響應是臨時響應,只包含狀態行和某些可選的響應頭信息,並以空行結束。由於HTTP/1.0協議中沒有定義任何1xx狀態碼,所以除
RPG遊戲設計(轉自Gameres)
工作量 我們 初始化 共享 世人 生命 置疑 年輕 動作 目錄: 第一章 概述 第二章 場景 第三章 角色 第四章 道具 第五章 事件 第六章 對白 第七章 語音和音效 第八章 音樂 第九章 界面 第十章 規則 第十一章 命名第一章:概述RPG遊戲即
ubuntu中安裝meld工具-(轉自sukhoi27smk)
插件 edit ges -s election load nbsp 輸入 eight Ubuntu下文件/目錄對比的軟件Meld可能有很多用戶還不是很熟悉,下文就給大家介紹如何安裝Meld和移植到Gedit下。具體內容如下所述。 Meld允許用戶查看文件、目錄間的變化。很容
ASP.NET Core 中的 WebSocket 支持(轉自MSDN)
ocs 接收 緩沖 任務 ica uget 本地服務器 tcp msdn 本文介紹 ASP.NET Core 中 WebSocket 的入門方法。 WebSocket (RFC 6455) 是一個協議,支持通過 TCP 連接建立持久的雙向信道。 它用於從快速實時通信中獲益的
EF Core中DeleteBehavior的介紹(轉自MSDN)
then defined nec div values tomat ack practice blank Delete behaviors Delete behaviors are defined in the DeleteBehavior enumerator type