
機器學習中的類別不平衡問題
類別不平衡問題指分類任務中不同類別的訓練樣本數目差別很大的情況。
下面介紹幾種緩解類別不平衡的方法:
1、欠取樣
即去除多餘的樣本,使得正負樣本數目基本一致。
注意:(1)由於丟棄了一些樣本,訓練速度相對加快了。
(2)但是簡單的隨機丟失樣本,會造成資訊丟失。欠取樣的代表演算法是EasyEnsemble,是利用整合學習機制,將數目多的一類劃分成若干個集合供不同學習器使用,這樣雖然對每個學習器丟失了一部分資訊,但全域性上看不會丟失重要資訊。
2、過取樣
即增加少的一類的樣本數目,使得正負樣本數目基本一致。
注意:(1)由於多了一些樣本,訓練速度相對減慢了。
(2)但是簡單的重取樣會帶來嚴重的過擬合,過取樣的代表性演算法是SMOTE,是通過對少的一類進行插值得到額外的樣本。
3、閾值移動
閾值移動主要是用到“再縮放”的思想,以線性模型為例介紹“再縮放”。
我們把大於0.5判為正類,小於0.5判為負類,即

即令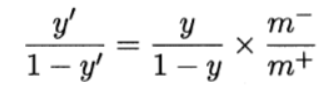 然後代入上上式。這就是“再縮放”。
然後代入上上式。這就是“再縮放”。
閾值移動方法是使用原始訓練集訓練好分類器,而在預測時加入再縮放的思想,用來緩解類別不平衡的方法。
相關推薦
[轉]如何處理機器學習中的不平衡類別
down 觀測 input 推薦 可能 type 兩個 好的 exchange 如何處理機器學習中的不平衡類別 原文地址:How to Handle Imbalanced Classes in Machine Learning 原文作者:elitedatascienc
機器學習中樣本不平衡處理辦法
在機器學習任務中,我們經常會遇到這種困擾:資料不平衡問題。比如在廣告點選預估、反欺詐、風控裡面。 資料不平衡問題主要存在於有監督機器學習任務中。當遇到不平衡資料時,以總體分類準確率為學習目標的傳統分類演算法會過多地關注多數類,從而使得少數類樣本的分類效能下降。絕大
【機器學習】類別不平衡學習
本文主要記錄 《機器學習》一書中關於類別不平衡問題的處理。 類別不平衡問題(class-imbalance)就是說對於分類任務來說,不同類別的訓練樣例相差很大的情況。不是一般性,這裡主要介紹負樣本遠遠多於正樣本的情況。(在閱讀深度神經網路論文時,發現這種情
機器學習之類別不平衡問題 (2) —— ROC和PR曲線
完整程式碼 ROC曲線和PR(Precision - Recall)曲線皆為類別不平衡問題中常用的評估方法,二者既有相同也有不同點。本篇文章先給出ROC曲線的概述、實現方法、優缺點,再闡述PR曲線的各項特點,最後給出兩種方法各自的使用場景。 R
從重取樣到資料合成:如何處理機器學習中的不平衡分類問題?
轉自:http://www.sohu.com/a/129333346_465975 選自Analytics Vidhya 作者:Upasana Mukherjee 機器之心編譯 參與:馬亞雄、微胖、黃小天、吳攀 如果你研究過一點機器學習和資料科學,你肯定遇到過不平衡的類分
機器學習之類別不平衡問題 (1) —— 各種評估指標
機器學習之類別不平衡問題 (1) —— 各種評估指標 機器學習之類別不平衡問題 (2) —— ROC和PR曲線 在二分類問題中,通常假設正負類別相對均衡,然而實際應用中類別不平衡的問題,如100, 1000, 10000倍的資料偏斜是非常常見的,比如疾病
如何解決機器學習中資料不平衡問題
這幾年來,機器學習和資料探勘非常火熱,它們逐漸為世界帶來實際價值。與此同時,越來越多的機器學習演算法從學術界走向工業界,而在這個過程中會有很多困難。資料不平衡問題雖然不是最難的,但絕對是最重要的問題之一。 一、資料不平衡 在學術研究與教學中,很多演算法都有一個基本假設,那
機器學習中對不均衡數據的處理方法
9.png ima 方法 nbsp 修改 情況 技術分享 其他 它的 當對於a類型數據占10% b類型的數據占90% 這中數據不均衡的情況采用的方法有: 1.想辦法獲取更多數據 2.換一種評判方式 3.重組數據: a.復制 a的數據,使它的數據量和b一樣多。
機器學習之樣本不平衡
機器學習之樣本不平衡 1.樣本不平衡導致什麼問題? 在機器學習的分類問題中,以二分類為例,如果訓練集合的正例和負例的樣本不平衡,相差懸殊很大。比如針對這個不平衡的訓練結合運用邏輯迴歸的時候,一般來說,邏輯迴歸的閾值0~1,常取0.5,當樣本不平衡時,採用預設的分類閾值可能會導致輸出全
系統學習機器學習之樣本不平衡問題處理
原文連結:http://blog.csdn.net/heyongluoyao8/article/details/49408131 在分類中如何處理訓練集中不平衡問題 在很多機器學習任務中,訓練集中可能會存在某個或某些類別下的樣本數遠大於另一些類別下的樣本數目。即類別不平衡,為了使得學習達
「機器學習」資料不平衡情況下的處理方法(1)
1. background 前端時間想換工作,於是面了幾家公司。發現了公司面試基本會問當資料集分佈不平衡的時候該怎麼處理。在現實做專案的時候這種情況也會很多。於是做了一下整理。2. 資料不平衡 資料不平衡的情況主要出現在二分類。比如現在公司做的重要郵件檢測。幾千個郵
機器不學習:如何處理資料中的「類別不平衡」?
轉自: 機器學習中常常會遇到資料的類別不平衡(class imbalance),也叫資料偏斜(class skew)。以常見的二分類問題為例,我們希望預測病人是否得了某種罕見疾病。但在歷史資料中,陽性的比例可能很低(如百分之0.1)。在這種情況下,學習出好的分類器是
機器學習中的類別不平衡問題
類別不平衡問題指分類任務中不同類別的訓練樣本數目差別很大的情況。 下面介紹幾種緩解類別不平衡的方法: 1、欠取樣 即去除多餘的樣本,使得正負樣本數目基本一致。 注意:(1)由於丟棄了一些樣本,訓練速度相對加快了。 &n
機器學習-類別不平衡問題
之前 size 訓練 最近鄰 機制 每次 問題 線性 大於 引言:我們假設有這種情況,訓練數據有反例998個,正例2個,模型是一個永遠將新樣本預測為反例的學習器,就能達到99.8%的精度,這樣顯然是不合理的。 類別不平衡:分類任務中不同類別的訓練樣例數差別很大。
機器學習中不平衡資料的處理方式
https://blog.csdn.net/pipisorry/article/details/78091626 不平衡資料的場景出現在網際網路應用的方方面面,如搜尋引擎的點選預測(點選的網頁往往佔據很小的比例),電子商務領域的商品推薦(推薦的商品被購買的比例很低),信用卡欺詐檢測,網路攻擊識別
8種應對機器學習資料集類別不平衡的策略
資料集類別不平衡通常發生在分類問題上,例如有兩個類別(A,B)的資料集,A有80個,而B有20個,那麼這個資料集是不平衡的。大多數資料集每一個類別通常不是完全的平衡,小的不平衡不會有太大的問題。但是當樣本分佈差距很大的時候,就會有很大的影響。嚴重的不平衡會導致訓練的模型大概率
[機器學習] 機器學習中訓練資料不平衡問題處理方案彙總
在很多機器學習任務中,訓練集中可能會存在某個或某些類別下的樣本數遠大於另一些類別下的樣本數目。即類別不平衡,為了使得學習達到更好的效果,因此需要解決該類別不平衡問題。原文標題:8 Tactics to Combat Imbalanced Classes in Your Mac
分類任務中資料類別不平衡問題的幾種解決方案
類別不平衡(class-imbalance),是指分類任務中不同類別的訓練樣例數目差別很大的情況(例如,訓練集正類樣例10個,反類樣例90個),本文假設正類樣例較少,反類樣例較多。 現有解決方案大體分為三類,如下文所示。 欠取樣(undersampling) 欠取樣方法,即去除一
分類中解決類別不平衡問題
關注微信公眾號【Microstrong】,我現在研究方向是機器學習、深度學習,分享我在學習過程中的讀書筆記!一起來學習,一起來交流,一起來進步吧!1.什麼是類別不平衡問題 如果不同類別的訓練樣例數目稍有差別,通常影響不大,但若差別很大,則會對學習過程造成困擾。例如有998個
機器學習中訓練樣本不均衡問題
在實際中,訓練模型用的資料並不是均衡的,在一個多分類問題中,每一類的訓練樣本並不是一樣的,反而是差距很大。比如一類10000,一類500,一類2000等。解決這個問題的做法主要有以下幾種: 欠取樣:就是把多餘的樣本去掉,保持這幾類樣本接近,在進行學習。(可能會導致過擬合)