
特徵的處理
阿新 • • 發佈:2019-01-05
1、首先要進行特徵的選擇,特徵的選擇需要基於一定的背景知識
X = titanic[['age','pclass','sex']]
y=titanic['survived']
選擇結束可以使用info()進行探查
2、有些特徵缺失,我們需要將其補充完整
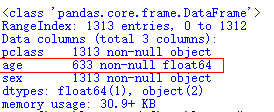
如果該特徵是數值型 eg:age特徵 可使用平均值或中位值,該策略是對模型造成影響最小的
X['age'] .fillna( X['age'].mean() , inplace=True )
X.info() #再次檢視
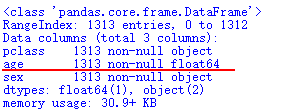
3、有一些資料列的值都是類別型的,需要轉化為數值特徵,用0/1代替
from sklearn.feature_extraction import DictVectorizer
#使用scikit-sklearn.feature_extraction 中的特徵轉換器
vec = DictVectorizer(sparse=False) #sparse稀疏
X_train = vec.fit_transform( X_train.to_dict(orient='record') )
print(vec.feature_names_) #通過檢視轉換特徵後的結果我們發現凡是類別型的特徵都單獨剝離出來,獨成一列特徵,數值型不變
如下圖:
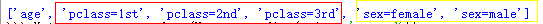
完成了特徵的處理,可以繼續下一步啦!