
Hadoop2.6.0的FileInputFormat的任務切分原理分析(即如何控制FileInputFormat的map任務數量)
前言
首先確保已經搭建好Hadoop叢集環境,可以參考《Linux下Hadoop叢集環境的搭建》一文的內容。我在測試mapreduce任務時,發現相比於使用Job.setNumReduceTasks(int)控制reduce任務數量而言,控制map任務數量一直是一個困擾我的問題。好在經過很多摸索與實驗,終於梳理出來,希望對在工作中進行Hadoop進行效能調優的新人們有個借鑑。本文只針對FileInputFormat的任務劃分進行分析,其它型別的InputFormat的劃分方式又各有不同。雖然如此,都可以按照本文類似的方法進行分析和總結。
為了簡便起見,本文以Hadoop2.6.0自帶的word count例子為例,進行展開。
wordcount
我們首先準備好wordcount所需的資料,一共有兩份檔案,都位於hdfs的/wordcount/input目錄下:

這兩個檔案的內容分別為:
On the top of the Crumpretty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.But his face you could not see,
On account of his Beaver Hat.現在我們不作任何效能優化(不增加任何配置引數),然後執行hadoop-mapreduce-examples子專案(有關此專案介紹,可以閱讀《
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /wordcount/input /wordcount/output/result1當然也可以使用樸素的方式執行wordcount例子:
hadoop org.apache.hadoop.examples.WordCount -D mapreduce.input.fileinputformat.split.maxsize=1 /wordcount/input /wordcount/output/result1
最後執行的結果在hdfs的/wordcount/output/result1目錄下:

執行結果可以檢視/wordcount/output/result1/part-r-00000的內容:
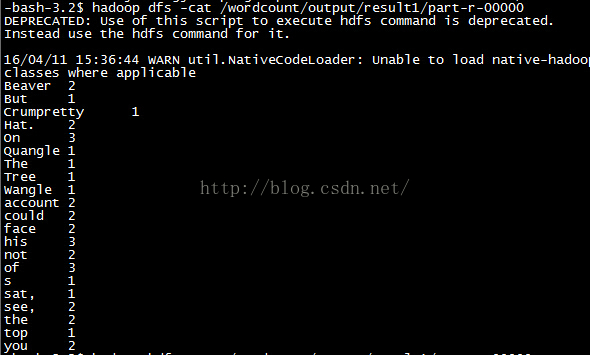
第一次優化
wordcount例子,檢視執行結果不是本文的目的。在執行wordcount例子時,在任務執行資訊中可以看到建立的map及reduce任務的數量:

可以看到FileInputFormat的輸入檔案有2個,JobSubmitter任務劃分的數量是2,最後產生的map任務數量也是2,看到這我們可以猜想由於我們提供了兩個輸入檔案,所以會有2個map任務。我們此處姑且不論這種猜測正確與否,現在我們打算改變map任務的數量。通過檢視文件,很多人知道使用mapreduce.job.maps引數可以快速修改map任務的數量,事實果真如此?讓我們先來實驗一番,輸入以下命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount -D mapreduce.job.maps=1 /wordcount/input /wordcount/output/result2第二次優化
用mapreduce.job.maps調整map任務數量沒有見效,我們翻翻文件,發現還有mapreduce.input.fileinputformat.split.minsize引數,它可以控制map任務輸入劃分的最小位元組數。這個引數和mapreduce.input.fileinputformat.split.maxsize通常配合使用,後者控制map任務輸入劃分的最大位元組數。我們目前只調整mapreduce.input.fileinputformat.split.minsize的大小,劃分最小的尺寸變小是否預示著任務劃分數量變多?來看看會發生什麼?輸入以下命令:hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount -D mapreduce.input.fileinputformat.split.minsize=1 /wordcount/input /wordcount/output/result3hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount -D mapreduce.input.fileinputformat.split.maxsize=1 /wordcount/input /wordcount/output/result4

呵呵,任務劃分成了177個,想想也是,我們把最大的劃分位元組數僅僅設定為1位元組。接著往下看確實執行了177個map任務:

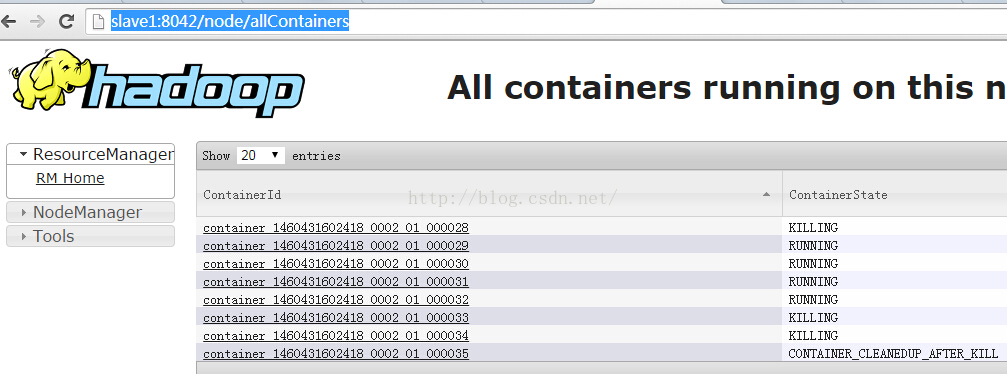
我們還可以通過Web UI觀察map任務所分配的Container。首先檢視Slave1節點上分配的Container情況:
再來看看Slave2節點上分配的Container情況:
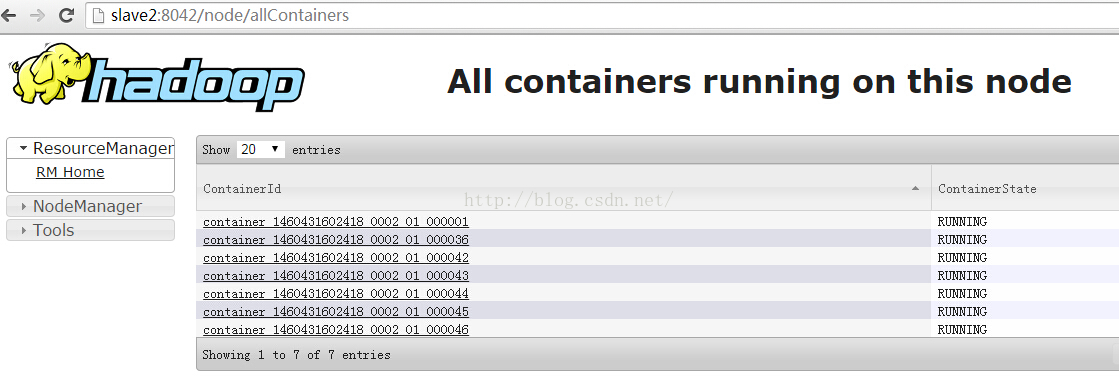
確實說明最多有15個Container分配給當前作業執行map任務。由於在YARN中yarn.nodemanager.resource.cpu-vcores引數的預設值是8,所以Slave1和Slave2兩臺機器上的虛擬cpu總數是16,由於ResourceManager會為mapreduce任務分配一個Container給ApplicationMaster(即MrAppMaster),所以整個叢集只剩餘了15個Container用於ApplicationMaster向NodeManager申請和執行map任務。
第三次優化
閱讀文件我們知道dfs.blocksize可以控制塊的大小,看看這個引數能否發揮作用。為便於測試,我們首先需要修改hdfs-site.xml中dfs.blocksize的大小為10m(最小就只能這麼小,Hadoop限制了引數單位至少是10m)。
<property>
<name>dfs.blocksize</name>
<value>10m</value>
</property>hadoop dfsadmin -refreshNodes
yarn rmadmin -refreshNodes我們使用以下命令檢視下系統內的檔案所佔用的blocksize大小:
hadoop dfs -stat "%b %n %o %r %y" /wordcount/input/quangle*
可以看到雖然quangle.txt和quangle2.txt的位元組數分別是121位元組和56位元組,但是在hdfs中這兩個檔案的blockSize已經是10m了。現在我們試試以下命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /wordcount/input /wordcount/output/result5原始碼分析
經過以上3次不同實驗,發現只有mapreduce.input.fileinputformat.split.maxsize引數確實影響了map任務的數量。現在我們通過原始碼分析,來一探究竟吧。
首先我們看看WordCount例子的原始碼,其中和任務劃分有關的程式碼如下:
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1); public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();
}
// 省略本文不關心的程式碼
return isSuccessful();
} public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
// 省略本文不關心的程式碼</span>
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}submit方法首先建立了JobSubmitter例項,然後非同步呼叫了JobSubmitter的submitJobInternal方法。JobSubmitter的submitJobInternal方法有關劃分任務的程式碼如下:
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps); private int writeSplits(org.apache.hadoop.mapreduce.JobContext job,
Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
JobConf jConf = (JobConf)job.getConfiguration();
int maps;
if (jConf.getUseNewMapper()) {
maps = writeNewSplits(job, jobSubmitDir);
} else {
maps = writeOldSplits(jConf, jobSubmitDir);
}
return maps;
}由於WordCount使用的是新的mapreduce API,所以最終會呼叫writeNewSplits方法。writeNewSplits的實現如下:
private <T extends InputSplit>
int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
Configuration conf = job.getConfiguration();
InputFormat<?, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
List<InputSplit> splits = input.getSplits(job);
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);
// sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator());
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);
return array.length;
}writeNewSplits方法中,劃分任務數量最關鍵的程式碼即為InputFormat的getSplits方法(提示:大家可以直接通過此處的呼叫,檢視不同InputFormat的劃分任務實現)。根據前面的分析我們知道此時的InputFormat即為FileOutputFormat,其getSplits方法的實現如下:
public List<InputSplit> getSplits(JobContext job) throws IOException {
Stopwatch sw = new Stopwatch().start();
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.elapsedMillis());
}
return splits;
}getFormatMinSplitSize方法固定返回1,getMinSplitSize方法實際就是mapreduce.input.fileinputformat.split.minsize引數的值(預設為1),那麼變數minSize的大小為mapreduce.input.fileinputformat.split.minsize與1之間的最大值。
getMaxSplitSize方法實際是mapreduce.input.fileinputformat.split.maxsize引數的值,那麼maxSize即為mapreduce.input.fileinputformat.split.maxsize引數的值。
由於我的試驗中有兩個輸入原始檔,所以List<FileStatus> files = listStatus(job);方法返回的files列表的大小為2。
在遍歷files列表的過程中,會獲取每個檔案的blockSize,最終呼叫computeSplitSize方法計算每個輸入檔案應當劃分的任務數。computeSplitSize方法的實現如下:
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}map任務要劃分的大小(splitSize )=(maxSize與blockSize之間的最小值)與minSize之間的最大值
bytesRemaining 是單個輸入原始檔未劃分的位元組數
根據getSplits方法,我們知道map任務劃分的數量=輸入原始檔數目 * (bytesRemaining / splitSize個劃分任務+bytesRemaining不能被splitSize 整除的剩餘大小單獨劃分一個任務 )
總結
根據原始碼分析得到的計算方法和之前的優化結果,我們最後總結一下:
對於第一次優化,由於FileOutputFormat壓根沒有采用mapreduce.job.maps引數指定的值,所以它當然不會有任何作用。
對於第二次優化,minSize幾乎由mapreduce.input.fileinputformat.split.minsize控制;mapreduce.input.fileinputformat.split.maxsize預設的大小是Long.MAX_VALUE,所以blockSize即為maxSize與blockSize之間的最小值;blockSize的預設大小是128m,所以blockSize與值為1的mapreduce.input.fileinputformat.split.minsize之間的最大值為blockSize,即map任務要劃分的大小的大小與blockSize相同。
對於第三次優化,雖然我們將blockSize設定為10m(最小也只能這麼小了,hdfs對於block大小的最低限制),根據以上公式maxSize與blockSize之間的最小值必然是blockSize,而blockSize與minSize之間的最大值也必然是blockSize。說明blockSize實際上已經發揮了作用,它決定了splitSize的大小就是blockSize。由於blockSize大於bytesRemaining,所以並沒有對map任務數量產生影響。
針對以上分析,我們用更加容易理解的方式列出這些配置引數的關係:
- 當mapreduce.input.fileinputformat.split.maxsize > mapreduce.input.fileinputformat.split.minsize > dfs.blockSize的情況下,此時的splitSize 將由mapreduce.input.fileinputformat.split.minsize引數決定。
- 當mapreduce.input.fileinputformat.split.maxsize > dfs.blockSize > mapreduce.input.fileinputformat.split.minsize的情況下,此時的splitSize 將由dfs.blockSize配置決定。(第二次優化符合此種情況)
- 當dfs.blockSize > mapreduce.input.fileinputformat.split.maxsize > mapreduce.input.fileinputformat.split.minsize的情況下,此時的splitSize 將由mapreduce.input.fileinputformat.split.maxsize引數決定。
鳴謝
我在試驗的過程中,遇到很多問題。但是很多問題在網路上都能找到,特此感謝在網際網路上分享經驗的同仁們。
後記:個人總結整理的《深入理解Spark:核心思想與原始碼分析》一書現在已經正式出版上市,目前京東、噹噹、天貓等網站均有銷售,歡迎感興趣的同學購買。
