
OpenCV實踐之路——人臉識別之二模型訓練
本文由@星沉閣冰不語出品,轉載請註明作者和出處。
在之前的部落格人臉識別之一資料收集和預處理之中,已經下載了ORL人臉資料庫,並且為了識別自己的人臉寫了一個拍照程式自拍。之後對拍的照片進行人臉識別和提取,最後我們得到了一個包含自己的人臉照片的資料夾s41。在部落格的最後我們提到了一個非常重要的檔案——at.txt。
一、csv檔案的生成
當我們寫人臉模型的訓練程式的時候,我們需要讀取人臉和人臉對應的標籤。直接在資料庫中讀取顯然是低效的。所以我們用csv檔案讀取。csv檔案中包含兩方面的內容,一是每一張圖片的位置所在,二是每一個人臉對應的標籤,就是為每一個人編號。這個at.txt就是我們需要的csv檔案。生成之後它裡面是這個樣子的:
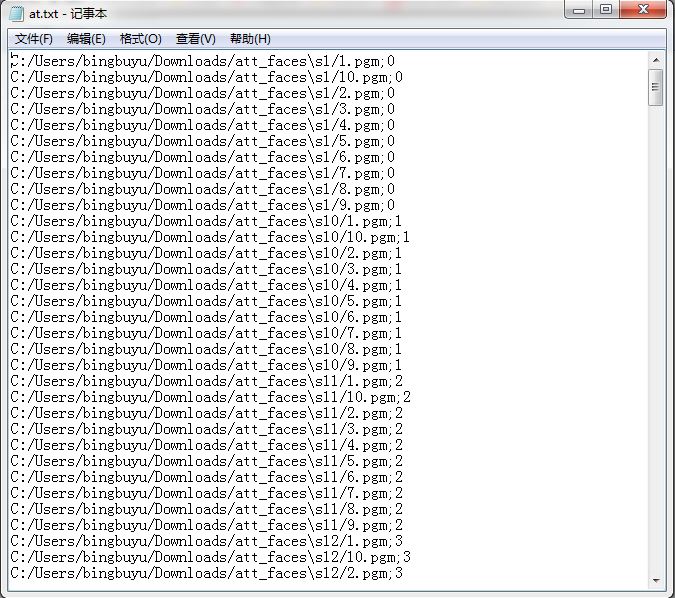
前面是圖片的位置,後面是圖片所屬人臉的人的標籤。
要生成這樣一個檔案直接用手工的方式一個一個輸入顯然不可取的,畢竟這裡有400多張圖片。而且這種重複性的工作估計也沒人想去做。所以我們可以用命令列的方式簡化工作量;或者用opencv自帶的Python指令碼來自動生成。
命令列方式是這樣的。比如我的資料集在C:\Users\bingbuyu\Downloads\att_faces資料夾下面,我就用下面兩行命令:
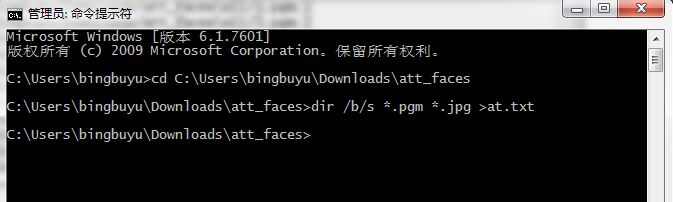
然後資料集資料夾下面就多出了一個at.txt檔案,但是現在是隻有路徑沒有標籤的。像下面這樣:
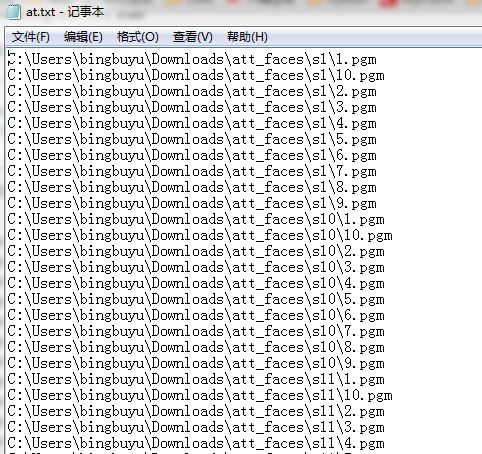
標籤需要手動敲上去。。。也挺麻煩的。
好在opencv教程裡面為我們提供了自動生成csv檔案的指令碼。路徑類似這樣:F:\opencv\sources\modules\contrib\doc\facerec\src\create_csv.py。我不知道怎麼用命令列引數的形式執行Python指令碼,所以只能把程式碼裡面的BASE_PATH手動的改成自己的資料集路徑,改完大致是這樣:
#!/usr/bin/env python import sys import os.path # This is a tiny script to help you creating a CSV file from a face # database with a similar hierarchie: # # [email protected]:~/facerec/data/at$ tree # . # |-- README # |-- s1 # | |-- 1.pgm # | |-- ... # | |-- 10.pgm # |-- s2 # | |-- 1.pgm # | |-- ... # | |-- 10.pgm # ... # |-- s40 # | |-- 1.pgm # | |-- ... # | |-- 10.pgm # if __name__ == "__main__": #if len(sys.argv) != 2: # print "usage: create_csv <base_path>" # sys.exit(1) #BASE_PATH=sys.argv[1] BASE_PATH="C:/Users/bingbuyu/Downloads/att_faces" SEPARATOR=";" fh = open("../etc/at.txt",'w') label = 0 for dirname, dirnames, filenames in os.walk(BASE_PATH): for subdirname in dirnames: subject_path = os.path.join(dirname, subdirname) for filename in os.listdir(subject_path): abs_path = "%s/%s" % (subject_path, filename) print "%s%s%d" % (abs_path, SEPARATOR, label) fh.write(abs_path) fh.write(SEPARATOR) fh.write(str(label)) fh.write("\n") label = label + 1 fh.close()
然後執行這個指令碼就可以生成一個既有路徑又有標籤的at.txt了。
二、訓練模型
現在資料集、csv檔案都已經準備好了。接下來要做的就是訓練模型了。
這裡我們用到了opencv的Facerecognizer類。opencv中所有的人臉識別模型都是來源於這個類,這個類為所有人臉識別演算法提供了一種通用的介面。文件裡的一個小段包含了我們接下來要用到的幾個函式:

OpenCV 自帶了三個人臉識別演算法:Eigenfaces,Fisherfaces 和區域性二值模式直方圖 (LBPH)。這裡先不去深究這些演算法的具體內容,直接用就是了。如果有興趣可以去看相關論文。接下來就分別訓練這三種人臉模型。這個時候就能體現出Facerecognizer類的強大了。因為每一種模型的訓練只需要三行程式碼:
Ptr<FaceRecognizer> model = createEigenFaceRecognizer();
model->train(images, labels);
model->save("MyFacePCAModel.xml");
Ptr<FaceRecognizer> model1 = createFisherFaceRecognizer();
model1->train(images, labels);
model1->save("MyFaceFisherModel.xml");
Ptr<FaceRecognizer> model2 = createLBPHFaceRecognizer();
model2->train(images, labels);
model2->save("MyFaceLBPHModel.xml");當然在這之前要先把之前圖片和標籤提取出來。這時候就是at.txt派上用場的時候了。
//使用CSV檔案去讀影象和標籤,主要使用stringstream和getline方法
static void read_csv(const string& filename, vector<Mat>& images, vector<int>& labels, char separator = ';') {
std::ifstream file(filename.c_str(), ifstream::in);
if (!file) {
string error_message = "No valid input file was given, please check the given filename.";
CV_Error(CV_StsBadArg, error_message);
}
string line, path, classlabel;
while (getline(file, line)) {
stringstream liness(line);
getline(liness, path, separator);
getline(liness, classlabel);
if (!path.empty() && !classlabel.empty()) {
images.push_back(imread(path, 0));
labels.push_back(atoi(classlabel.c_str()));
}
}
}在模型訓練好之後我們拿資料集中的最後一張圖片做一個測試,看看結果如何。
Mat testSample = images[images.size() - 1];
int testLabel = labels[labels.size() - 1];
<span style="white-space:pre"> </span>//。。。。這裡省略部分程式碼。。。。。。。。
// 下面對測試影象進行預測,predictedLabel是預測標籤結果
int predictedLabel = model->predict(testSample);
int predictedLabel1 = model1->predict(testSample);
int predictedLabel2 = model2->predict(testSample);
// 還有一種呼叫方式,可以獲取結果同時得到閾值:
// int predictedLabel = -1;
// double confidence = 0.0;
// model->predict(testSample, predictedLabel, confidence);
string result_message = format("Predicted class = %d / Actual class = %d.", predictedLabel, testLabel);
string result_message1 = format("Predicted class = %d / Actual class = %d.", predictedLabel1, testLabel);
string result_message2 = format("Predicted class = %d / Actual class = %d.", predictedLabel2, testLabel);
cout << result_message << endl;
cout << result_message1 << endl;
cout << result_message2 << endl;由於本來的資料集中是40個人,加上自己的人臉集就是41個。標籤是從0開始標的,所以在這裡我是第40個人。也即是說Actual class應該40。Predicted class也應該是40才說明預測準確。這裡我們可以看到結果:
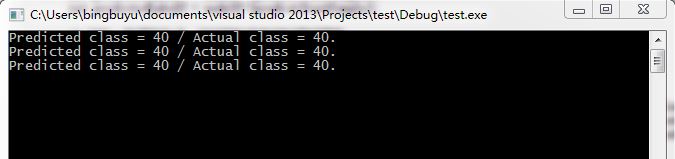
結果正確。
模型訓練的全部程式碼:
//#include "stdafx.h"
#include <opencv2/opencv.hpp>
#include <iostream>
#include <fstream>
#include <sstream>
#include <math.h>
using namespace cv;
using namespace std;
static Mat norm_0_255(InputArray _src) {
Mat src = _src.getMat();
// 建立和返回一個歸一化後的影象矩陣:
Mat dst;
switch (src.channels()) {
case1:
cv::normalize(_src, dst, 0, 255, NORM_MINMAX, CV_8UC1);
break;
case3:
cv::normalize(_src, dst, 0, 255, NORM_MINMAX, CV_8UC3);
break;
default:
src.copyTo(dst);
break;
}
return dst;
}
//使用CSV檔案去讀影象和標籤,主要使用stringstream和getline方法
static void read_csv(const string& filename, vector<Mat>& images, vector<int>& labels, char separator = ';') {
std::ifstream file(filename.c_str(), ifstream::in);
if (!file) {
string error_message = "No valid input file was given, please check the given filename.";
CV_Error(CV_StsBadArg, error_message);
}
string line, path, classlabel;
while (getline(file, line)) {
stringstream liness(line);
getline(liness, path, separator);
getline(liness, classlabel);
if (!path.empty() && !classlabel.empty()) {
images.push_back(imread(path, 0));
labels.push_back(atoi(classlabel.c_str()));
}
}
}
int main()
{
//讀取你的CSV檔案路徑.
//string fn_csv = string(argv[1]);
string fn_csv = "at.txt";
// 2個容器來存放影象資料和對應的標籤
vector<Mat> images;
vector<int> labels;
// 讀取資料. 如果檔案不合法就會出錯
// 輸入的檔名已經有了.
try
{
read_csv(fn_csv, images, labels);
}
catch (cv::Exception& e)
{
cerr << "Error opening file \"" << fn_csv << "\". Reason: " << e.msg << endl;
// 檔案有問題,我們啥也做不了了,退出了
exit(1);
}
// 如果沒有讀取到足夠圖片,也退出.
if (images.size() <= 1) {
string error_message = "This demo needs at least 2 images to work. Please add more images to your data set!";
CV_Error(CV_StsError, error_message);
}
// 下面的幾行程式碼僅僅是從你的資料集中移除最後一張圖片
//[gm:自然這裡需要根據自己的需要修改,他這裡簡化了很多問題]
Mat testSample = images[images.size() - 1];
int testLabel = labels[labels.size() - 1];
images.pop_back();
labels.pop_back();
// 下面幾行建立了一個特徵臉模型用於人臉識別,
// 通過CSV檔案讀取的影象和標籤訓練它。
// T這裡是一個完整的PCA變換
//如果你只想保留10個主成分,使用如下程式碼
// cv::createEigenFaceRecognizer(10);
//
// 如果你還希望使用置信度閾值來初始化,使用以下語句:
// cv::createEigenFaceRecognizer(10, 123.0);
//
// 如果你使用所有特徵並且使用一個閾值,使用以下語句:
// cv::createEigenFaceRecognizer(0, 123.0);
Ptr<FaceRecognizer> model = createEigenFaceRecognizer();
model->train(images, labels);
model->save("MyFacePCAModel.xml");
Ptr<FaceRecognizer> model1 = createFisherFaceRecognizer();
model1->train(images, labels);
model1->save("MyFaceFisherModel.xml");
Ptr<FaceRecognizer> model2 = createLBPHFaceRecognizer();
model2->train(images, labels);
model2->save("MyFaceLBPHModel.xml");
// 下面對測試影象進行預測,predictedLabel是預測標籤結果
int predictedLabel = model->predict(testSample);
int predictedLabel1 = model1->predict(testSample);
int predictedLabel2 = model2->predict(testSample);
// 還有一種呼叫方式,可以獲取結果同時得到閾值:
// int predictedLabel = -1;
// double confidence = 0.0;
// model->predict(testSample, predictedLabel, confidence);
string result_message = format("Predicted class = %d / Actual class = %d.", predictedLabel, testLabel);
string result_message1 = format("Predicted class = %d / Actual class = %d.", predictedLabel1, testLabel);
string result_message2 = format("Predicted class = %d / Actual class = %d.", predictedLabel2, testLabel);
cout << result_message << endl;
cout << result_message1 << endl;
cout << result_message2 << endl;
waitKey(0);
return 0;
}-----------------------------------------------
更新:opencv3版本的程式碼有所改動,請參考較新的部落格提示。
-----------------------------------------------
知識星球
除了平時發文章之外,也會發一些平時學習過程中其他的參考資料和程式碼,歡迎加入。
