
中文分詞原理和實現
三大主流分詞方法:基於詞典的方法、基於規則的方法和基於統計的方法。
1、基於規則或詞典的方法
定義:按照一定策略將待分析的漢字串與一個“大機器詞典”中的詞條進行匹配,若在詞典中找到某個字串,則匹配成功。
- 按照掃描方向的不同:正向匹配和逆向匹配
- 按照長度的不同:最大匹配和最小匹配
1.1正向最大匹配思想MM
- 從左向右取待切分漢語句的m個字元作為匹配欄位,m為大機器詞典中最長詞條個數。
- 查詢大機器詞典並進行匹配:
- 若匹配成功,則將這個匹配欄位作為一個詞切分出來。
- 若匹配不成功,則將這個匹配欄位的最後一個字去掉,剩下的字串作為新的匹配欄位,進行再次匹配,重複以上過程,直到切分出所有詞為止。
舉個栗子:
現在,我們要對“南京市長江大橋”這個句子進行分詞,根據正向最大匹配的原則:
- 先從句子中拿出前5個字元“南京市長江”,把這5個字元到詞典中匹配,發現沒有這個詞,那就縮短取字個數,取前四個“南京市長”,發現詞庫有這個詞,就把該詞切下來;
- 對剩餘三個字“江大橋”再次進行正向最大匹配,會切成“江”、“大橋”;
- 整個句子切分完成為:南京市長、江、大橋;
1.2逆向最大匹配演算法RMM
該演算法是正向最大匹配的逆向思維,匹配不成功,將匹配欄位的最前一個字去掉,實驗表明,逆向最大匹配演算法要優於正向最大匹配演算法。
還是那個栗子:
- 取出“南京市長江大橋”的後四個字“長江大橋”,發現詞典中有匹配,切割下來;
- 對剩餘的“南京市”進行分詞,整體結果為:南京市、長江大橋
1.3 雙向最大匹配法(Bi-directction Matching method,BM)
雙向最大匹配法是將正向最大匹配法得到的分詞結果和逆向最大匹配法的到的結果進行比較,從而決定正確的分詞方法。
據SunM.S. 和 Benjamin K.T.(1995)的研究表明,中文中90.0%左右的句子,正向最大匹配法和逆向最大匹配法完全重合且正確,只有大概9.0%的句子兩種切分方法得到的結果不一樣,但其中必有一個是正確的(歧義檢測成功),只有不到1.0%的句子,或者正向最大匹配法和逆向最大匹配法的切分雖重合卻是錯的,或者正向最大匹配法和逆向最大匹配法切分不同但兩個都不對(歧義檢測失敗)。這正是雙向最大匹配法在實用中文資訊處理系統中得以廣泛使用的原因所在。
還是那個栗子:
雙向的最大匹配,即把所有可能的最大詞都分出來,上面的句子可以分為:南京市、南京市長、長江大橋、江、大橋
1.4設立切分標誌法
收集切分標誌,在自動分詞前處理切分標誌,再用MM、RMM進行細加工。
1.5最佳匹配(OM,分正向和逆向)
對分詞詞典按詞頻大小順序排列,並註明長度,降低時間複雜度。
優點:易於實現
缺點:匹配速度慢。對於未登入詞的補充較難實現。缺乏自學習。
1.6逐詞遍歷法
這種方法是將詞庫中的詞由長到短遞減的順序,逐個在待處理的材料中搜索,直到切分出所有的詞為止。
處理以上基本的機械分詞方法外,還有雙向掃描法、二次掃描法、基於詞頻統計的分詞方法、聯想—回溯法等。
2、基於統計的分詞
隨著大規模語料庫的建立,統計機器學習方法的研究和發展,基於統計的中文分詞方法漸漸成為了主流方法。
主要思想:把每個詞看做是由詞的最小單位各個字總成的,如果相連的字在不同的文字中出現的次數越多,就證明這相連的字很可能就是一個詞。因此我們就可以利用字與字相鄰出現的頻率來反應成詞的可靠度,統計語料中相鄰共現的各個字的組合的頻度,當組合頻度高於某一個臨界值時,我們便可認為此字組可能會構成一個詞語。
主要統計模型:N元文法模型(N-gram),隱馬爾可夫模型(Hidden Markov Model ,HMM),最大熵模型(ME),條件隨機場模型(Conditional Random Fields,CRF)等。
優勢:在實際的應用中經常是將分詞詞典串匹配分詞和統計分詞能較好地識別新詞兩者結合起來使用,這樣既體現了匹配分詞切分不僅速度快,而且效率高的特點;同時又能充分地利用統計分詞在結合上下文識別生詞、自動消除歧義方面的優點。
2.1 N-gram模型思想
模型基於這樣一種假設,第n個詞的出現只與前面N-1個詞相關,而與其它任何詞都不相關,整句的概率就是各個詞出現概率的乘積。
我們給定一個詞,然後猜測下一個詞是什麼。當我說“豔照門”這個詞時,你想到下一個詞是什麼呢?我想大家很有可能會想到“陳冠希”,基本上不會有人會想到“陳志傑”吧,N-gram模型的主要思想就是這樣的。
對於一個句子T,我們怎麼算它出現的概率呢?假設T是由詞序列W1,W2,W3,…Wn組成的,那麼
P(T)=P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
但是這種方法存在兩個致命的缺陷:一個缺陷是引數空間過大,不可能實用化;另外一個缺陷是資料稀疏嚴重。為了解決這個問題,我們引入了馬爾科夫假設:一個詞的出現僅僅依賴於它前面出現的有限的一個或者幾個詞。如果一個詞的出現僅依賴於它前面出現的一個詞,那麼我們就稱之為bigram。即P(T) =P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
≈P(W1)P(W2|W1)P(W3|W2)…P(Wn|Wn-1)
如果一個詞的出現僅依賴於它前面出現的兩個詞,那麼我們就稱之為trigram。
在實踐中用的最多的就是bigram和trigram了,而且效果很不錯。高於四元的用的很少,因為訓練它需要更龐大的語料,而且資料稀疏嚴重,時間複雜度高,精度卻提高的不多。一般的小公司,用到二元的模型就夠了,像Google這種巨頭,也只是用到了大約四元的程度,它對計算能力和空間的需求都太大了。
以此類推,N元模型就是假設當前詞的出現概率只同它前面的N-1個詞有關。
2.2 HMM、CRF 模型思想
以往的分詞方法,無論是基於規則的還是基於統計的,一般都依賴於一個事先編制的詞表(詞典),自動分詞過程就是通過詞表和相關資訊來做出詞語切分的決策。與此相反,
基於字標註(或者叫基於序列標註)的分詞方法實際上是構詞方法,即把分詞過程視為字在字串中的標註問題。
由於每個字在構造一個特定的詞語時都佔據著一個確定的構詞位置(即詞位),假如規定每個字最多隻有四個構詞位置:即B(詞首),M (詞中),E(詞尾)和S(單獨成詞),那麼下面句子(甲)的分詞結果就可以直接表示成如(乙)所示的逐字標註形式:
(甲)分詞結果:/上海/計劃/N/本/世紀/末/實現/人均/國內/生產/總值/五千美元/
(乙)字標註形式:上/B海/E計/B劃/E N/S 本/s世/B 紀/E 末/S 實/B 現/E 人/B 均/E 國/B 內/E生/B產/E總/B值/E 五/B千/M 美/M 元/E 。/S首先需要說明,這裡說到的“字”不只限於漢字。考慮到中文真實文字中不可避免地會包含一定數量的非漢字字元,本文所說的“字”,也包括外文字母、阿拉伯數字和標點符號等字元。所有這些字元都是構詞的基本單元。當然,漢字依然是這個單元集合中數量最多的一類字元。
把分詞過程視為字的標註問題的一個重要優勢在於,它能夠平衡地看待詞表詞和未登入詞的識別問題。
在這種分詞技術中,文字中的詞表詞和未登入詞都是用統一的字標註過程來實現的。在學習架構上,既可以不必專門強調詞表詞資訊,也不用專門設計特定的未登入詞(如人名、地名、機構名)識別模組。這使得分詞系統的設計大大簡化。在字標註過程中,所有的字根據預定義的特徵進行詞位特性的學習,獲得一個概率模型。然後,在待分字串上,根據字與字之間的結合緊密程度,得到一個詞位的標註結果。最後,根據詞位定義直接獲得最終的分詞結果。總而言之,在這樣一個分詞過程中,分詞成為字重組的簡單過程。在學習構架上,由於可以不必特意強調詞表詞的資訊,也不必專門設計針對未登入詞的特定模組,這樣使分詞系統的設計變得尤為簡單。
2001年Lafferty在最大熵模型(MEM)和隱馬爾科夫模型(HMM)的基礎上提出來了一種無向圖模型–條件隨機場(CRF)模型,它能在給定需要標記的觀察序列的條件下,最大程度提高標記序列的聯合概率。常用於切分和標註序列化資料的統計模型。CRF演算法理論見我的其他部落格,此處就不贅述了。
2.3 基於統計分詞方法的實現
現在,我們已經從全概率公式引入了語言模型,那麼真正用起來如何用呢?
我們有了統計語言模型,下一步要做的就是劃分句子求出概率最高的分詞,也就是對句子進行劃分,最原始直接的方式,就是對句子的所有可能的分詞方式進行遍歷然後求出概率最高的分詞組合。但是這種窮舉法顯而易見非常耗費效能,所以我們要想辦法用別的方式達到目的。
仔細思考一下,假如我們把每一個字當做一個節點,每兩個字之間的連線看做邊的話,對於句子“中國人民萬歲”,我們可以構造一個如下的分詞結構:
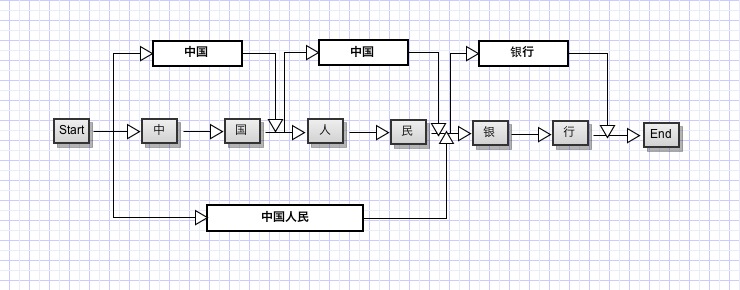
我們要找概率最大的分詞結構的話,可以看做是一個動態規劃問題, 也就是說,要找整個句子的最大概率結構,對於其子串也應該是最大概率的。
對於句子任意一個位置
我們要做的就是找到一個概率最大的路徑即可。我們假設

其中k是當前位置的可能單詞,l是上一個位置的可能單詞,M是l可能的取值,有了狀態轉移返程,寫出遞迴的動態規劃程式碼就很容易了(這個方程其實就是著名的viterbi演算法,通常在隱馬爾科夫模型中應用較多)。
#!/usr/bin/python
# coding:utf-8
"""
viterbi
"""
from lm import LanguageModel
class Node(object):
"""有向圖中的節點"""
def __init__(self,word):
# 當前節點作為左右路徑中的節點時的得分
self.max_score = 0.0
# 前一個最優節點
self.prev_node = None
# 當前節點所代表的詞
self.word = word
class Graph(object):
"""有向圖"""
def __init__(self):
# 有向圖中的序列是一組hash集合
self.sequence = []
class DPSplit(object):
"""動態規劃分詞"""
def __init__(self):
self.lm = LanguageModel('RenMinData.txt')
self.dict = {}
self.words = []
self.max_len_word = 0
self.load_dict('dict.txt')
self.graph = None
self.viterbi_cache = {}
def get_key(self, t, k):
return '_'.join([str(t),str(k)])
def load_dict(self,file):
with open(file, 'r') as f:
for line in f:
word_list = [w.encode('utf-8') for w in list(line.strip().decode('utf-8'))]
if len(word_list) > 0:
self.dict[''.join(word_list)] = 1
if len(word_list) > self.max_len_word:
self.max_len_word = len(word_list)
def createGraph(self):
"""根據輸入的句子建立有向圖"""
self.graph = Graph()
for i in range(len(self.words)):
self.graph.sequence.append({})
word_length = len(self.words)
# 為每一個字所在的位置建立一個可能詞集合
for i in range(word_length):
for j in range(self.max_len_word):
if i+j+1 > len(self.words):
break
word = ''.join(self.words[i:i+j+1])
if word in self.dict:
node = Node(word)
# 按照該詞的結尾字為其分配位置
self.graph.sequence[i+j][word] = node
# 增加一個結束空節點,方便計算
end = Node('#')
self.graph.sequence.append({'#':end})
# for s in self.graph.sequence:
# for i in s.values():
# print i.word,
# print ' - '
# exit(-1)
def split(self, sentence):
self.words = [w.encode('utf-8') for w in list(sentence.decode('utf-8'))]
self.createGraph()
# 根據viterbi動態規劃演算法計算圖中的所有節點最大分數
self.viterbi(len(self.words), '#')
# 輸出分支最大的節點
end = self.graph.sequence[-1]['#']
node = end.prev_node
result = []
while node:
result.insert(0,node.word)
node = node.prev_node
print ''.join(self.words)
print ' '.join(result)
def viterbi(self, t, k):
"""第t個位置,是單詞k的最優路徑概率"""
if self.get_key(t,k) in self.viterbi_cache:
return self.viterbi_cache[self.get_key(t,k)]
node = self.graph.sequence[t][k]
# t = 0 的情況,即句子第一個字
if t == 0:
node.max_score = self.lm.get_init_prop(k)
self.viterbi_cache[self.get_key(t,k)] = node.max_score
return node.max_score
prev_t = t - len(k.decode('utf-8'))
# 當前一個節點的位置已經超出句首,則無需再計算概率
if prev_t == -1:
return 1.0
# 獲得前一個狀態所有可能的漢字
pre_words = self.graph.sequence[prev_t].keys()
for l in pre_words:
# 從l到k的狀態轉移概率
state_transfer = self.lm.get_trans_prop(k, l)
# 當前狀態的得分為上一個最優路徑的概率乘以當前的狀態轉移概率
score = self.viterbi(prev_t, l) * state_transfer
prev_node = self.graph.sequence[prev_t][l]
cur_score = score + prev_node.max_score
if cur_score > node.max_score:
node.max_score = cur_score
# 把當前節點的上一最優節點儲存起來,用來回溯輸出
node.prev_node = self.graph.sequence[prev_t][l]
self.viterbi_cache[self.get_key(t,k)] = node.max_score
return node.max_score
def main():
dp = DPSplit()
dp.split('中國人民銀行')
dp.split('中華人民共和國今天成立了')
dp.split('努力提高居民收入')
if __name__ == '__main__':
main()需要特別注意的幾點是:
1. 做遞迴計算式務必使用快取,把子問題的解先暫存起來,參考動態規劃入門實踐。
2. 當前位置的前一位置應當使用當前位置單詞的長度獲得。
3. 以上程式碼只是作為實驗用,原理沒有問題,但效能較差,生產情況需要建立索引以提高效能。
4. 本分詞程式碼忽略了英文單詞、未登入詞和標點符號,但改進並不複雜,讀者可自行斟酌。
程式碼的輸出結果為:
中國人民銀行:中國 人民 銀行
中華人民共和國今天成立了:中華人民共和國 今天 成立 了
努力提高居民收入:努力 提高 居民 收入參考文獻
中國碩士學位論文全文資料庫
許華婷;基於Active Learning的中文分詞領域自適應方法的研究[D];北京交通大學;2015年
代聰;基於英漢平行語料的中文分詞研究與應用[D];大連理工大學;2012年
劉偉麗;基於粒子群演算法和支援向量機的中文文字分類研究[D];河南工業大學;2010年
黃翼彪;開源中文分詞器的比較研究[D];鄭州大學;2013年
中國博士學位論文全文資料庫
王建會;中文資訊處理中若干關鍵技術的研究[D];復旦大學;2004年
賀前華;漢語自動分詞及機器翻譯研究[D];華南理工大學;1993年
孫曉;中文詞法分析的研究及其應用[D];大連理工大學;2010年