
醫學影像開源資料集
筆者是在醫療AI領域奮鬥的博士生,最近好幾位做計算機視覺的好朋友,想嘗試醫療領域的影像,Bigdata是AI的燃料,索性把自己之前的藏貨拿出來分享一下,大家一起加油!
(醫學影像的分割、匹配、分類、超分辨、重建等應該都有資源)
1、Github上哈佛 beamandrew機器學習和醫學影像研究者-貢獻的資料集
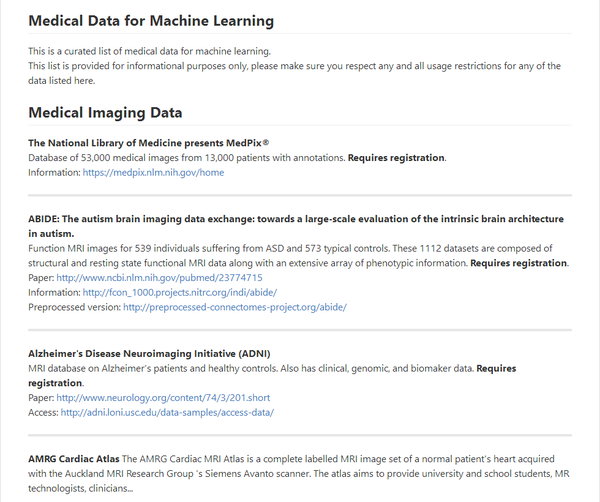
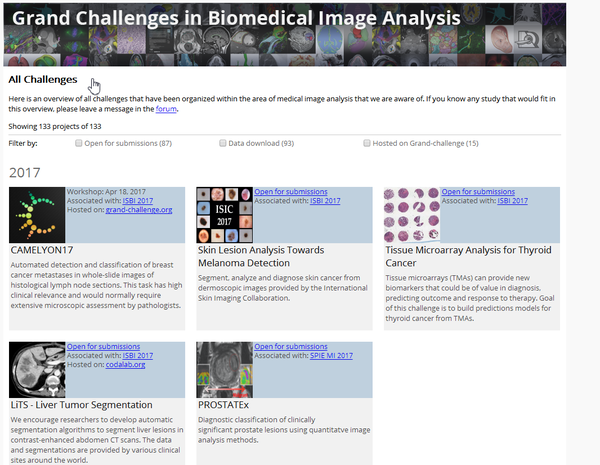
2、ISBI(生物醫學成像國際研討會)
論文比較多,大家自己找找。需要自己註冊一個賬號,才可以下載裡面的資料。
相關推薦
醫學影像開源資料集
筆者是在醫療AI領域奮鬥的博士生,最近好幾位做計算機視覺的好朋友,想嘗試醫療領域的影像,Bigdata是AI的燃料,索性把自己之前的藏貨拿出來分享一下,大家一起加油! (醫學影像的分割、匹配、分類、超分辨、重建等應該都有資源) 1、Github上哈佛 beamandr
機器學習、深度學習開源資料集分享
轉自:機器學習演算法與Python學習 機器學習演算法與Python學習 微訊號guodongwei1991 功能介紹作為溝通學習的平臺,釋出機器學習與資料探勘、深度學習、Python實戰的前沿與動態,歡迎機器學習愛好者的加入,希望幫助你在AI領域更好的發展,期待與你相遇! 今天
資料集 | 開源資料集(計算機視覺影象、定位、識別)
博主github:https://github.com/MichaelBeechan 博主CSDN:https://blog.csdn.net/u011344545 計算機視覺資料集:https://github.com/Michael
目前開源資料集整理
Attention! 我的Dr.Sure專案正式上線了,主旨在分享學習Tensorflow以及DeepLearning中的一些想法。期間隨時更新我的論文心得以及想法。 Images Analysis 資料集 介紹 備註
轉發--目前開源資料集整理
--------------------- 本文來自 忘情擺渡 的CSDN 部落格 ,全文地址請點選:https://blog.csdn.net/wangqingbaidu/article/details/80635618?utm_source=copy Atten
機器視覺中常用開源資料集和免費標註工具
科技巨頭如Google,微軟,亞馬遜等都紛紛宣佈在AI領域佈局,AI的影響隨著深度學習的應用日益深入。機器視覺作為一個熱門子領域,無論是在傳統金融行業還是最新自動駕駛領域都掀起了一股學習應用的浪潮。這是多麼棒的一件事啊!但是我們應該如何簡單的開始研究機器視覺?以下是幾個主要的
影象處理開源資料集
(1)手寫數字識別 訓練集:60000個 測試集:10000個 下載連結:http://yann.lecun.com/exdb/mnist/ (2)貓狗分類 下載連結:https://www.kaggle.com/c/dogs-vs-cats/data (3
醫學影像資料集
轉自:https://blog.csdn.net/sinat_37842336/article/details/80582948 1、肺結節資料庫LIDC-IDRI: CSDN資料庫介紹:http://blog.csdn.net/dcxhun3/article/details/5428959
醫學影像資料集彙總
本文轉自:https://blog.csdn.net/sinat_37842336/article/details/805829481、肺結節資料庫LIDC-IDRI:2、乳腺影象資料庫DDSM MIAS圖片格式為LJPEG需要使用對應的壓縮方法對其進行解壓,目前找到了xMe
騰訊AI Lab開源業內最大規模多標籤影象資料集(附下載地址)
參加 2018 AI開發者大會,請點選 ↑↑↑ 今日(10 月 18 日),騰訊AI Lab宣佈正式開源“Tencent ML-Images”專案。該專案由多標籤影象資料集 ML-Images,以及業內目前同類深度學習模型中精度最高的深度殘差網路 ResNet-101 構成。
資源 | 騰訊開源800萬中文詞的NLP資料集
本文經AI新媒體量子位(公眾號ID:qbitai)授權轉載,轉載請聯絡出處。 本文約1200字,建議閱讀6分鐘。 本文為你介紹鵝廠近期正式開源的一個大規模、高質量的中文詞向量資料集。 鵝廠開源,+1 again~ 又一來自騰訊AI實驗室的資源帖。
CNN-中文文字分類-開源專案-自定義資料集
最近參加學校的一個數據分析比賽,因為自己前面自學了一些基本的機器學習演算法,但其實還處於入門階段,便參加了。選擇了一道中文文字分類的題目。 今日頭條使用者畫像 選題背景: 隨著機器創作能力越來越強,今後社會媒體上將會產生越來越多的機器創作者自動生產的內容。有效
百度開源 FAQ 問答系統(AnyQ)---FAQ資料集的新增
1.FAQ 所謂FAQ(Frequently Asked Questions)問答,指的是通過構建一個數量巨大的問題答案庫來作為語料庫,當輸入一個問題時,通過計算該問題與語料庫中的所有問題的語義相似度,
阿里重磅開源!4000臺伺服器真實資料集,揭祕世界級資料中心
阿里妹導讀:開啟一篇篇 IT 技術文章,你總能夠看到“大規模”、“海量請求”這些字眼。這些功能強大的網際網路應用,都執行在大規模資料中心上。資料中心每個機器的執行情況如何?執行著什麼樣的應用?應用有什麼特點?除了少數資深從業者之外,普通學生和企業的研究者很難了解其中細節。 今天,阿里巴巴再度開放一份計算機叢
周博通 | 阿里開源首個 DL 框架、4000臺伺服器真實資料集;明年1月開源Blink
阿里開源首個深度學習框架 X-Deep Learning 以深度學習為核心的人工智慧技術,過去的幾年在語音識別、計算機視覺、自然語言處理等領域獲得了巨大的成功,其中以GPU為代表的硬體計算力,以及優秀的開源深度學習框架起到了巨大的推動作用。 儘管以TensorFlow、PyTorch、MxNet等為代表的
開源標準資料集 —— mnist(手寫字元識別)
使用 python 讀取和解析 mnist.pkl.gz import pickle import gzip def load_data(): with gzip.o
java利用poi開源庫實現將資料集寫入Excel表格並儲存在本地
一,目前主流的關於讀寫excel表格的有poi 和jxl開源庫,這裡只是簡單的介紹如何poi將資料集寫進Excel表格,並存進本地。 二,官網下載poi的相關jar包,網址 http://poi.apache.org/download.html#POI-4.0.1 &nb
安全資料集和開源工具
由於本人從事安全相關的行業的工作,接觸到很多想用機器學習解決網路安全相關的問題,不可避免的需要用到很多安全相關的開源資料集和工具,這裡記錄一下本人自己用過並感覺不錯的資料集和開源工具。當然,這可能只是安全領域資料集和開源工具極小的一部分,希望能起到拋磚引玉的目的吧,本
開源一個安全帽佩戴檢測資料集及預訓練模型
本文開源了一個安全帽佩戴檢測資料集及預訓練模型,該專案已上傳至github,點此連結,感覺有幫助的話請點star 。同時簡要介紹下實踐上如何完成一個端到端的目標檢測任務。可以看下效果圖: 同時該模型也可以做人頭檢測,效果如下: 一、背景介紹 最近幾年深度學習的發展讓很多計算機視覺任務落地成
開源髮絲分割資料集CelebAHairMask-HQ(國慶獻禮)
在這個特別日子裡,舉國歡慶,什麼都可以缺席,大禮包不行。 本次開源針對CelebAMask-HQ中髮絲部分進行細化的資料集。 該資料集可用於髮絲分割等方向的研究和探索。 在過去的一年時間裡,疫情改變很多人的工作和生活, 博主自然免不了也成為其中一員,非常有幸成為了一名無業遊民。 不是別的原因,只