
基於流水線的CPU的設計
1.我們知道,CPU是電腦的中央處理單元,CPU到底是怎麼連續的執行指令的。我們以MIPS為例,探究一下。
2.基礎的知識我們需要知道,CPU執行一條指令時分為五個階段的:(1)在記憶體取指令(2)根據指令讀暫存器(3)利用暫存器中的資料ALU(4)訪問記憶體(5)寫暫存器。一般是這五個階段,但是很多指令並不是說這五個階段全部都在做事情。比如add,它只有四個階段,其中不涉及到記憶體的訪問。但是,又有指令五個階段都要做事情,比如lw。既然是通用的CPU,我們儘可能的支援奪得指令,或者說是一種短板效應。
3.知道了這些,我們分析一下,CPU如果是一條一條的執行指令,那麼就會出現這種情況,比如add,在執行它的時候,他被執行到第二階段,第一個取指令的操作就空了下來,同理,越來越多的操作被空閒。這顯示是不行的,對於追求效率的CPU是不能容忍的,於是在基於工廠流水線的啟發:提出了基於流水線形式工作的CPU。大概就是這個樣子。

這是五條指令在一起工作,上一條使用完資源以後,下一條緊接著繼續。十分的緊湊,沒錯,這樣就讓CPU連續不空閒的工作,看上去似乎很不錯。
4.流水線的困境。雖然上邊基於流水線的設計,使得CPU得到了很高的效率,但是也面臨這一些困境,或者說冒險。這些詞是根據英文 Hazards翻譯而來。
5.結構困境:

我們觀察這樣一種執行的指令的順序:我們注意到,第一條指令和第四條指令在同一個階段都是在訪問記憶體,其中第一條是在寫記憶體,第二條是在讀記憶體。這兩種操作在某種意義下是相反的,你不可能又讀又寫吧,這顯然是不合理的。為了解決這個問題,人們發明了快取技術。使用兩個一級快取,一個讀一個寫。即保證了效率,又解決了衝突。
同樣的問題也發生在了暫存器上:

我們發現,存在兩條指令一條寫暫存器,一條讀暫存器。這也是不合理的。但是由於暫存器的讀寫速度很快,並且,肯定是要先寫後讀的,因為後邊的指令可能要用到上面指令得到的資料,所以規定先寫後讀。這樣,結構困境被完美解決。
6.控制困境:我們知道,程式時不可避免要出現分支的,就像這樣:

但是我們很快就可以發現問題,因為分支的結果是在ALU之後才能知道的,所以你當前分支後邊的兩條指令到底執行什麼,這是不可預料的。有可能跳轉,也有可能不跳轉,所以把那些指令裝載進來,這是一個很大的問題。針對這個問題,人們提出了三種解決方案:
(1)空指令等待:既然beq這種分支指令只能再ALU之後才能得到結果,那好吧,我在你出結果之前啥也不幹,給你兩條空指令,比如再a0暫存器加0什麼的。那麼其實結構就像是這樣:

這雖然解決了問題,但是引入了兩條空指令,這對CPU這種追求效率的部件來說時不能忍的。然後,人們又提出了第二種解決方案。
(2)人們仔細分析發現,問題的根本原因是在ALU這個位置再整個執行程式流程的後邊,如果把它提前,問題不久容易了一些嘛,所以人們提出再Reg中加一個分支比較器,然後空出一個單個的時間段,這樣似乎又好了很多。

這樣雖然好了很多,但是,還是又空閒,你說人們怎麼就這麼貪心呢?CPU一直工作,插個空閒讓人家休息會不行嗎,電腦科學家說:不行!它得一直給我幹活!行吧,那就幹唄。
(3)新的概念引入,人們發現,這樣雖然不時一整個空指令進去了,但是還是不是很滿意,於是就繼續反思自己。然後發現可能是自己的思想有問題:為什麼分支會產生這樣的問題,因為分支只是做了幹了一個活。我現在重新定義分支,我讓你依次就是執行兩條指令,什麼意思呢?就是說,電腦科學家發現,如果我讓分支一次執行兩條指令,其中一條是分支,另一條是與它無關的指令。這樣再執行完這兩條指令之後,分支的結果也產生了,還順便執行了一條其他的指令。但是這裡面有很多問題:什麼叫做與分支無關的指令,你怎麼找到這樣的指令,這樣的指令一定存在嗎?對於前兩個問題,彙編器會幫我們做,至於最後一個問題,答案是這樣的指令還就真的不一定存在。注意,時不一定,不是一定。但是這種設計使得CPU的效率再很多時候都能達到100%,即使找不到這樣的指令,也是50%。這種設計的方式叫做分支延遲:Delay-Branch

我來解釋一下這個圖,主要是解釋Delay-Branch。看都右邊,我們發現再beq之前,其實ori用到的資料和beq用到的沒關係,所以就可以調整一下位置,把or拿到beq的後邊,這樣再beq完成的時候,or也完成,效率達到100%。
7.我們花了很大的力氣解決了控制困境,但是問題總是解決不完的。畢竟是CPU,怎麼能隨隨便便成功。我們來看一下這個程式執行的過程:

放在流水線上就是這樣的結果:

我們可以看到:由於t0使用的很頻繁,導致再還沒有結果算出來被寫回來的時候,就已經開始用了。資料的即時依賴產生了資料困境。當然了,這些小問題可是難度到我們的電腦科學家。針對這個問題,電腦科學家馬上提出了前饋機制來解決。
Forwarding:

其實我們知道,ALU之後資料的結果已經出來了,那麼你先別寫了,先拿來給我用用。先把資料的結果反饋出去,這就叫做前饋。嗯,似乎很不錯,直到遇見了這張圖:
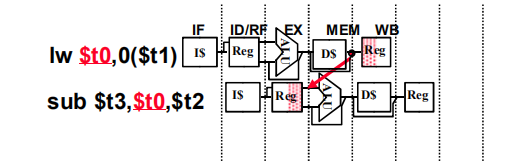
這張圖中,結果再記憶體訪問之後才出來,實在是太慢了,前饋都沒辦法。這可咋辦?沒事,我們的電腦科學家總是有辦法的,他們還是根據剛才的想法,插入一些空指令,使得前饋可以繼續下去。大概就是這樣:

這樣就成功的解決了問題。這樣我們CPU的流水線控制也基本結束了,其實CPU也就是這樣吧,哈哈。