
elasticsearch原始碼分析之叢集管理
一、背景
Elasticsearch是一個實時分散式搜尋和分析引擎。它讓你以前所未有的速度處理大資料成為可能。本文主要介紹實現分散式搜尋和分析的基礎–儲存,好的儲存設計在根本上決定了查詢的效能。
es的儲存本質上是採用了lucene全文索引,在其基礎上實現了分散式功能。
幾個基本概念:
- Cluster:叢集,一個或多個節點的集合,通過名字唯一標識
- Node:節點,組成叢集的服務單元,儲存資料並具有索引和搜尋的能力,通過名字唯一標識
- Shards: 分片 ,將索引分為多個塊,每塊叫做一個分片。索引定義時需要指定分片數且不能更改,每個分片都是一個功能完整的Index,分片帶來規模上(資料水平切分)和效能上(並行執行)的提升
- Replicas:複製分片,對主分片的複製稱為複製分片,索引定義時需指定複製分片數(大於等於0)且可以更改,複製分片可以提供節點失敗時的高可用能力,同時能夠提升搜尋時的併發效能(搜尋可以在全部分片上並行執行)
- Index:索引,具有相似特點的文件的集合,可以對應為關係型資料庫中的資料庫,通過名字在叢集內唯一標識(必須全部小寫)
- Type:類別,索引內部的邏輯分類/分割槽,可以對應為關係型資料庫中的表,通過名字在Index內唯一標識
- Document:文件,能夠被索引的最小單位,JSON格式,屬於一個索引的某個類別中,從屬關係為: Index -> Type -> Document,通過id 在Type 內唯一標識
二、分散式實現
2.1分散式演算法
shard
= hash(routing) % number_of_primary_shards
|
以上是路由文件到分片的演算法,routing值是一個任意字串,它預設是_id但也可以自定義。這個routing字串通過雜湊函式生成一個數字,然後除以主切片的數量得到一個餘數(remainder),餘數的範圍永遠是0到number_of_primary_shards
- 1,這個數字就是特定文件所在的分片。
這也解釋了為什麼主分片的數量只能在建立索引時定義且不能修改:如果主分片的數量在未來改變了,所有先前的路由值就失效了,文件也就永遠找不到了。
2.2寫請求
新建、索引和刪除請求都是寫(write)操作,它們必須在主分片上成功完成才能複製到相關的複製分片上。
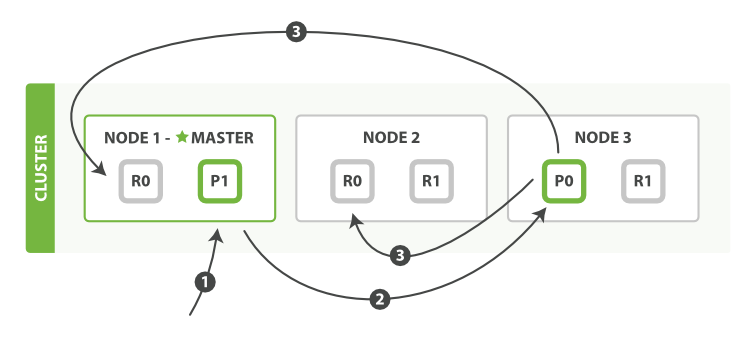
下面我們羅列在主分片和複製分片上成功新建、索引或刪除一個文件必要的順序步驟:
- 客戶端給
Node 1傳送新建、索引或刪除請求。 - 節點使用文件的
_id確定文件屬於分片0。它轉發請求到Node 3,分片0位於這個節點上。 Node 3在主分片上執行請求,如果成功,它轉發請求到相應的位於Node 1和Node 2的複製節點上。當所有的複製節點報告成功,Node 3報告成功到請求的節點,請求的節點再報告給客戶端。
個人理解:此處每個節點都知道index_X-shard_N-node_M的元資料資訊,才能進行相應的請求轉發。
2.3讀請求
文件能夠從主分片或任意一個複製分片被檢索。
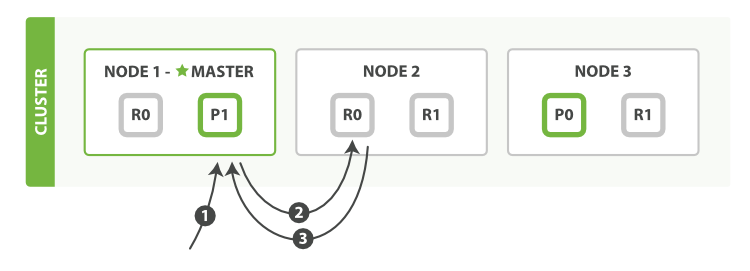
下面我們羅列在主分片或複製分片上檢索一個文件必要的順序步驟:
- 客戶端給
Node 1傳送get請求。 - 節點使用文件的
_id確定文件屬於分片0。分片0對應的複製分片在三個節點上都有。此時,它轉發請求到Node 2。 Node 2返回endangered給Node 1然後返回給客戶端。
2.4區域性更新
update API 結合了之前提到的讀和寫的模式。
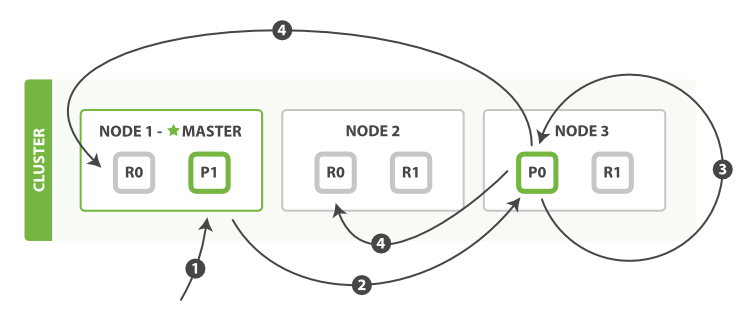
下面我們羅列執行區域性更新必要的順序步驟:
- 客戶端給
Node 1傳送更新請求。 - 它轉發請求到主分片所在節點
Node 3。 Node 3從主分片檢索出文檔,修改_source欄位的JSON,然後在主分片上重建索引。如果有其他程序修改了文件,它以retry_on_conflict設定的次數重複步驟3,都未成功則放棄。- 如果
Node 3成功更新文件,它同時轉發文件的新版本到Node 1和Node 2上的複製節點以重建索引。當所有複製節點報告成功,Node 3返回成功給請求節點,然後返回給客戶端
三、分片管理
3.1倒排索引不可變
寫入磁碟的倒排索引是不可變的,它有如下好處:
- 不需要鎖。如果從來不需要更新一個索引,就不必擔心多個程式同時嘗試修改。
- 一旦索引被讀入檔案系統的快取(譯者:在記憶體),它就一直在那兒,因為不會改變。只要檔案系統快取有足夠的空間,大部分的讀會直接訪問記憶體而不是磁碟。這有助於效能提升。
- 在索引的宣告週期內,所有的其他快取都可用。它們不需要在每次資料變化了都重建,因為資料不會變。
- 寫入單個大的倒排索引,可以壓縮資料,較少磁碟IO和需要快取索引的記憶體大小。
當然,不可變的索引有它的缺點,首先是它不可變!你不能改變它。如果想要搜尋一個新文件,必須重見整個索引。這不僅嚴重限制了一個索引所能裝下的資料,還有一個索引可以被更新的頻次。
3.2動態索引
索引不可變首先需要解決的問題是如何在保持不可變好處的同時更新倒排索引。答案是,使用多個索引。不是重寫整個倒排索引,而是增加額外的索引反映最近的變化。每個倒排索引都可以按順序查詢,從最老的開始,最後把結果聚合。
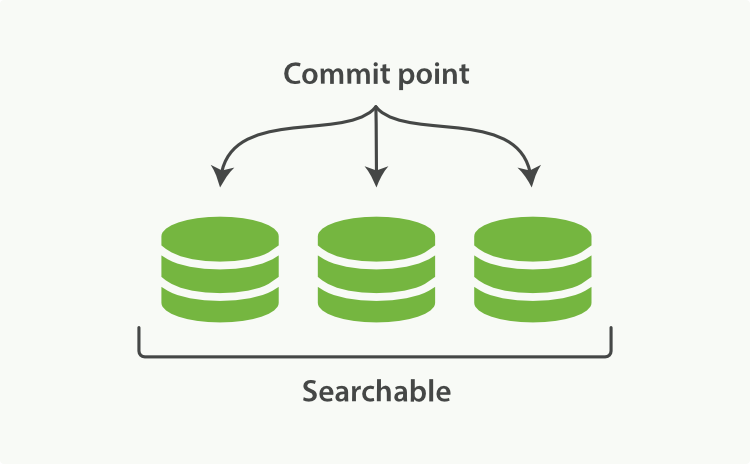
Elasticsearch底層依賴的Lucene,引入了per-segment search的概念。一個段(segment)是有完整功能的倒排索引,但是現在Lucene中的索引指的是段的集合,再加上提交點(commit
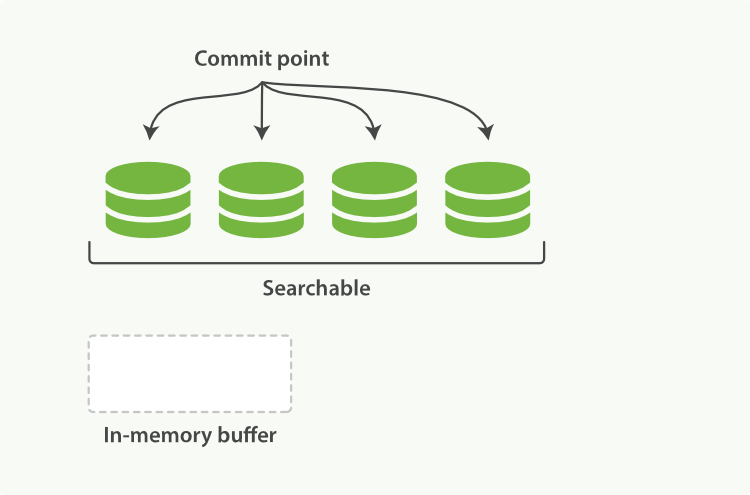
point,包括所有段的檔案),如圖1所示。新的文件,在被寫入磁碟的段之前,首先寫入記憶體區的索引快取,如圖2、圖3所示。
圖1:一個提交點和三個索引的Lucene
一個per-segment search如下工作:
- 新的文件首先寫入記憶體區的索引快取。
- 不時,這些buffer被提交:
- 一個新的段——額外的倒排索引——寫入磁碟。
- 新的提交點寫入磁碟,包括新段的名稱。
- 磁碟是fsync’ed(檔案同步)——所有寫操作等待檔案系統快取同步到磁碟,確保它們可以被物理寫入。
- 新段被開啟,它包含的文件可以被檢索
- 記憶體的快取被清除,等待接受新的文件。
圖2:記憶體快取區有即將提交文件的Lucene索引
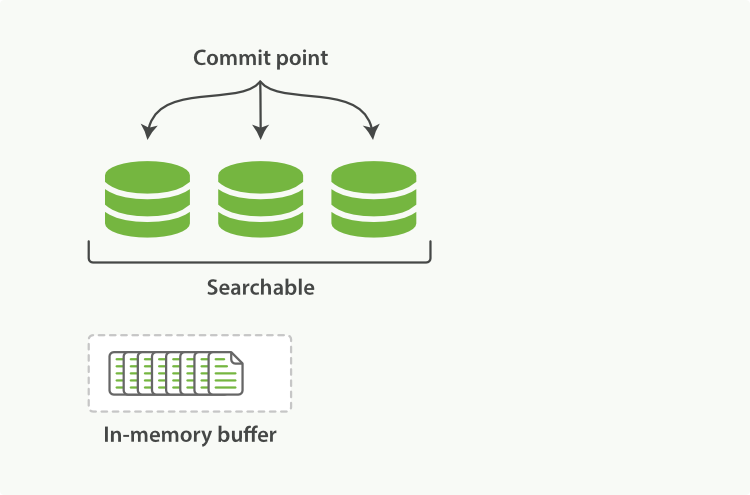
圖3:提交後,新的段加到了提交點,快取被清空
當一個請求被接受,所有段依次查詢。所有段上的Term統計資訊被聚合,確保每個term和文件的相關性被正確計算。通過這種方式,新的文件以較小的代價加入索引。
3.3近實時搜尋(refresh)
位於Elasticsearch和磁碟間的是檔案系統快取。如前所說,在記憶體索引快取中的文件(圖1)被寫入新的段(圖2),但是新的段首先寫入檔案系統快取,這代價很低,之後會被同步到磁碟,這個代價很大。但是一旦一個檔案被快取,它也可以被開啟和讀取,就像其他檔案一樣。
Lucene允許新段寫入開啟,好讓它們包括的文件可搜尋,而不用執行一次全量提交。這是比提交更輕量的過程,可以經常操作,而不會影響效能。
在Elesticsearch中,這種寫入開啟一個新段的輕量級過程,叫做refresh。預設情況下,每個分片每秒自動重新整理一次。這就是為什麼說Elasticsearch是近實時的搜尋了:文件的改動不會立即被搜尋,但是會在一秒內可見。
3.4持久化變更(flush)
沒用fsync同步檔案系統快取到磁碟,我們不能確保電源失效,甚至正常退出應用後,資料的安全。為了ES的可靠性,需要確保變更持久化到磁碟。
我們說過一次全提交同步段到磁碟,寫提交點,這會列出所有的已知的段。在重啟,或重新開啟索引時,ES使用這次提交點決定哪些段屬於當前的分片。
當我們通過每秒的重新整理獲得近實時的搜尋,我們依然需要定時地執行全提交確保能從失敗中恢復。但是提交之間的文件怎麼辦?我們也不想丟失它們。
ES增加了事務日誌(translog),來記錄每次操作。有了事務日誌,過程現在如下:
-
當一個文件被索引,它被加入到記憶體快取,同時加到事務日誌。
圖1:新的文件加入到記憶體快取,同時寫入事務日誌
-
refresh使得分片的進入如下圖描述的狀態。每秒分片都進行refeash:
- 記憶體緩衝區的文件寫入到段中,但沒有fsync。
- 段被開啟,使得新的文件可以搜尋。
-
快取被清除
-
隨著更多的文件加入到快取區,寫入日誌,這個過程會繼續
-
不時地,比如日誌很大了,新的日誌會建立,會進行一次全提交:
- 記憶體快取區的所有文件會寫入到新段中。
- 清除快取
- 一個提交點寫入硬碟
- 檔案系統快取通過fsync操作flush到硬碟
- 事務日誌被清除
事務日誌記錄了沒有flush到硬碟的所有操作。當故障重啟後,ES會用最近一次提交點從硬碟恢復所有已知的段,並且從日誌裡恢復所有的操作。
3.5端合併(optimize)
通過每秒自動重新整理建立新的段,用不了多久段的數量就爆炸了。有太多的段是一個問題。每個段消費檔案控制代碼,記憶體,cpu資源。更重要的是,每次搜尋請求都需要依次檢查每個段。段越多,查詢越慢。
ES通過後臺合併段解決這個問題。小段被合併成大段,再合併成更大的段。
這是舊的文件從檔案系統刪除的時候。舊的段不會再複製到更大的新段中。
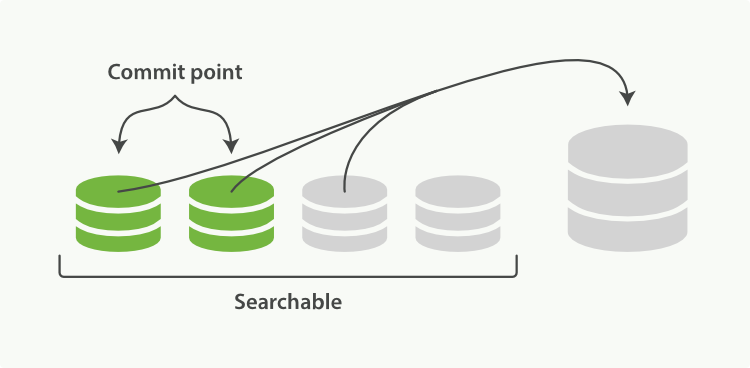
1這個過程你不必做什麼。當你在索引和搜尋時ES會自動處理。這個過程如圖:兩個提交的段和一個未提交的段合併為了一個更大的段所示:
- 索引過程中,refresh會建立新的段,並開啟它。
-
合併過程會在後臺選擇一些小的段合併成大的段,這個過程不會中斷索引和搜尋。
-
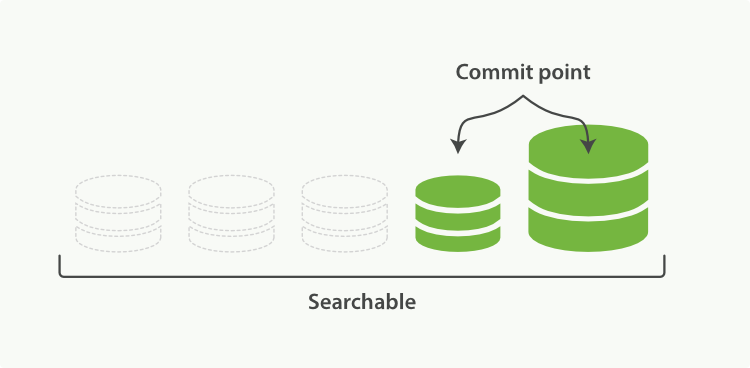
下圖描述了合併後的操作:
- 新的段flush到了硬碟。
- 新的提交點寫入新的段,排除舊的段。
- 新的段開啟供搜尋。
-
舊的段被刪除。
合併大的段會消耗很多IO和CPU,如果不檢查會影響到搜素效能。預設情況下,ES會限制合併過程,這樣搜尋就可以有足夠的資源進行。