
深入kubernetes排程之原理分析
排程器是編排工具的核心,排程策略和演算法是編排工具的靈魂。Kubernetes之所以能夠大行其道,正是因為其優良的排程演算法,本文就來分析下kubernets中scheduler元件的排程原理。
Kubernetes&Docker技術交流QQ群:491137983,一起學習,共同進步!
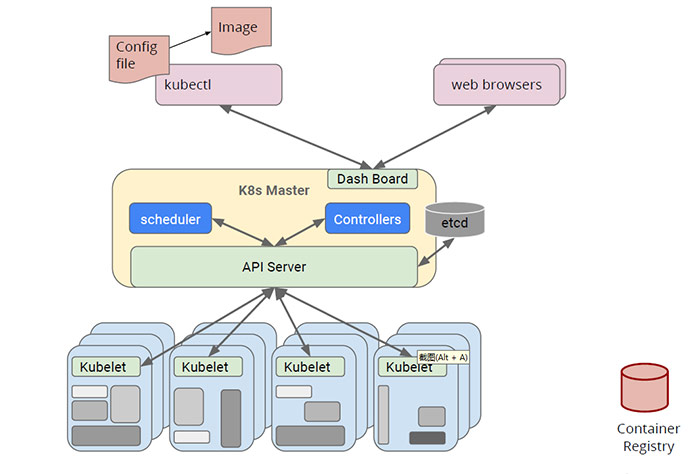
排程是Kubernetes叢集中進行容器編排工作最重要的一環,在Kubernetes中,Controller Manager負責建立Pod,Kubelet負責執行Pod,而Scheduler就是負責安排Pod到具體的Node,它通過API Server提供的介面監聽Pod任務列表,獲取待排程pod,然後根據一系列的預選策略和優選策略給各個Node節點打分,然後將Pod傳送到得分最高的Node節點上,由kubelet負責執行具體的任務內容。架構流程如下:
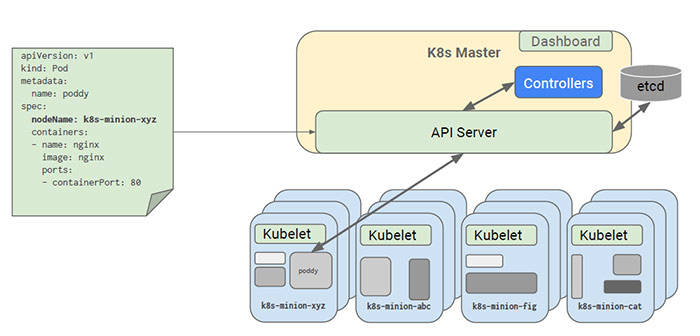
有個特例:如果Pod中指定了NodeName屬性,則Scheduler排程器無需參與,Pod會直接傳送到NodeName指定的Node節點:
1 排程策略
Kubernetes的排程策略分為Predicates(預選策略)和Priorites(優選策略),整個排程過程分為兩步:
1.預選策略,Predicates是強制性規則,遍歷所有的Node節點,按照具體的預選策略篩選出符合要求的Node列表,如沒有Node符合Predicates策略規則,那該Pod就會被掛起,直到有Node能夠滿足。
2.優選策略,在第一步篩選的基礎上,按照優選策略為待選Node打分排序,獲取最優者。
1.1 預選策略
隨著版本的演進Kubernetes支援的Predicates策略逐漸豐富,v1.0版本僅支援4個策略,v1.7支援15個策略,Kubernetes(v1.7)中可用的Predicates策略有:
- MatchNodeSelector:檢查Node節點的label定義是否滿足Pod的NodeSelector屬性需求
- PodFitsResources:檢查主機的資源是否滿足Pod的需求,根據實際已經分配(Limit)的資源量做排程,而不是使用已實際使用的資源量做排程
- PodFitsHostPorts:檢查Pod內每一個容器所需的HostPort是否已被其它容器佔用,如果有所需的HostPort不滿足需求,那麼Pod不能排程到這個主機上
- HostName:檢查主機名稱是不是Pod指定的NodeName
- NoDiskConflict:檢查在此主機上是否存在卷衝突。如果這個主機已經掛載了卷,其它同樣使用這個卷的Pod不能排程到這個主機上,不同的儲存後端具體規則不同
- NoVolumeZoneConflict:檢查給定的zone限制前提下,檢查如果在此主機上部署Pod是否存在卷衝突
- PodToleratesNodeTaints:確保pod定義的tolerates能接納node定義的taints
- CheckNodeMemoryPressure:檢查pod是否可以排程到已經報告了主機記憶體壓力過大的節點
- CheckNodeDiskPressure:檢查pod是否可以排程到已經報告了主機的儲存壓力過大的節點
- MaxEBSVolumeCount:確保已掛載的EBS儲存卷不超過設定的最大值,預設39
- MaxGCEPDVolumeCount:確保已掛載的GCE儲存卷不超過設定的最大值,預設16
- MaxAzureDiskVolumeCount:確保已掛載的Azure儲存卷不超過設定的最大值,預設16
- MatchInterPodAffinity:檢查pod和其他pod是否符合親和性規則
- GeneralPredicates:檢查pod與主機上kubernetes相關元件是否匹配
- NoVolumeNodeConflict:檢查給定的Node限制前提下,檢查如果在此主機上部署Pod是否存在卷衝突
已註冊但預設不載入的Predicates策略有:
- PodFitsHostPorts
- PodFitsResources
- HostName
- MatchNodeSelector
PS:此外還有個PodFitsPorts策略(計劃停用),由PodFitsHostPorts替代
1.2 優選策略
同樣,Priorites策略也在隨著版本演進而豐富,v1.0版本僅支援3個策略,v1.7支援10個策略,每項策略都有對應權重,最終根據權重計算節點總分,Kubernetes(v1.7)中可用的Priorites策略有:
- EqualPriority:所有節點同樣優先順序,無實際效果
- ImageLocalityPriority:根據主機上是否已具備Pod執行的環境來打分,得分計算:不存在所需映象,返回0分,存在映象,映象越大得分越高
- LeastRequestedPriority:計算Pods需要的CPU和記憶體在當前節點可用資源的百分比,具有最小百分比的節點就是最優,得分計算公式:cpu((capacity – sum(requested)) * 10 / capacity) + memory((capacity – sum(requested)) * 10 / capacity) / 2
- BalancedResourceAllocation:節點上各項資源(CPU、記憶體)使用率最均衡的為最優,得分計算公式:10 – abs(totalCpu/cpuNodeCapacity-totalMemory/memoryNodeCapacity)*10
- SelectorSpreadPriority:按Service和Replicaset歸屬計算Node上分佈最少的同類Pod數量,得分計算:數量越少得分越高
- NodePreferAvoidPodsPriority:判斷alpha.kubernetes.io/preferAvoidPods屬性,設定權重為10000,覆蓋其他策略
- NodeAffinityPriority:節點親和性選擇策略,提供兩種選擇器支援:requiredDuringSchedulingIgnoredDuringExecution(保證所選的主機必須滿足所有Pod對主機的規則要求)、preferresDuringSchedulingIgnoredDuringExecution(排程器會盡量但不保證滿足NodeSelector的所有要求)
- TaintTolerationPriority:類似於Predicates策略中的PodToleratesNodeTaints,優先排程到標記了Taint的節點
- InterPodAffinityPriority:pod親和性選擇策略,類似NodeAffinityPriority,提供兩種選擇器支援:requiredDuringSchedulingIgnoredDuringExecution(保證所選的主機必須滿足所有Pod對主機的規則要求)、preferresDuringSchedulingIgnoredDuringExecution(排程器會盡量但不保證滿足NodeSelector的所有要求),兩個子策略:podAffinity和podAntiAffinity,後邊會專門詳解該策略
- MostRequestedPriority:動態伸縮叢集環境比較適用,會優先排程pod到使用率最高的主機節點,這樣在伸縮叢集時,就會騰出空閒機器,從而進行停機處理。
已註冊但預設不載入的Priorites策略有:
- EqualPriority
- ImageLocalityPriority
- MostRequestedPriority
PS:此外還有個ServiceSpreadingPriority策略(計劃停用),由SelectorSpreadPriority替代
2 結語
Kubernetes的Scheduler排程器提供瞭如此大量的排程策略,靈活搭配使用它們,能夠應對各種各樣的需求場景。尤其是在大型叢集環境中,優秀的排程策略和演算法,可以為業務提供穩定高效的執行時環境。