
關注 Linux c/c++ 資料儲存 網路 演算法......
Merkle Hash Tree 簡介

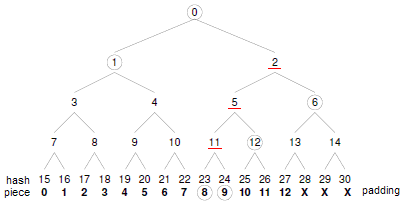
上圖(來自Wikipedia[1])給出了一個二進位制的雜湊樹(二叉雜湊樹, 較常用的tiger hash tree也是這個形式). 據稱雜湊樹經常應用在一些分散式系統或者分散式儲存中的反熵機制(Anti-entropy),也有稱做去熵的.這些應用包括 Amazon的Dynamo 還有Apache的Cassandra資料庫, 通過去熵可以去做到各個不同節點的同步, 即保持各個節點的資訊都是同步最新.
雜湊樹的特點很鮮明: 葉子節點儲存的是資料檔案,而非葉子節點儲存的是其子節點的雜湊值(稱為MessageDigest) 這些非葉子節點的Hash被稱作路徑雜湊值, 葉子節點的Hash值是真實資料的Hash值. 因為使用了樹形結構, MT的時間複雜度為 O
比如下圖中, 我們如果使用SHA1演算法來做校驗值, 比如資料塊8對應的雜湊值是H23,
則按照這個路徑來看 應該有
H11=SHA1(H23∥H24)
H5=SHA1(H11∥H12)
H2=SHA1(H5∥H6)
H0=SHA1(H1∥H2)
其中∥是表聯接的意思.
應用舉例
BitTorrent中應用[3,7]
在BT中, 通常種子檔案中包含的資訊是Root值, 此外還有檔案長度、資料塊長等重要資訊. 當客戶端下載資料塊8時,在下載前,它將要求peer提供校驗塊8所需的全部路徑雜湊值:H24、H12、H6和H1. 下載完成後, 客戶端就會開始校驗, 它先計算它已經下載的資料塊8的Hash值23, 記做H,
表示尚未驗證. 隨後會按照我在上一小節中給出的幾個公式, 來依次求解 直到得到H0′並與H0做比較,
校驗通過則下載無誤. 校驗通過的這些路徑雜湊值會被快取下來, 當一定數量的路徑雜湊值被快取之後,後繼資料塊的校驗過程將被極大簡化。此時我們可以直接利用校驗路徑上層次最低的已知路徑雜湊值來對資料塊進行部分校驗,而無需每次都校驗至根雜湊值H0.
Amazon Dynamo中同步[4]
在Dynamo中,每個節點儲存一個範圍內的key值,不同節點間存在有相互交迭的key值範圍。在去熵操作中,考慮的僅僅是某兩個節點間共有的key值範圍。MT的葉子節點即是這個共有的key值範圍內每個key的hash,通過葉子節點的hash自底向上便可以構建出一顆MT。Dynamo首先比對MT根處的hash,如果一致則表示兩者完全一致,否則將其子節點交換並繼續比較的過程, 知道定位到有差異的資料塊. 這種同步方式在分散式中有著節省網路傳輸量的優點.
Top-k Query RZhang Infocom2012
在Rui Zhang的這篇文章[5]中, 作者採用MerkleTree的目的也在於校驗POI資訊的真實性 這篇文章的閱讀筆記在[6]. 基本思想是假設我們需要得到的query是POI(point-of-interest, 相當於評價 reviews), POIi,j,其中i指區域, j指按TOP排序的POI條數.
文中資料收集者將不同區域的POIs的資料的摘要當作MerkleTree的葉子節點來建立一個BinaryTree. 這些資訊一併提供給LBSP(街旁 Foursquare Google Lattitude這樣的location based service Provider)在QueryResult中附帶這些資訊, 這樣使用者就可以根據這些資訊來驗證這個Top-k query的可信度, 以防止LBSP依據自己的利益需求來修改排名.
Reference
- http://en.wikipedia.org/wiki/Hash_tree
- http://en.wikipedia.org/wiki/Lamport_signature
- http://blog.csdn.net/starxu85/article/details/3859011
- http://ultimatearchitecture.net/index.php/2010/09/12/merkle-tree/
- http://www.public.asu.edu/~rzhang46/
- http://yishanhe.net/wiki/Secure-topk-query.html
- http://www.bittorrent.org/beps/bep_0030.html