
Sklearn-CrossValidation交叉驗證
- 交叉驗證概述
進行模型驗證的一個重要目的是要選出一個最合適的模型,對於監督學習而言,我們希望模型對於未知資料的泛化能力強,所以就需要模型驗證這一過程來體現不同的模型對於未知資料的表現效果。
最先我們用訓練準確度(用全部資料進行訓練和測試)來衡量模型的表現,這種方法會導致模型過擬合;為了解決這一問題,我們將所有資料分成訓練集和測試集兩部分,我們用訓練集進行模型訓練,得到的模型再用測試集來衡量模型的預測表現能力,這種度量方式叫測試準確度,這種方式可以有效避免過擬合。
測試準確度的一個缺點是其樣本準確度是一個高方差估計(high varianceestimate),所以該樣本準確度會依賴不同的測試集,其表現效果不盡相同。
- K折交叉驗證
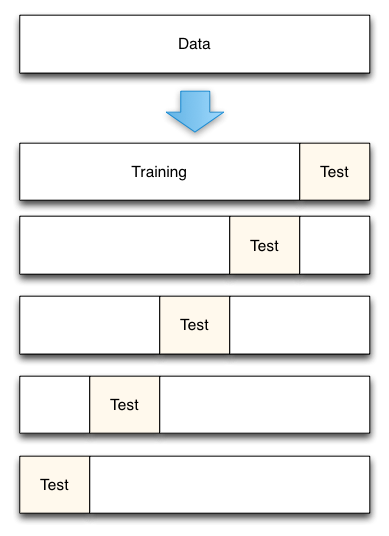
- 將資料集平均分割成K個等份
- 使用1份資料作為測試資料,其餘作為訓練資料
- 計算測試準確率
- 使用不同的測試集,重複2、3步驟
- 對測試準確率做平均,作為對未知資料預測準確率的估計
- sklearn.model_selection.Kfold
classsklearn.model_selection.KFold(n_splits=3,shuffle=False, random_state=None)
引數:
n_splits : 預設3,最小為2;K折驗證的K值
shuffle : 預設False;shuffle會對資料產生隨機攪動(洗牌)
random_state :預設None,隨機種子
方法:
get_n_splits([X, y, groups]) Returnsthe number of splitting iterations in the cross-validator
split(X[, y, groups]) Generateindices to split data into training and test set.
- 下面程式碼演示了K-fold交叉驗證是如何進行資料分割的
# 25個樣本分為5個樣本集 fromsklearn.cross_validation import KFold kf = KFold(25,n_folds=5, shuffle=False) # 打印出每次訓練集和驗證集 print '{} {:^61}{}'.format('Iteration', 'Training set observations', 'Testing setobservations') for iteration, datain enumerate(kf, start=1): print '{:^9} {} {:^25}'.format(iteration,data[0], data[1])
Iteration Training setobservations Testingset observations
1 [ 5 6 7 8 9 10 11 12 13 14 15 16 17 18 1920 21 22 23 24] [0 1 2 3 4]
2 [ 0 1 2 3 4 10 11 12 13 14 15 16 17 18 1920 21 22 23 24] [5 6 7 8 9]
3 [ 0 1 2 3 4 5 6 7 8 9 1516 17 18 19 20 21 22 23 24] [10 11 1213 14]
4 [ 0 1 2 3 4 5 6 7 8 9 1011 12 13 14 20 21 22 23 24] [15 16 1718 19]
5 [ 0 1 2 3 4 5 6 7 8 9 1011 12 13 14 15 16 17 18 19] [20 21 2223 24]
#分出25個數據的五分之一作為測試集,剩下的作為訓練集,這裡沒有對資料進行洗牌,所以按資料的順序進行選擇。訓練-測試的組合也為五次。
- sklearn.cross_validation模組
cross validation大概的意思是:對於原始資料我們要將其一部分分為traindata,一部分分為test data。train data用於訓練,test data用於測試準確率。在test data上測試的結果叫做validation error。將一個演算法作用於一個原始資料,我們不可能只做出隨機的劃分一次train和testdata,然後得到一個validation error,就作為衡量這個演算法好壞的標準。因為這樣存在偶然性。我們必須多次的隨機的劃分train data和test data,分別在其上面算出各自的validation error。這樣就有一組validationerror,根據這一組validationerror,就可以較好的準確的衡量演算法的好壞。crossvalidation是在資料量有限的情況下的非常好的一個evaluate performance的方法。而對原始資料劃分出train data和testdata的方法有很多種,這也就造成了cross validation的方法有很多種。
- 主要函式
sklearn中的cross validation模組,最主要的函式是如下函式:
sklearn.cross_validation.cross_val_score
呼叫形式是:sklearn.cross_validation.cross_val_score(estimator, X, y=None, scoring=None, cv=None,n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')
返回值就是對於每次不同的的劃分raw data時,在test data上得到的分類的準確率。
- 引數解釋:
estimator:是不同的分類器,可以是任何的分類器。比如支援向量機分類器:estimator = svm.SVC(kernel='linear', C=1)
cv:代表不同的cross validation的方法。如果cv是一個int值,並且如果提供了rawtarget引數,那麼就代表使用StratifiedKFold分類方式;如果cv是一個int值,並且沒有提供rawtarget引數,那麼就代表使用KFold分類方式;也可以給定它一個CV迭代策略生成器,指定不同的CV方法。
scoring:預設Nnoe,準確率的演算法,可以通過score_func引數指定;如果不指定的話,是用estimator預設自帶的準確率演算法。
- 幾種不同的CV策略生成器
cross_val_score中的引數cv可以接受不同的CV策略生成器作為引數,以此使用不同的CV演算法。除了剛剛提到的KFold以及StratifiedKFold這兩種對rawdata進行劃分的方法之外,還有其他很多種劃分方法,這裡介紹幾種sklearn中的CV策略生成器函式。
- K-fold
最基礎的CV演算法,也是預設採用的CV策略。主要的引數包括兩個,一個是樣本數目,一個是k-fold要劃分的份數。
fromsklearn.model_selection import KFold
X= np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y= np.array([1, 2, 3, 4])
kf= KFold(n_splits=2)
kf.get_n_splits(X)#給出K折的折數,輸出為2
print(kf)
#輸出為:KFold(n_splits=2, random_state=None,shuffle=False)
for train_index, test_index in kf.split(X):
print("TRAIN:",train_index, "TEST:", test_index)
X_train,X_test = X[train_index], X[test_index]
y_train,y_test = y[train_index], y[test_index]
#輸出:TRAIN: [2 3] TEST: [0 1]
TRAIN: [0 1] TEST: [2 3]#這裡kf.split(X)返回的是X中進行分裂後train和test的索引值,令X中資料集的索引為0,1,2,3;第一次分裂,先選擇test,索引為0和1的資料集為test,剩下索引為2和3的資料集為train;第二次分裂,先選擇test,索引為2和3的資料集為test,剩下索引為0和1的資料集為train。
- Stratified k-fold
與k-fold類似,將資料集劃分成k份,不同點在於,劃分的k份中,每一份內各個類別資料的比例和原始資料集中各個類別的比例相同。
classsklearn.model_selection.StratifiedKFold(n_splits=3,shuffle=False, random_state=None)
from sklearn.model_selection importStratifiedKFold
X= np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
y= np.array([0, 0, 1, 1])
skf= StratifiedKFold(n_splits=2)
skf.get_n_splits(X, y)#給出K折的折數,輸出為2
print(skf)
#輸出為:StratifiedKFold(n_splits=2,random_state=None, shuffle=False)
for train_index, test_index in skf.split(X, y):
print("TRAIN:",train_index, "TEST:", test_index)
X_train,X_test = X[train_index], X[test_index]
y_train,y_test = y[train_index], y[test_index]
#輸出:TRAIN: [1 3] TEST: [0 2]
TRAIN: [0 2] TEST: [1 3]- Leave-one-out
每個樣本單獨作為驗證集,其餘的N-1個樣本作為訓練集,所以LOO-CV會得到N個模型,用這N個模型最終的驗證集的分類準確率的平均數作為此下LOO-CV分類器的效能指標。引數只有一個,即樣本數目。
from sklearn.model_selection import LeaveOneOut
X= [1, 2, 3, 4]
loo= LeaveOneOut()
for train, test in loo.split(X):
print("%s%s" % (train, test))
#結果:[1 2 3] [0]
[0 23] [1]
[0 13] [2]
[0 12] [3]- Leave-P-out
每次從整體樣本中去除p條樣本作為測試集,如果共有n條樣本資料,那麼會生成(n p)個訓練集/測試集對。和LOO,KFold不同,這種策略中p個樣本中會有重疊。
from sklearn.model_selection import LeavePOut
X= np.ones(4)
lpo= LeavePOut(p=2)
for train, test in lpo.split(X):
print("%s%s" % (train, test))
#結果:[2 3] [0 1]
[13] [0 2]
[12] [0 3]
[03] [1 2]
[02] [1 3]
[01] [2 3]- Leave-one-label-out
這種策略劃分樣本時,會根據第三方提供的整數型樣本類標號進行劃分。每次劃分資料集時,取出某個屬於某個類標號的樣本作為測試集,剩餘的作為訓練集。
from sklearn.model_selection import LeaveOneLabelOut
labels = [1,1,2,2]
Lolo=LeaveOneLabelOut(labels)
for train, test in lolo:
print("%s%s" % (train, test))
#結果:[2 3] [0 1]
[01] [2 3]- Leave-P-Label-Out
與Leave-One-Label-Out類似,但這種策略每次取p種類標號的資料作為測試集,其餘作為訓練集。
from sklearn.model_selection import LeavePLabelOut
labels = [1,1,2,2,3,3]
Lplo=LeaveOneLabelOut(labels,p=2)
for train, test in lplo:
print("%s%s" % (train, test))
#結果:[4 5] [0 1 2 3]
[2 3] [0 1 4 5]
[0 1] [2 3 4 5]