
C++ STL庫/C標頭檔案函式
目錄
List 操作函式
優先佇列
Vector
1、結構
vector模塑出一個動態陣列,因此,它本身是“將元素置於動態陣列中加以管理”的一個抽象概念。vector將其元素複製到內部的dynamic array中。元素之間總存在某種順序,所以vector是一種有序群集。vector支援隨機存取,因此只要知道位置,可以在常數時間記憶體取任何一個元素。根據vector的結構可知,在末端新增或者刪除元素,效能相當好,如果在前端或者中部安插或刪除元素,效能就不怎麼樣了,因為操作點之後的元素都需要移到另一位置,而每一次移動都需要呼叫assignement(賦值)操作符。

2、大小(size)和容量(capacity)
2.1 效能
vector的優異效能的祕訣之一就是配置比其容納元素所需更多的記憶體。vector用於操作大小的函式有size(),empty(),max_size(),另一個有關大小的函式是capacity(),它返回的是vector實際能夠容納的元素數量,如果超越這個數量,vector就有必要重新配置內部儲存器。
vector的容量之所以很重要,有以下兩個原因:
- 一旦記憶體重新分配,和vector相關的所有元素都會失效,如:references,pointers,iterators。
- 記憶體分配很耗時間
2.2 記憶體分配
2.2.1 reserve
如果程式管理了和vector元素相關的reference,pointers,iterator,或者執行效率至關重要,那麼就必須考慮容器的容量問題。可以使用reserve()來保留適當容量,避免一再的分配記憶體,只要保留的容量有剩餘,就不用擔心reference失效。
std::vector<T> v;
v.reserve(n); //為vector分配容量為n的記憶體還有一點要記住的是,如果呼叫reserve()所給的引數比當前的vector容量還小,不會發生任何反應,vector不能通過reverse來縮減容量。如何達到時間和空間的最佳效率,由系統版本決定,很多時候為了防止記憶體破碎,即使不呼叫reserve,當你第一次安插元素的時候,也會一次性配置整塊記憶體(例如2K)。vector的容量不會縮減,即使刪除元素,其reference,pointers,iterators也不會失效,繼續指向發生動作之前的位置,然而安插元素可能使這些元素失效(因為安插可能重新分配記憶體空間)。
2.2.2 構造分配
另外一種避免重新分配記憶體的方法是,初始化期間就像建構函式傳遞附加引數,構造出足夠的空間。如果引數是個數值,它將成為vector的起始大小。
std::vector<T> v(500); //分配能容納500個T元素的記憶體大小當然,要獲得這種能力,這種元素必須提供一個default建構函式,如果型別很複雜,提供了default建構函式,初始化也會很耗時,如果只是為了保留足夠的記憶體,建議使用reverse()。
2.2.3 記憶體縮減
當然,要想縮減vector記憶體還是有方法的,那就是兩個vector交換了內容後,兩者的容量也會交換,即保留元素,又縮減了記憶體。

template<class T>
void shrinkCapacity(std::vector<T> &v)
{
std::vector<T> temp(v); //初始化一個新的vector
v.swap(temp); //交換元素內容
}
或者通過下列語句:
std::vector<T> (v).swap(v);不過應該注意的是,swap()之後,原先所有的reference,pointers,iterator都換了指涉物件,他們仍然指向原本位置,也就是說它們在交換之後,都失效了。
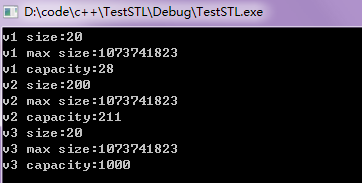
void mvTestSize()
{
// size 為20的vector
vector<int> veciSize1;
for (int i = 0; i < 20; i++)
{
veciSize1.push_back(i);
}
cout << "v1 size:" << veciSize1.size() << endl;
cout << "v1 max size:" << veciSize1.max_size() << endl;
cout << "v1 capacity:" << veciSize1.capacity() << endl;
// size為200的vector
vector<int> veciSize2;
for (int i = 0; i < 200; i++)
{
veciSize2.push_back(i);
}
cout << "v2 size:" << veciSize2.size() << endl;
cout << "v2 max size:" << veciSize2.max_size() << endl;
cout << "v2 capacity:" << veciSize2.capacity() << endl;
//分配固定的size
vector<int> veciSize3;
veciSize3.reserve(1000);
for (int i = 0; i < 20; i++)
{
veciSize3.push_back(i);
}
cout << "v3 size:" << veciSize3.size() << endl;
cout << "v3 max size:" << veciSize3.max_size() << endl;
cout << "v3 capacity:" << veciSize3.capacity() << endl;
}
輸出結果:
3、 vector操作函式
3.1 構造、拷貝和析構
可以在構造時提供元素,也可以不提供。如果指定大小,系統會呼叫元素的default建構函式一一製造新元素。
|
操作 |
效果 |
|
vector<Elem> c |
產生一個空的vector,沒有任何元素 |
|
vector<Elem> c1(c2) |
產生另一同一型別的副本 (所有元素都被拷貝) |
|
vector<Elem> c(n) |
利用元素的default建構函式生成一個大小為n的vector |
|
vector<Elem> c(n,elem) |
產生一個大小為n的vector,每個元素都是elem |
|
vector<Elem> c(beg,end) |
產生一個vector,以區間[beg,end)作為初始值 |
|
c.~vector<Elem>() |
銷燬所有元素,釋放記憶體 |
3.2 非變動操作
|
操作 |
效果 |
|
c.size() |
返回當前的元素數量 |
|
c.empty() |
判斷大小是否為零,等同於0 == size(),效率更高 |
|
c.max_size() |
返回能容納的元素最大數量 |
|
capacity() |
返回重新分配空間前所能容納的最大元素數量 |
|
reserve() |
如果容量不足,擴大 |
|
c1 == c2 |
判斷c1是否等於c2 |
|
c1 != c2 |
判斷c1是否不等於c2(等同於!(c1==c2)) |
|
c1 < c2 |
判斷c1是否小於c2 |
|
c1 > c2 |
判斷c1是否大於c2 |
|
c1 <= c2 |
判斷c1是否小於等於c2(等同於!(c2<c1)) |
|
c1 >= c2 |
判斷c1是否大於等於c2 (等同於!(c1<c2)) |
3.3 賦值操作
|
操作 |
效果 |
|
c1 = c2 |
將c2的元素全部給c1 |
|
c.assign(n,elem) |
複製n個elem給c |
|
c.assign(beg,end) |
將區間[beg,end)賦值給c |
|
c1.swap(c2) |
將c1和c2元素互換 |
|
swap(c1,c2) |
將c1和c2元素互換,全域性函式 |
值得注意的是,所有的賦值操作都可能呼叫元素的default建構函式,copy建構函式和assignment操作符或者解構函式。
3.4 元素存取
|
操作 |
效果 |
|
c.at(idx) |
返回索引idx標示的元素,如果越界,丟擲越界異常 |
|
c[idx] |
返回索引idx標示的元素,不進行範圍檢查 |
|
c.front() |
返回第一個元素,不檢查第一個元素是否存在 |
|
c.back() |
返回最後一個元素,不檢查最後一個元素是否存在 |
按照c/c++的慣例,第一個元素的索引為0,所以n個元素的索引為n-1。只有at()會檢查範圍,其他函式不檢查範圍,如果越界,除了at()會丟擲異常,其他函式會引發未定義行為,所以使用索引的時候,必須確定索引有效,對一個空的vector使用front()和back()都會發生未定義行為,所以呼叫他們,必須保證vector不為空。
對於non-const-vector,這些函式返回的都是reference,可以通過這些函式來改變元素內容。
3.5 迭代器相關函式
vector提供了一些常規函式來獲取迭代器。vector的迭代器是random access iterators(隨機存取迭代器),簡單的來說就是陣列一樣的迭代器,可以直接使用下標操作。
|
操作 |
效果 |
|
c.begin() |
返回一個隨機存取迭代器,指向第一個元素 |
|
c.end() |
返回一個隨機存取迭代器,指向最後一個元素的下一個位置 |
|
c.rbegin() |
返回一個逆向迭代器,指向逆向迭代的第一個元素 |
|
c.rend() |
返回一個逆向迭代器,指向逆向迭代的最後一個元素的下一個位置 |
3.5.1迭代器失效條件
- 使用者在較小位置安插或移除元素。
- 由於容量變化而引起記憶體重新分配。
3.5.2 安插和移除元素
vector提供安插和移除操作函式,呼叫這些函式,必須保證引數合法:
- 迭代器必須指向一個合法位置。
- 區間的起始位置不能在結束位置之後。
- 不能從空容器中移除元素。
關於效能,下列情況的安插和移除操作可能效率高一些:
- 在容器的尾部安插或刪除元素。
- 容量一開始就很大。
- 安插多個元素,呼叫一次比呼叫多次快。
安插和刪除元素,會使“作用點”之後的各元素的reference、pointers、iterators失效,如果安插操作導致記憶體重新分配,該容器的所有reference、pointers、iterators都會失效。
|
操作 |
效果 |
|
c.insert(pos,elem) |
在pos位置上插入一個elem副本,並返回新元素位置 |
|
c.insert(pos,n,elem) |
在pos位置插入n個elem副本,無返回值 |
|
c.insert(pos,beg,end) |
在pos位置插入[beg,end]內所有元素的副本,無返回值 |
|
c.push_back(elem) |
在尾部新增一個elme副本 |
|
c.pop_back() |
移除最後一個元素 |
|
c.erase(pos) |
移除pos上的位置,返回下一個元素的位置 |
|
c.erase(beg,end) |
移除[beg,end)內的所有元素,並返回下一元素的位置 |
|
c.resize(num) |
將元素的位置改為num個(如果size變大了,多出來的元素需要default建構函式來完成構造)) |
|
c.resize(num,elem) |
將元素的位置改為num個(如果size變大了,多出來的元素都是elem的副本)) |
|
c.clear() |
移除所有元素,將容器清空 |
List
1、結構
list使用一個double linked list(雙向連結串列)來管理元素。

2、 list 能力
list內部結構和vector或deque截然不同,所以與他們的區別:
list不支援隨機存取,需要存取某個元素,需要遍歷之前所有的元素,是很緩慢的行為。
任何位置上(不止是兩端)安插和刪除元素都非常快,始終都是在常數時間內完成,因為無需移動其他任何操作,實際上只進行了一些指標操作。
安插和刪除並不會造成指向其他元素的各個pointers、reference、iterators失效
list是原子操作,要麼成功,要麼失敗,不會說只執行一半。
list不支援隨機存取,不提供下標操作符和at()函式。
list不提供容量,記憶體分配的操作函式,因為完全沒必要,每個元素都有自己的記憶體空間,在刪除之前一直有效。
list提供專門的函式用於移動函式,這些函式執行效率高,無需元素的拷貝和移動,只需要調整若干指標。
3、操作函式
3.1 構造和析構
|
操作 |
效果 |
|
list<Elem> c |
產生一個空的list |
|
list<Elem> c1(c2) |
產生一個c2同型的list,每個元素都被複制 |
|
list<Elem> c(n) |
產生一個n個元素的list,每個元素都由default構造產生 |
|
list<Elem> c(n,elem) |
產生一個n個元素的list,每個元素都是elem的副本 |
|
list<Elem> c (beg,end) |
產生一個list以區間[beg,end)內所有元素作為初值 |
|
c.~list<Elem>() |
銷燬所有元素,釋放記憶體 |
3.2 非變動性操作
|
操作 |
效果 |
|
c.size() |
返回當前的元素數量 |
|
c.empty() |
判斷大小是否為零,等同於0 == size(),效率更高 |
|
c.max_size() |
返回能容納的元素最大數量 |
|
c1 == c2 |
判斷c1是否等於c2 |
|
c1 != c2 |
判斷c1是否不等於c2(等同於!(c1==c2)) |
|
c1 < c2 |
判斷c1是否小於c2 |
|
c1 > c2 |
判斷c1是否大於c2 |
|
c1 <= c2 |
判斷c1是否小於等於c2(等同於!(c2<c1)) |
|
c1 >= c2 |
判斷c1是否大於等於c2 (等同於!(c1<c2)) |
3.3 賦值
|
操作 |
效果 |
|
c1 = c2 |
將c2的元素全部賦值給c1 |
|
c.assign(n,elem) |
將elem的n個副本拷貝給c |
|
c.assign(beg,end) |
建立一個list,區間[beg,end)內的所有元素作為初值 |
|
c1.swap(c2) |
c1和c2元素互換 |
|
swap(c1,c2) |
c1和c2元素互換,全域性函式 |
3.3 元素存取
list不支援隨機存取,只有front()和back()能直接存取元素。
|
操作 |
效果 |
|
c.front() |
返回第一個元素,不檢查元素是否存在 |
|
c.back() |
返回最後一個元素,不檢查元素是否存在 |
3.4 迭代器相關函式
list只有使用迭代器才能對元素進行存取,list不支援隨機存取,所以這些迭代器是雙向迭代器,凡是用到隨機存取迭代器的演算法都不能使用。
|
操作 |
效果 |
|
c.begin() |
返回一個隨機存取迭代器,指向第一個元素 |
|
c.end() |
返回一個隨機存取迭代器,指向最後一個元素的下一個位置 |
|
c.rbegin() |
返回一個逆向迭代器,指向逆向迭代的第一個元素 |
|
c.rend() |
返回一個逆向迭代器,指向逆向迭代的最後一個元素的下一個位置 |
3.5 元素的安插和移除
list提供了deque的所有功能,還增加了remove()和remove_if()應用於list。
|
操作 |
效果 |
|
c.insert(pos, elem) |
在迭代器pos位置插入一個elem副本,返回新元素位置 |
|
c.insert(pos,n, elem) |
在迭代器pos位置插入n個elem副本,無返回值 |
|
c.insert(pos, beg,end) |
在迭代器pos位置插入區間[beg,end)內所有元素的副本,無返回值 |
|
c.push_back(elem) |
在尾部追加一個elem副本 |
|
c.pop_back() |
移除最後一個元素,不返回 |
|
c.push_front(elem) |
在頭部安插一個elem副本 |
|
c.pop_front() |
移除第一個元素,不返回 |
|
c.remove(val) |
移除所有值為val的元素 |
|
c.remove_if(op) |
移除所有“造成op(elem)為true”的元素 |
|
c.erase(pos) |
移除迭代器pos所指元素,返回下一元素位置 |
|
c.erase(beg,end) |
移除區間[beg,end)內的所有元素,返回下一元素位置 |
|
c.resize(num) |
將元素容量重置為num個,如果size變大,則以default建構函式構造所有元素 |
|
c.resize (num, elem) |
將元素容量重置為num個,如果size變大,則所有元素為elem的副本 |
|
c. clear () |
移除所有元素,將整個容器清空 |
3.6 特殊變動性操作
|
操作 |
效果 |
|
c.unique() |
如果存在若干相鄰而數值相等的元素,移除重複元素,只留下一個 |
|
c.unique(op) |
若存在若干相鄰元素,都使op()為true,移除重複元素,只留下一個 |
|
c1.splice(pos,c2) |
將所有c2元素移到c1容器pos迭代器之前 |
|
c1.splice(pos,c2,c2pos) |
將c2 pos位置元素移到c1元素pos位置,c1和c2可以相同 |
|
c1.splice(pos,c2,c2beg,c2end) |
將c2區間[c2beg,c2end)所有元素移到c1 pos位置之前,c1和c2可以相同 |
|
c.sort() |
以operator < 為準,對所有元素排序 |
|
c.sort(op) |
以op()為準,對c排序 |
|
c1.merge(c2) |
假設c1和c2已序,將c2元素移動到c1,並保證合併後的list仍為已序 |
|
c1.merge(c2,op) |
假設c1和c2都以op()為序,將c2移動到c1仍然以op()已序 |
|
c.reverse() |
將所有元素反序 |
Set和Multiset
1、結構
set和multiset會根據特定的排序原則將元素排序。兩者不同之處在於,multisets允許元素重複,而set不允許重複。

只要是assignable、copyable、comparable(根據某個排序準則)的型別T,都可以成為set或者multisets的元素。如果沒有特別的排序原則,採用預設的less,已operator < 對元素進行比較,以便完成排序。
排序準則必須遵守以下原則:
- 必須是“反對稱的”,對operator <而言,如果x < y為真,y<x為假。
- 必須是“可傳遞的”,對operator <而言,如果x<y為真,y<z為真,那麼x<z也為真。
- 必須是“非自反的”,對operator<而言,x<x永遠為假。
2、能力
和所有的標準關聯容器類似,sets和multisets通常以平衡二叉樹完成。
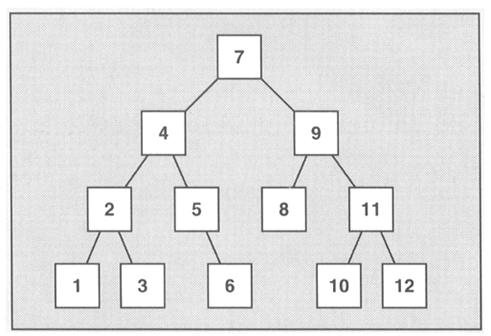
自動排序的主要優點在於使二叉樹搜尋元素具有良好的效能,在其搜尋函式演算法具有對數複雜度。但是自動排序也造成了一個限制,不能直接改變元素值,因為這樣會打亂原有的順序,要改變元素的值,必須先刪除舊元素,再插入新元素。所以sets和multisets具有以下特點:
- 不提供直接用來存取元素的任何操作元素
- 通過迭代器進行元素的存取。
3、操作函式
3.1 構造、拷貝、析構
|
操作 |
效果 |
|
set c |
產生一個空的set/multiset,不含任何元素 |
|
set c(op) |
以op為排序準則,產生一個空的set/multiset |
|
set c1(c2) |
產生某個set/multiset的副本,所有元素都被拷貝 |
|
set c(beg,end) |
以區間[beg,end)內的所有元素產生一個set/multiset |
|
set c(beg,end, op) |
以op為排序準則,區間[beg,end)內的元素產生一個set/multiset |
|
c.~set() |
銷燬所有元素,釋放記憶體 |
|
set<Elem> |
產生一個set,以(operator <)為排序準則 |
|
set<Elem,0p> |
產生一個set,以op為排序準則 |
3.2 非變動性操作
|
操作 |
效果 |
|
c.size() |
返回當前的元素數量 |
|
c.empty () |
判斷大小是否為零,等同於0 == size(),效率更高 |
|
c.max_size() |
返回能容納的元素最大數量 |
|
c1 == c2 |
判斷c1是否等於c2 |
|
c1 != c2 |
判斷c1是否不等於c2(等同於!(c1==c2)) |
|
c1 < c2 |
判斷c1是否小於c2 |
|
c1 > c2 |
判斷c1是否大於c2 |
|
c1 <= c2 |
判斷c1是否小於等於c2(等同於!(c2<c1)) |
|
c1 >= c2 |
判斷c1是否大於等於c2 (等同於!(c1<c2)) |
3.3 特殊的搜尋函式
sets和multisets在元素快速搜尋方面做了優化設計,提供了特殊的搜尋函式,所以應優先使用這些搜尋函式,可獲得對數複雜度,而非STL的線性複雜度。比如在1000個元素搜尋,對數複雜度平均十次,而線性複雜度平均需要500次。
|
操作 |
效果 |
|
count (elem) |
返回元素值為elem的個數 |
|
find(elem) |
返回元素值為elem的第一個元素,如果沒有返回end() |
|
lower _bound(elem) |
返回元素值為elem的第一個可安插位置,也就是元素值 >= elem的第一個元素位置 |
|
upper _bound (elem) |
返回元素值為elem的最後一個可安插位置,也就是元素值 > elem 的第一個元素位置 |
|
equal_range (elem) |
返回elem可安插的第一個位置和最後一個位置,也就是元素值==elem的區間 |
3.4 賦值
|
操作 |
效果 |
|
c1 = c2 |
將c2的元素全部給c1 |
|
c1.swap(c2) |
將c1和c2 的元素互換 |
|
swap(c1,c2) |
同上,全域性函式 |
3.5 迭代器相關函式
sets和multisets的迭代器是雙向迭代器,對迭代器操作而言,所有的元素都被視為常數,可以確保你不會人為改變元素值,從而打亂既定順序,所以無法呼叫變動性演算法,如remove()。
|
操作 |
效果 |
|
c.begin() |
返回一個隨機存取迭代器,指向第一個元素 |
|
c.end() |
返回一個隨機存取迭代器,指向最後一個元素的下一個位置 |
|
c.rbegin() |
返回一個逆向迭代器,指向逆向迭代的第一個元素 |
|
c.rend() |
返回一個逆向迭代器,指向逆向迭代的最後一個元素的下一個位置 |
3.6 安插和刪除元素
必須保證引數有效,迭代器必須指向有效位置,序列起點不能位於終點之後,不能從空容器刪除元素。
|
操作 |
效果 |
|
c.insert(elem) |
插入一個elem副本,返回新元素位置,無論插入成功與否。 |
|
c.insert(pos, elem) |
安插一個elem元素副本,返回新元素位置,pos為收索起點,提升插入速度。 |
|
c.insert(beg,end) |
將區間[beg,end)所有的元素安插到c,無返回值。 |
|
c.erase(elem) |
刪除與elem相等的所有元素,返回被移除的元素個數。 |
|
c.erase(pos) |
移除迭代器pos所指位置元素,無返回值。 |
|
c.erase(beg,end) |
移除區間[beg,end)所有元素,無返回值。 |
|
c.clear() |
移除所有元素,將容器清空 |
Map和Multimap
1、結構
Map和multimap將key/value pair(鍵值/實值 隊組)當作元素,進行管理。他們根據key的排序準則將元素排序。multimap允許重複元素,map不允許。
元素要求:
- key/value必須具有assigned(可賦值)和copyable(可複製的)性質。
- 對於排序而言,key必須具是comparable(可比較的)。
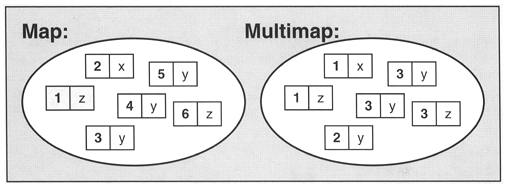
2、能力
典型情況下,set,multisets,map,multimap使用相同的內部結構,因此可以將set和multiset當成特殊的map和multimap,只不過set的value和key指向的是同一元素。
map和multimap會根據key對元素進行自動排序,所以根據key值搜尋某個元素具有良好的效能,但是如果根據value來搜尋效率就很低了。
同樣,自動排序使得你不能直接改變元素的key,因為這樣會破壞正確次序,要修改元素的key,必須先移除擁有key的元素,然後插入擁有新的key/value的元素,從迭代器的觀點來看,元素的key是常數,元素的value是可以直接修改的。

3、操作函式
3.1 構造、析構、拷貝
|
操作 |
效果 |
|
map c |
產生一個空的map/multimap不包含任何元素 |
|
map c(op) |
以op為排序準則,產生一個空的map/multimap |
|
map c1(c2) |
產生某個map/multimap的副本,所有元素都被拷貝 |
|
map c(beg,end) |
以區間[beg,end)內的元素產生一個map/multimap |
|
map c(beg,end,op) |
以op為排序準則,區間[beg,end)內的所有元素生成一個map/multimap |
|
c.~map() |
銷燬所有元素,釋放記憶體 |
|
map<Key,Elem> |
一個map/multimap,以less<> (operator <)為排序準則 |
|
map<Key,Elem,Op> |
一個map,以op為排序準則 |
3.2 非變動性操作
|
操作 |
效果 |
|
c.size() |
返回當前的元素數量 |
|
c.empty() |
判斷大小是否為零,等同於0 == size(),效率更高 |
|
c.max_size() |
返回能容納的元素最大數量 |
|
c1 == c2 |
判斷c1是否等於c2 |
|
c1 != c2 |
判斷c1是否不等於c2(等同於!(c1==c2)) |
|
c1 < c2 |
判斷c1是否小於c2 |
|
c1 > c2 |
判斷c1是否大於c2 |
|
c1 <= c2 |
判斷c1是否小於等於c2(等同於!(c2<c1)) |
|
c1 >= c2 |
判斷c1是否大於等於c2 (等同於!(c1<c2)) |
3.3 特殊搜尋函式
|
操作 |
效果 |
|
count(key) |
返回鍵值等於key的元素個數 |
|
find(key) |
返回鍵值等於key的第一個元素,沒找到返回end() |
|
lower_bound(key) |
返回鍵值為key之元素的第一個可安插位置,也就是鍵值>=key的第一個元素位置 |
|
upper_bound(key) |
返回鍵值為key之元素的最後一個可安插位置,也就是鍵值>key的第一個元素位置 |
|
equal_range(key) |
返回鍵值為key之元素的第一個可安插位置和最後一個可安插位置,也就是鍵值==key的元素區間 |
3.4 賦值
|
操作 |
效果 |
|
c1 = c2 |
將c2的元素全部給c1 |
|
c1.swap(c2) |
將c1和c2 的元素互換 |
|
swap(c1,c2) |
同上,全域性函式 |
3.5 迭代器函式
map和multimap不支援元素直接存取,因此元素的存取通常是經過迭代器進行。不過例外的是,map提供下標操作,可直接存取元素。同樣,他們的迭代器是雙向迭代器,所有的元素的key都被視為常數,不能呼叫任何變動性操作,如remove(),要移除元素,只能用塔門提供的函式。
|
操作 |
效果 |
|
c.begin() |
返回一個隨機存取迭代器,指向第一個元素 |
|
c.end() |
返回一個隨機存取迭代器,指向最後一個元素的下一個位置 |
|
c.rbegin() |
返回一個逆向迭代器,指向逆向迭代的第一個元素 |
|
c.rend() |
返回一個逆向迭代器,指向逆向迭代的最後一個元素的下一個位置 |
3.6 元素的安插和移除
|
操作 |
效果 |
|
c.insert(elem) |
插入一個elem副本,返回新元素位置,無論插入成功與否。 |
|
c.insert(pos, elem) |
安插一個elem元素副本,返回新元素位置,pos為收索起點,提升插入速度。 |
|
c.insert(beg,end) |
將區間[beg,end)所有的元素安插到c,無返回值。 |
|
c.erase(elem) |
刪除與elem相等的所有元素,返回被移除的元素個數。 |
|
c.erase(pos) |
移除迭代器pos所指位置元素,無返回值。 |
|
c.erase(beg,end) |
移除區間[beg,end)所有元素,無返回值。 |
|
c.clear() |
移除所有元素,將容器清空 |
有三個不同的方法將value插入map:
- 運用value_type,為了避免隱式轉換,可以使用value_type明白傳遞正確型別。value_type是容器本身提供的型別定義
std::map<std::string,float> coll;
...
coll.insert(std::map<std::string,float>::value_type("otto",22.3));- 運用pair,另一個作法是直接運用pair<>。
std::map<std::string,float> coll;
...
//use implicit conversion:
coll.insert(std::pair<std::string,float>("otto",22.3));
//use no implicit conversion:
coll.insert(std::pair<const std::string,float>("otto",22.3));
上述第一個insert()語句內的型別並不正確,所以會被轉換成真正的型別。- 運用make_pair()
最方便的方法是直接運用make_pair()函式,這個函式根據傳入的兩個引數構造一個pair物件。
std::map<std::string,float> coll;
...
coll.insert(std::make_pair("otto",22.3));
下面是個簡單例子,檢查安插元素是否成功:
std::map<std::string,float> coll;
...
if (coll.insert(std::make_pair("otto",22.3)).second) {
std::cout << "OK, could insert otto/22.3" << std::endl;
}
else {
std::cout << "Oops, could not insert otto/22.3 "
<< "(key otto already exists)" << std::endl;
}
如果要移除某個值為value的元素,使用erase()即可。
std::map<std::string,float> coll;
...
//remove all elements with the passed key
coll.erase(key);如果multimap內喊重複元素,不能使用erase()來刪除這些元素的第一個,但是可以這麼做:
typedef multimap<string.float> StringFloatMMap;
StringFloatMMap coll;
...
//remove first element with passed key
StringFloatMMap::iterator pos;
pos = coll.find(key);
if (pos != coll.end()) {
coll.erase(pos);
}
這裡使用成員函式的find()而非STL裡面的find(),因為成員函式更快,然而不能使用成員函式find()來移除擁有某個value(而非某個key)的元素。
移除元素時,要當心心意外發生,當移除迭代器所指物件時,可能使迭代器失效。
typedef std::map<std::string,float> StringFloatMap;
StringFloatMap coll;
StringFloatMap::iterator pos;
...
for (pos = coll.begin(); pos != coll.end(); ++pos) {
if (pos->second == value) {
coll. erase (pos); // RUNTIME ERROR !!!
}
}
對pos所指元素實施erase(),會使pos不再成為一個有效的迭代器,如果此後未對pos重新設值就使用pos,會出現異常。++pos就能導致一個未定義行為。下面是正確的刪除方法。
typedef std::map<std::string,float> StringFloatMap;
StringFloatMap coll;
StringFloatMap::iterator pos;
...
//remove all elements having a certain value
for (pos = c.begin(); pos != c.end(); ) {
if (pos->second == value) {
c.erase(pos++);
}
else {
++pos;
}
}
注意,pos++會指向下一個元素,但返回其原始值(指向原位置)的一個副本,因此,當erase()被呼叫,pos已經不指向那個即將被刪除的元素了。
4、map視為關聯陣列
通常,關聯陣列不提供直接存取,必須依靠迭代器,不過map是個例外,map提供下標操作符,可以直接存取元素。不過下標操作符的索引不是元素整數位置,而是元素的key。也就是說,索引可以是任何型別,而非侷限的整數型別。
|
操作 |
效果 |
|
m[key] |
返回一個reference,指向鍵值為key的元素,如果該元素尚未存在,插入該元素。 |
和一般陣列的區別不僅僅是索引型別,你不能使用一個錯誤的索引,如果你是用某個key為索引,容器尚未存在該元素,會自動安插該元素,新元素由default構造,所有基本型別都提供default建構函式,以零為初始值。
關聯陣列的行為方式有優點,也有缺點:
優點是可以透過方便的介面向map安插新元素。
std::map<std::string,float> coll; // empty collection
/*insert "otto"/7.7 as key/value pair
*-first it inserts "otto"/float()
*-then it assigns 7.7
*/
coll["otto"] = 7.7;
其中的語句:coll["otto"] = 7.7;處理如下:
1.處理coll["otto"]:
--如果存在鍵值為“otto”的元素,以上式子返回該元素的reference。
--如果沒有任何元素的鍵值為“otto”,以上式子便為map自動安插一個新元素,鍵值key為“otto”,value通過default建構函式完成,並返回一個reference指向新元素。
2.將7.7賦值給value:
--緊接著,將7.7賦值給剛才返回的元素。
這樣,map之內就包含了一個鍵值(key)為“otto”的元素,其值(value)為7.7。
缺點就是你可能不小心誤置新元素。例如你想列印key為“otto”的元素值:
std::cout << coll[“ottto”] << endl;
它會安插一個鍵值為“ottto”的元素,然後列印其值,預設情況下是0。它並不會告訴你拼寫錯誤,並且插入一個你可能不需要的元素。
這種插入方式比一般的map安插方式來得慢,因為在生成新元素的時候,需要使用default建構函式將新元素初始化,而這個值馬上又會被真正的value覆蓋。
String
1:string物件的定義和初始化以及讀寫
string s1; 預設建構函式,s1為空串
string s2(s1); 將s2初始化為s1的一個副本
string s3("valuee"); 將s3初始化一個字串面值副本
string s4(n,'c'); 將s4 初始化為字元'c'的n個副本
cin>>s5; 讀取有效字元到遇到空格
getline(cin,s6); 讀取字元到遇到換行,空格可讀入,知道‘\n’結束(練習在下一個程式碼中),
getline(cin,s7,'a'); 一個直到‘a’結束,其中任何字元包括'\n'都能夠讀入,可以試試題:UVa10361
2:string物件操作
s.empty() 判斷是否為空,bool型
s.size() 或 s.length() 返回字元的個數
s[n] 返回位置為n的字元,從0開始計數
s1+s2 連線,看下面例子:
可用此方法給字串後面新增字元如:s=s+'a';
a: string s2=s1+", "; //對,把一個string物件和一個字元面值連線起來是允許的
b: string s4="hello "+", "; //錯,不能將兩個字串面值相加
c: string s5=s1+", "+"world"; //對,前面兩個相加相當於一個string物件;
d: string s6="hello" + ", " + s2; //錯
(注:字串尾部追加還可用s.append("abc")函式新增)
s1=s2 替換
s1==s2 相等,返回true或false
!=,<,<=,>,>= 字串比較,兩個字串短的與長的前面匹配,短的小於長的
3:string物件中字元的處理(標頭檔案cctype)
isalnum(c) 如果c是字母或數字,返回 true
isalpha(c) 如果c是字母,返回true
iscntrl(c) c是控制符,返回true
isdigit(c) 如果c是數字,返回true
isgraph(c) 如果c不是空格,則可列印,,則為true
islower(c) 如果c是小寫字母,則為true
<