
Python-網路程式設計(二)
今天繼續網路程式設計的東西
一.網路通訊原理
1.網際網路的本質就是一系列的網路協議
我們是在瀏覽器上輸入了一個網址,但是我們都知道,網際網路連線的電腦互相通訊的是電訊號,我們的電腦是怎麼將我們輸入的網址變成了電訊號然後傳送出去了呢,並且我們傳送出去的訊息是不是應該讓對方的伺服器能夠知道,我們是在請求它的網站呢,也就是說京東是不是應該知道我傳送的訊息是什麼意思呢。是不是傳送的訊息應該有一些固定的格式呢?讓所有電腦都能識別的訊息格式,他就像英語成為世界上所有人通訊的統一標準一樣,如果把計算機看成分佈於世界各地的人,那麼連線兩臺計算機之間的internet實際上就是一系列統一的標準,這些標準稱之為網際網路協議,網際網路的本質就是一系列的協議,總稱為‘網際網路協議’(Internet Protocol Suite)。
網際網路協議的功能:定義計算機如何接入internet,以及接入internet的計算機通訊的標準。
網路通訊的流程昨天已經說過了,出門左轉就能看到,這裡就不再說了.
2.osi七層協議
網際網路協議按照功能不同分為osi七層或tcp/ip五層或tcp/ip四層
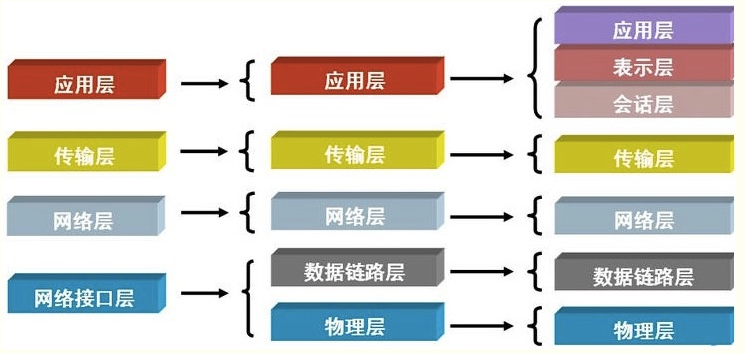
我們現在只需要瞭解五層的協議就好了,ok嗎?我們寫的程式屬於哪一層呢,屬於應用層。
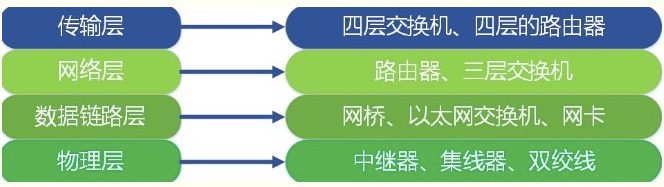
每層執行常見物理裝置
3.tcp/ip五層模型講解
我們將應用層,表示層,會話層並作應用層,從tcp/ip五層協議的角度來闡述每層的由來與功能,搞清楚了每層的主要協議
就理解了整個網際網路通訊的原理。
首先,使用者感知到的只是最上面一層應用層,自上而下每層都依賴於下一層,所以我們從最下一層開始切入,比較好理解
每層都執行特定的協議,越往上越靠近使用者,越往下越靠近硬體
3.1 物理層

物理層功能:主要是基於電器特性發送高低電壓(電訊號),高電壓對應數字1,低電壓對應數字0
3.2 資料鏈路層
資料鏈路層的功能:定義了電訊號的分組方式
乙太網協議:
早期的時候各個公司都有自己的分組方式,後來形成了統一的標準,即乙太網協議ethernet
ethernet規定
一組電訊號構成一個數據包,叫做‘幀’
每一資料幀分成:報頭head和資料data兩部分
mac地址:
mac地址:每塊網絡卡出廠時都被燒製上一個世界唯一的mac地址,長度為48位2進位制,通常由12位16進位制數表示(前六位是廠商編號,後六位是流水線號)
3.3 網路層
IP協議:
規定網路地址的協議叫ip協議,它定義的地址稱之為ip地址,廣泛採用的v4版本即ipv4,它規定網路地址由32位2進製表示
範圍0.0.0.0-255.255.255.255 (4個點分十進位制,也就是4個8位二進位制數)
一個ip地址通常寫成四段十進位制數,例:172.16.10.1
ipv6,通過上面可以看出,ip緊缺,所以為了滿足更多ip需要,出現了ipv6協議:6個冒號分割的16進位制數表示,這個應該是將來的趨勢,但是ipv4還是用的最多的,因為我們一般一個公司就一個對外的IP地址,我們所有的機器上網都走這一個IP出口。
ip資料包
ip資料包也分為head和data部分,無須為ip包定義單獨的欄位,直接放入乙太網包的data部分
head:長度為20到60位元組
data:最長為65,515位元組。
而乙太網資料包的”資料”部分,最長只有1500位元組。因此,如果IP資料包超過了1500位元組,它就需要分割成幾個乙太網資料包,分開發送了。
3.4 傳輸層
tcp協議:(TCP把連線作為最基本的物件,每一條TCP連線都有兩個端點,這種端點我們叫作套接字(socket),它的定義為埠號拼接到IP地址即構成了套接字,例如,若IP地址為192.3.4.16 而埠號為80,那麼得到的套接字為192.3.4.16:80。)
當應用程式希望通過 TCP 與另一個應用程式通訊時,它會發送一個通訊請求。這個請求必須被送到一個確切的地址。在雙方“握手”之後,TCP 將在兩個應用程式之間建立一個全雙工 (full-duplex,雙方都可以收發訊息) 的通訊。
這個全雙工的通訊將佔用兩個計算機之間的通訊線路,直到它被一方或雙方關閉為止。
它是可靠傳輸,TCP資料包沒有長度限制,理論上可以無限長,但是為了保證網路的效率,通常TCP資料包的長度不會超過IP資料包的長度,以確保單個TCP資料包不必再分割。
udp協議:不可靠傳輸,”報頭”部分一共只有8個位元組,總長度不超過65,535位元組,正好放進一個IP資料包。
tcp三次握手和四次揮手
我們知道網路層,可以實現兩個主機之間的通訊。但是這並不具體,因為,真正進行通訊的實體是在主機中的程序,是一個主機中的一個程序與另外一個主機中的一個程序在交換資料。IP協議雖然能把資料報文送到目的主機,但是並沒有交付給主機的具體應用程序。而端到端的通訊才應該是應用程序之間的通訊。
UDP,在傳送資料前不需要先建立連線,遠地的主機在收到UDP報文後也不需要給出任何確認。雖然UDP不提供可靠交付,但是正是因為這樣,省去和很多的開銷,使得它的速度比較快,比如一些對實時性要求較高的服務,就常常使用的是UDP。對應的應用層的協議主要有 DNS,TFTP,DHCP,SNMP,NFS 等。
TCP,提供面向連線的服務,在傳送資料之前必須先建立連線,資料傳送完成後要釋放連線。因此TCP是一種可靠的的運輸服務,但是正因為這樣,不可避免的增加了許多的開銷,比如確認,流量控制等。對應的應用層的協議主要有 SMTP,TELNET,HTTP,FTP 等。
三次握手:
1.TCP伺服器程序先建立傳輸控制塊TCB,時刻準備接受客戶程序的連線請求,此時伺服器就進入了 LISTEN(監聽)狀態;
2.TCP客戶程序也是先建立傳輸控制塊TCB,然後向伺服器發出連線請求報文,這是報文首部中的同部位SYN=1,同時選擇一個初始序列號 seq=x ,此時,TCP客戶端程序進入了 SYN-SENT(同步已傳送狀態)狀態。TCP規定,SYN報文段(SYN=1的報文段)不能攜帶資料,但需要消耗掉一個序號。
3.TCP伺服器收到請求報文後,如果同意連線,則發出確認報文。確認報文中應該 ACK=1,SYN=1,確認號是ack=x+1,同時也要為自己初始化一個序列號 seq=y,此時,TCP伺服器程序進入了SYN-RCVD(同步收到)狀態。這個報文也不能攜帶資料,但是同樣要消耗一個序號。
4.TCP客戶程序收到確認後,還要向伺服器給出確認。確認報文的ACK=1,ack=y+1,自己的序列號seq=x+1,此時,TCP連線建立,客戶端進入ESTABLISHED(已建立連線)狀態。TCP規定,ACK報文段可以攜帶資料,但是如果不攜帶資料則不消耗序號。
5.當伺服器收到客戶端的確認後也進入ESTABLISHED狀態,此後雙方就可以開始通訊了。
四次揮手:
資料傳輸完畢後,雙方都可釋放連線。最開始的時候,客戶端和伺服器都是處於ESTABLISHED狀態,然後客戶端主動關閉,伺服器被動關閉。服務端也可以主動關閉,一個流程。
1.客戶端程序發出連線釋放報文,並且停止傳送資料。釋放資料報文首部,FIN=1,其序列號為seq=u(等於前面已經傳送過來的資料的最後一個位元組的序號加1),此時,客戶端進入FIN-WAIT-1(終止等待1)狀態。 TCP規定,FIN報文段即使不攜帶資料,也要消耗一個序號。
2.伺服器收到連線釋放報文,發出確認報文,ACK=1,ack=u+1,並且帶上自己的序列號seq=v,此時,服務端就進入了CLOSE-WAIT(關閉等待)狀態。TCP伺服器通知高層的應用程序,客戶端向伺服器的方向就釋放了,這時候處於半關閉狀態,即客戶端已經沒有資料要傳送了,但是伺服器若傳送資料,客戶端依然要接受。這個狀態還要持續一段時間,也就是整個CLOSE-WAIT狀態持續的時間。
3.客戶端收到伺服器的確認請求後,此時,客戶端就進入FIN-WAIT-2(終止等待2)狀態,等待伺服器傳送連線釋放報文(在這之前還需要接受伺服器傳送的最後的資料)。
4.伺服器將最後的資料傳送完畢後,就向客戶端傳送連線釋放報文,FIN=1,ack=u+1,由於在半關閉狀態,伺服器很可能又傳送了一些資料,假定此時的序列號為seq=w,此時,伺服器就進入了LAST-ACK(最後確認)狀態,等待客戶端的確認。
5.客戶端收到伺服器的連線釋放報文後,必須發出確認,ACK=1,ack=w+1,而自己的序列號是seq=u+1,此時,客戶端就進入了TIME-WAIT(時間等待)狀態。注意此時TCP連線還沒有釋放,必須經過2∗∗MSL(最長報文段壽命)的時間後,當客戶端撤銷相應的TCB後,才進入CLOSED狀態。
6.伺服器只要收到了客戶端發出的確認,立即進入CLOSED狀態。同樣,撤銷TCB後,就結束了這次的TCP連線。可以看到,伺服器結束TCP連線的時間要比客戶端早一些。

3.5 應用層
應用層由來:使用者使用的都是應用程式,均工作於應用層,網際網路是開發的,大家都可以開發自己的應用程式,資料多種多樣,必須規定好資料的組織形式
應用層功能:規定應用程式的資料格式。
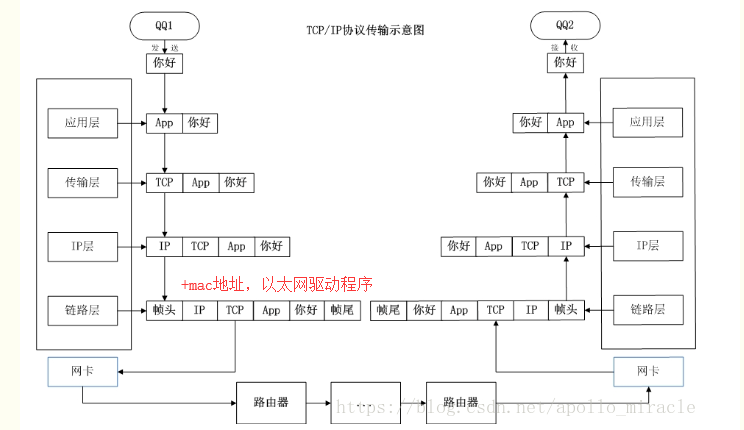
五層通訊流程:
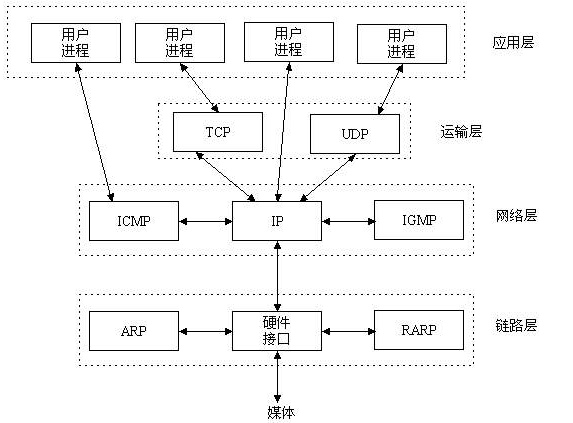
二. socket
結合上圖來看,socket在哪一層呢,我們繼續看下圖
socket在內的五層通訊流程:
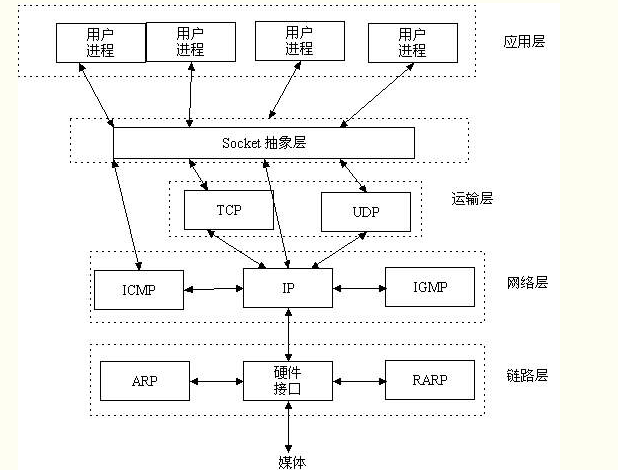
Socket又稱為套接字,它是應用層與TCP/IP協議族通訊的中間軟體抽象層,它是一組介面。在設計模式中,Socket其實就是一個門面模式,它把複雜的TCP/IP協議族隱藏在Socket介面後面,對使用者來說,一組簡單的介面就是全部,讓Socket去組織資料,以符合指定的協議。當我們使用不同的協議進行通訊時就得使用不同的介面,還得處理不同協議的各種細節,這就增加了開發的難度,軟體也不易於擴充套件(就像我們開發一套公司管理系統一樣,報賬、會議預定、請假等功能不需要單獨寫系統,而是一個系統上多個功能介面,不需要知道每個功能如何去實現的)。於是UNIX BSD就發明了socket這種東西,socket遮蔽了各個協議的通訊細節,使得程式設計師無需關注協議本身,直接使用socket提供的介面來進行互聯的不同主機間的程序的通訊。這就好比作業系統給我們提供了使用底層硬體功能的系統呼叫,通過系統呼叫我們可以方便的使用磁碟(檔案操作),使用記憶體,而無需自己去進行磁碟讀寫,記憶體管理。socket其實也是一樣的東西,就是提供了tcp/ip協議的抽象,對外提供了一套介面,同過這個介面就可以統一、方便的使用tcp/ip協議的功能了。
其實站在你的角度上看,socket就是一個模組。我們通過呼叫模組中已經實現的方法建立兩個程序之間的連線和通訊。也有人將socket說成ip+port,因為ip是用來標識網際網路中的一臺主機的位置,而port是用來標識這臺機器上的一個應用程式。 所以我們只要確立了ip和port就能找到一個應用程式,並且使用socket模組來與之通訊。
三.套接字socket的發展史及分類
基於檔案型別的套接字家族
套接字家族的名字:AF_UNIX
基於網路型別的套接字家族
套接字家族的名字:AF_INET
四.基於TCP和UDP兩個協議下socket的通訊流程
1.TCP和UDP對比
TCP(Transmission Control Protocol)可靠的、面向連線的協議(eg:打電話)、傳輸效率低全雙工通訊(傳送快取&接收快取)、面向位元組流。使用TCP的應用:Web瀏覽器;檔案傳輸程式。
UDP(User Datagram Protocol)不可靠的、無連線的服務,傳輸效率高(傳送前時延小),一對一、一對多、多對一、多對多、面向報文(資料包),盡最大努力服務,無擁塞控制。使用UDP的應用:域名系統 (DNS);視訊流;IP語音(VoIP)。
直接看圖對比其中差異

繼續往下看
TCP和UDP下socket差異對比圖:

2.TCP協議下的socket
基於TCP的socket通訊流程圖片:

雖然上圖將通訊流程中的大致描述了一下socket各個方法的作用,但是還是要總結一下通訊流程(下面一段內容)
先從伺服器端說起。伺服器端先初始化Socket,然後與埠繫結(bind),對埠進行監聽(listen),呼叫accept阻塞,等待客戶端連線。在這時如果有個客戶端初始化一個Socket,然後連線伺服器(connect),如果連線成功,這時客戶端與伺服器端的連線就建立了。客戶端傳送資料請求,伺服器端接收請求並處理請求,然後把迴應資料傳送給客戶端,客戶端讀取資料,最後關閉連線,一次互動結束
上程式碼感受一下,需要建立兩個檔案,檔名稱隨便起,為了方便看,我的兩個檔名稱為tcp_server.py(服務端)和tcp_client.py(客戶端),將下面的server端的程式碼拷貝到tcp_server.py檔案中,將下面client端的程式碼拷貝到tcp_client.py的檔案中,然後先執行tcp_server.py檔案中的程式碼,再執行tcp_client.py檔案中的程式碼,然後在pycharm下面的輸出視窗看一下效果。
server端程式碼示例(如果比喻成打電話)
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8898)) #把地址繫結到套接字
sk.listen() #監聽連結
conn,addr = sk.accept() #接受客戶端連結
ret = conn.recv(1024) #接收客戶端資訊
print(ret) #列印客戶端資訊
conn.send(b'hi') #向客戶端傳送資訊
conn.close() #關閉客戶端套接字
sk.close() #關閉伺服器套接字(可選)
client端程式碼示例
import socket
sk = socket.socket() # 建立客戶套接字
sk.connect(('127.0.0.1',8898)) # 嘗試連線伺服器
sk.send(b'hello!')
ret = sk.recv(1024) # 對話(傳送/接收)
print(ret)
sk.close() # 關閉客戶套接字
socket繫結IP和埠時可能出現下面的問題:

解決辦法:
#加入一條socket配置,重用ip和埠
import socket
from socket import SOL_SOCKET,SO_REUSEADDR
sk = socket.socket()
sk.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #在bind前加,允許地址重用
sk.bind(('127.0.0.1',8898)) #把地址繫結到套接字
sk.listen() #監聽連結
conn,addr = sk.accept() #接受客戶端連結
ret = conn.recv(1024) #接收客戶端資訊
print(ret) #列印客戶端資訊
conn.send(b'hi') #向客戶端傳送資訊
conn.close() #關閉客戶端套接字
sk.close() #關閉伺服器套接字(可選)
但是如果你加上了上面的程式碼之後還是出現這個問題:OSError: [WinError 10013] 以一種訪問許可權不允許的方式做了一個訪問套接字的嘗試。那麼只能換埠了,因為你的電腦不支援埠重用。
記住一點,用socket進行通訊,必須是一收一發對應好。
提一下:網路相關或者需要和電腦上其他程式通訊的程式才需要開一個埠。
在看UDP協議下的socket之前,我們還需要加一些內容來講:看程式碼
server端
import socket
from socket import SOL_SOCKET,SO_REUSEADDR
sk = socket.socket()
# sk.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
sk.bind(('127.0.0.1',8090))
sk.listen()
conn,addr = sk.accept() #在這阻塞,等待客戶端過來連線
while True:
ret = conn.recv(1024) #接收訊息 在這還是要阻塞,等待收訊息
ret = ret.decode('utf-8') #位元組型別轉換為字串中文
print(ret)
if ret == 'bye': #如果接到的訊息為bye,退出
break
msg = input('服務端>>') #服務端發訊息
conn.send(msg.encode('utf-8'))
if msg == 'bye':
break
conn.close()
sk.close()
client端
import socket
sk = socket.socket()
sk.connect(('127.0.0.1',8090)) #連線服務端
while True:
msg = input('客戶端>>>') #input阻塞,等待輸入內容
sk.send(msg.encode('utf-8'))
if msg == 'bye':
break
ret = sk.recv(1024)
ret = ret.decode('utf-8')
print(ret)
if ret == 'bye':
break
sk.close()
你會發現,第一個連線的客戶端可以和服務端收發訊息,但是第二個連線的客戶端發訊息服務端是收不到的
原因解釋: tcp屬於長連線,長連線就是一直佔用著這個連結,這個連線的埠被佔用了,第二個客戶端過來連線的時候,他是可以連線的,但是處於一個佔線的狀態,就只能等著去跟服務端建立連線,除非一個客戶端斷開了(優雅的斷開可以,如果是強制斷開就會報錯,因為服務端的程式還在第一個迴圈裡面),然後就可以進行和服務端的通訊了。什麼是優雅的斷開呢?看程式碼。 server端程式碼: import socket
from socket import SOL_SOCKET,SO_REUSEADDR
sk = socket.socket()
# sk.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #允許地址重用,這個東西都說能解決問題,我非常不建議大家這麼做,容易出問題
sk.bind(('127.0.0.1',8090))
sk.listen()
# 第二步演示,再加一層while迴圈
while True: #下面的程式碼全部縮排進去,也就是迴圈建立連線,但是不管怎麼聊,只能和一個聊,也就是另外一個優雅的斷了之後才能和另外一個聊
#它不能同時和好多人聊,還是長連線的原因,一直佔用著這個埠的連線,udp是可以的,然後我們學習udp
conn,addr = sk.accept() #在這阻塞,等待客戶端過來連線
while True:
ret = conn.recv(1024) #接收訊息 在這還是要阻塞,等待收訊息
ret = ret.decode('utf-8') #位元組型別轉換為字串中文
print(ret)
if ret == 'bye': #如果接到的訊息為bye,退出
break
msg = input('服務端>>') #服務端發訊息
conn.send(msg.encode('utf-8'))
if msg == 'bye':
break
conn.close()
client端程式碼
import socket
sk = socket.socket()
sk.connect(('127.0.0.1',8090)) #連線服務端
while True:
msg = input('客戶端>>>') #input阻塞,等待輸入內容
sk.send(msg.encode('utf-8'))
if msg == 'bye':
break
ret = sk.recv(1024)
ret = ret.decode('utf-8')
print(ret)
if ret == 'bye':
break
# sk.close()
強制斷開連線之後的報錯資訊:

3.UDP協議下的socket
老樣子!先上圖!
基於UDP的socket通訊流程:

總結一下UDP下的socket通訊流程
先從伺服器端說起。伺服器端先初始化Socket,然後與埠繫結(bind),recvform接收訊息,這個訊息有兩項,訊息內容和對方客戶端的地址,然後回覆訊息時也要帶著你收到的這個客戶端的地址,傳送回去,最後關閉連線,一次互動結束
上程式碼感受一下,需要建立兩個檔案,檔名稱隨便起,為了方便看,我的兩個檔名稱為udp_server.py(服務端)和udp_client.py(客戶端),將下面的server端的程式碼拷貝到udp_server.py檔案中,將下面cliet端的程式碼拷貝到udp_client.py的檔案中,然後先執行udp_server.py檔案中的程式碼,再執行udp_client.py檔案中的程式碼,然後在pycharm下面的輸出視窗看一下效果。
server端程式碼示例
import socket
udp_sk = socket.socket(type=socket.SOCK_DGRAM) #建立一個伺服器的套接字
udp_sk.bind(('127.0.0.1',9000)) #繫結伺服器套接字
msg,addr = udp_sk.recvfrom(1024)
print(msg)
udp_sk.sendto(b'hi',addr) # 對話(接收與傳送)
udp_sk.close() # 關閉伺服器套接字
client端程式碼示例
import socket
ip_port=('127.0.0.1',9000)
udp_sk=socket.socket(type=socket.SOCK_DGRAM)
udp_sk.sendto(b'hello',ip_port)
back_msg,addr=udp_sk.recvfrom(1024)
print(back_msg.decode('utf-8'),addr)
五.粘包現象
說粘包之前,我們先說兩個內容,1.緩衝區、2.windows下cmd視窗呼叫系統指令
5.1 緩衝區(下面粘包現象的圖裡面還有關於緩衝區的解釋)
5.2 windows下cmd視窗呼叫系統指令(linux下沒有寫出來,大家仿照windows的去摸索一下吧)
a.首先ctrl+r,彈出左下角的下圖,輸入cmd指令,確定
b.在開啟的cmd視窗中輸入dir(dir:檢視當前資料夾下的所有檔案和資料夾),你會看到下面的輸出結果。

另外還有ipconfig(檢視當前電腦的網路資訊),在windows沒有ls這個指令(ls在linux下是檢視當前資料夾下所有檔案和資料夾的指令,和windows下的dir是類似的),那麼沒有這個指令就會報下面這個錯誤

5.3 粘包現象(兩種)
先上圖:(本圖是我做出來為了讓小白同學有個大致的瞭解用的,其中很多地方更加的複雜,那就需要將來大家有多餘的精力的時候去做一些深入的研究了,這裡我就不帶大家搞啦)

MTU簡單解釋:
MTU是Maximum Transmission Unit的縮寫。意思是網路上傳送的最大資料包。MTU的單位是位元組。
大部分網路裝置的MTU都是1500個位元組,也就是1500B。如果本機一次需要傳送的資料比閘道器的MTU大,
大的資料包就會被拆開來傳送,這樣會產生很多資料包碎片,增加丟包率,降低網路速度
關於上圖中提到的Nagle演算法等建議大家去看一看Nagle演算法、延遲ACK、linux下的TCP_NODELAY和TCP_CORK,這些內容等你們把python學好以後再去研究吧,網路的內容實在太多啦,也就是說大家需要努力的過程還很長,加油!
超出緩衝區大小會報下面的錯誤,或者udp協議的時候,你的一個數據包的大小超過了你一次recv能接受的大小,也會報下面的錯誤,tcp不會,但是超出快取區大小的時候,肯定會報這個錯誤。

5.4 模擬一個粘包現象
在模擬粘包之前,我們先學習一個模組subprocess。import subprocess
cmd = input('請輸入指令>>>')
res = subprocess.Popen(
cmd, #字串指令:'dir','ipconfig',等等
shell=True, #使用shell,就相當於使用cmd視窗
stderr=subprocess.PIPE, #標準錯誤輸出,凡是輸入錯誤指令,錯誤指令輸出的報錯資訊就會被它拿到
stdout=subprocess.PIPE, #標準輸出,正確指令的輸出結果被它拿到
)
print(res.stdout.read().decode('gbk'))
print(res.stderr.read().decode('gbk'))
注意:
如果是windows,那麼res.stdout.read()讀出的就是GBK編碼的,在接收端需要用GBK解碼
且只能從管道里讀一次結果,PIPE稱為管道。
下面是subprocess和windows上cmd下的指令的對應示意圖:subprocess的stdout.read()和stderr.read(),拿到的結果是bytes型別,所以需要轉換為字串打印出來看。
好,既然我們會使用subprocess了,那麼我們就通過它來模擬一個粘包
tcp粘包演示(一):
先從上面粘包現象中的第一種開始: 接收方沒有及時接收緩衝區的包,造成多個包接收(客戶端傳送了一段資料,服務端只收了一小部分,服務端下次再收的時候還是從緩衝區拿上次遺留的資料,產生粘包) server端程式碼示例:cket import *
import subprocess
ip_port=('127.0.0.1',8080)
BUFSIZE=1024
tcp_socket_server=socket(AF_INET,SOCK_STREAM)
tcp_socket_server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
tcp_socket_server.bind(ip_port)
tcp_socket_server.listen(5)
while True:
conn,addr=tcp_socket_server.accept()
print('客戶端>>>',addr)
while True:
cmd=conn.recv(BUFSIZE)
if len(cmd) == 0:break
res=subprocess.Popen(cmd.decode('gbk'),shell=True,
stdout=subprocess.PIPE,
stdin=subprocess.PIPE,
stderr=subprocess.PIPE)
stderr=res.stderr.read()
stdout=res.stdout.read()
conn.send(stderr)
conn.send(stdout)
client端程式碼示例:
import socket
ip_port = ('127.0.0.1',8080)
size = 1024
tcp_sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
res = tcp_sk.connect(ip_port)
while True:
msg=input('>>: ').strip()
if len(msg) == 0:continue
if msg == 'quit':break
tcp_sk.send(msg.encode('utf-8'))
act_res=tcp_sk.recv(size)
print('接收的返回結果長度為>',len(act_res))
print('std>>>',act_res.decode('gbk')) #windows返回的內容需要用gbk來解碼,因為windows系統的預設編碼為gbk
tcp粘包演示(二):傳送資料時間間隔很短,資料也很小,會合到一起,產生粘包
server端程式碼示例:(如果兩次傳送有一定的時間間隔,那麼就不會出現這種粘包情況,試著在兩次傳送的中間加一個time.sleep(1))
from socket import *
ip_port=('127.0.0.1',8080)
tcp_socket_server=socket(AF_INET,SOCK_STREAM)
tcp_socket_server.bind(ip_port)
tcp_socket_server.listen(5)
conn,addr=tcp_socket_server.accept()
data1=conn.recv(10)
data2=conn.recv(10)
print('----->',data1.decode('utf-8'))
print('----->',data2.decode('utf-8'))
conn.close()
client端程式碼示例:
import socket
BUFSIZE=1024
ip_port=('127.0.0.1',8080)
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# res=s.connect_ex(ip_port)
res=s.connect(ip_port)
s.send('hi'.encode('utf-8'))
s.send('meinv'.encode('utf-8'))
示例二的結果:全部被第一個recv接收了

udp粘包演示:注意:udp是面向包的,所以udp是不存在粘包的 server端程式碼示例:
import socket
from socket import SOL_SOCKET,SO_REUSEADDR,SO_SNDBUF,SO_RCVBUF
sk = socket.socket(type=socket.SOCK_DGRAM)
# sk.setsockopt(SOL_SOCKET,SO_RCVBUF,80*1024)
sk.bind(('127.0.0.1',8090))
msg,addr = sk.recvfrom(1024)
while True:
cmd = input('>>>>')
if cmd == 'q':
break
sk.sendto(cmd.encode('utf-8'),addr)
msg,addr = sk.recvfrom(1032)
# print('>>>>', sk.getsockopt(SOL_SOCKET, SO_SNDBUF))
# print('>>>>', sk.getsockopt(SOL_SOCKET, SO_RCVBUF))
print(len(msg))
print(msg.decode('utf-8'))
sk.close()
client端程式碼示例:
import socket
from socket import SOL_SOCKET,SO_REUSEADDR,SO_SNDBUF,SO_RCVBUF
sk = socket.socket(type=socket.SOCK_DGRAM)
# sk.setsockopt(SOL_SOCKET,SO_RCVBUF,80*1024)
sk.bind(('127.0.0.1',8090))
msg,addr = sk.recvfrom(1024)
while True:
cmd = input('>>>>')
if cmd == 'q':
break
sk.sendto(cmd.encode('utf-8'),addr)
msg,addr = sk.recvfrom(1024)
# msg,addr = sk.recvfrom(1218)
# print('>>>>', sk.getsockopt(SOL_SOCKET, SO_SNDBUF))
# print('>>>>', sk.getsockopt(SOL_SOCKET, SO_RCVBUF))
print(len(msg))
print(msg.decode('utf-8'))
sk.close()
在udp的程式碼中,我們在server端接收返回訊息的時候,我們設定的recvfrom(1024),那麼當我輸入的執行指令為‘dir’的時候,dir在我當前資料夾下輸出的內容大於1024,然後就報錯了,報的錯誤也是下面這個:

解釋原因:是因為udp是面向報文的,意思就是每個訊息是一個包,你接收端設定接收大小的時候,必須要比你發的這個包要大,不然一次接收不了就會報這個錯誤,而tcp不會報錯,這也是為什麼ucp會丟包的原因之一,這個和我們上面緩衝區那個錯誤的報錯原因是不一樣的。
補充兩個問題:
補充問題一:為何tcp是可靠傳輸,udp是不可靠傳輸
tcp在資料傳輸時,傳送端先把資料傳送到自己的快取中,然後協議控制將快取中的資料發往對端,對端返回一個ack=1,傳送端則清理快取中的資料,對端返回ack=0,則重新發送資料,所以tcp是可靠的。
而udp傳送資料,對端是不會返回確認資訊的,因此不可靠
補充問題二:send(位元組流)和sendall
send的位元組流是先放入己端快取,然後由協議控制將快取內容發往對端,如果待發送的位元組流大小大於快取剩餘空間,那麼資料丟失,用sendall就會迴圈呼叫send,資料不會丟失,一般的小資料就用send,因為小資料也用sendall的話有些影響程式碼效能,簡單來講就是還多while迴圈這個程式碼呢。
用UDP協議傳送時,用sendto函式最大能傳送資料的長度為:65535- IP頭(20) – UDP頭(8)=65507位元組。用sendto函式傳送資料時,如果傳送資料長度大於該值,則函式會返回錯誤。(丟棄這個包,不進行傳送)
用TCP協議傳送時,由於TCP是資料流協議,因此不存在包大小的限制(暫不考慮緩衝區的大小),這是指在用send函式時,資料長度引數不受限制。而實際上,所指定的這段資料並不一定會一次性發送出去,如果這段資料比較長,會被分段傳送,如果比較短,可能會等待和下一次資料一起傳送。
粘包的原因:主要還是因為接收方不知道訊息之間的界限,不知道一次性提取多少位元組的資料所造成的
六.粘包的解決方案
解決方案(一):
問題的根源在於,接收端不知道傳送端將要傳送的位元組流的長度,所以解決粘包的方法就是圍繞,如何讓傳送端在傳送資料前,把自己將要傳送的位元組流總大小讓接收端知曉,然後接收端發一個確認訊息給傳送端,然後傳送端再發送過來後面的真實內容,接收端再來一個死迴圈接收完所有資料。
看程式碼示例:
server端程式碼import socket,subprocess
ip_port=('127.0.0.1',8080)
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
s.bind(ip_port)
s.listen(5)
while True:
conn,addr=s.accept()
print('客戶端',addr)
while True:
msg=conn.recv(1024)
if not msg:break
res=subprocess.Popen(msg.decode('utf-8'),shell=True,\
stdin=subprocess.PIPE,\
stderr=subprocess.PIPE,\
stdout=subprocess.PIPE)
err=res.stderr.read()
if err:
ret=err
else:
ret=res.stdout.read()
data_length=len(ret)
conn.send(str(data_length).encode('utf-8'))
data=conn.recv(1024).decode('utf-8')
if data == 'recv_ready':
conn.sendall(ret)
conn.close()
client端程式碼示例
import socket,time
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
res=s.connect_ex(('127.0.0.1',8080))
while True:
msg=input('>>: ').strip()
if len(msg) == 0:continue
if msg == 'quit':break
s.send(msg.encode('utf-8'))
length=int(s.recv(1024).decode('utf-8'))
s.send('recv_ready'.encode('utf-8'))
send_size=0
recv_size=0
data=b''
while recv_size < length:
data+=s.recv(1024)
recv_size+=len(data)
print(data.decode('utf-8'))
解決方案(二):
通過struck模組將需要傳送的內容的長度進行打包,打包成一個4位元組長度的資料傳送到對端,對端只要取出前4個位元組,然後對這四個位元組的資料進行解包,拿到你要傳送的內容的長度,然後通過這個長度來繼續接收我們實際要傳送的內容。不是很好理解是吧?哈哈,沒關係,看下面的解釋~~ 為什麼要說一下這個模組呢,因為解決方案(一)裡面你發現,我每次要先發送一個我的內容的長度,需要接收端接收,並切需要接收端返回一個確認訊息,我傳送端才能發後面真實的內容,這樣是為了保證資料可靠性,也就是接收雙方能順利溝通,但是多了一次傳送接收的過程,為了減少這個過程,我們就要使struck來發送你需要傳送的資料的長度,來解決上面我們所說的通過傳送內容長度來 解決粘包的問題。struck模組的使用:struct模組中最重要的兩個函式是pack()打包, unpack()解包。
pack():#我在這裡只介紹一下'i'這個int型別
import struct
a=12
# 將a變為二進位制
bytes=struct.pack('i',a)
-------------------------------------------------------------------------------
struct.pack('i',1111111111111) 如果int型別資料太大會報錯struck.error
struct.error: 'i' format requires -2147483648 <= number <= 2147483647 #這個是範圍
unpack():
# 注意,unpack返回的是tuple !!
a,=struct.unpack('i',bytes) #將bytes型別的資料解包後,拿到int型別資料
好,到這裡我們將struck這個模組將int型別的資料打包成四個位元組的方法了,那麼我們就來使用它解決粘包吧。
先看一段虛擬碼示例:
import json,struct
#假設通過客戶端上傳1T:1073741824000的檔案a.txt
#為避免粘包,必須自定製報頭
header={'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #1T資料,檔案路徑和md5值
#為了該報頭能傳送,需要序列化並且轉為bytes,因為bytes只能將字串型別的資料轉換為bytes型別的,所有需要先序列化一下這個字典,字典不能直接轉化為bytes
head_bytes=bytes(json.dumps(header),encoding='utf-8') #序列化並轉成bytes,用於傳輸
#為了讓客戶端知道報頭的長度,用struck將報頭長度這個數字轉成固定長度:4個位元組
head_len_bytes=struct.pack('i',len(head_bytes)) #這4個位元組裡只包含了一個數字,該數字是報頭的長度
#客戶端開始傳送
conn.send(head_len_bytes) #先發報頭的長度,4個bytes
conn.send(head_bytes) #再發報頭的位元組格式
conn.sendall(檔案內容) #然後發真實內容的位元組格式
#服務端開始接收
head_len_bytes=s.recv(4) #先收報頭4個bytes,得到報頭長度的位元組格式
x=struct.unpack('i',head_len_bytes)[0] #提取報頭的長度
head_bytes=s.recv(x) #按照報頭長度x,收取報頭的bytes格式
header=json.loads(json.dumps(header)) #提取報頭
#最後根據報頭的內容提取真實的資料,比如
real_data_len=s.recv(header['file_size'])
s.recv(real_data_len)
下面看正式的程式碼:
server端程式碼示例:報頭:就是訊息的頭部資訊,我們要傳送的真實內容為報頭後面的內容。
import socket,struct,json
import subprocess
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) #忘了這是幹什麼的了吧,地址重用?想起來了嗎~
phone.bind(('127.0.0.1',8080))
phone.listen(5)
while True:
conn,addr=phone.accept()
while True:
cmd=conn.recv(1024)
if not cmd:break
print('cmd: %s' %cmd)
res=subprocess.Popen(cmd.decode('utf-8'),
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
err=res.stderr.read()
if err:
back_msg=err
else:
back_msg=res.stdout.read()
conn.send(struct.pack('i',len(back_msg))) #先發back_msg的長度
conn.sendall(back_msg) #在發真實的內容
#其實就是連續的將長度和內容一起發出去,那麼整個內容的前4個位元組就是我們打包的後面內容的長度,對吧
conn.close()
client端程式碼示例:
import socket,time,struct
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
res=s.connect_ex(('127.0.0.1',8080))
while True:
msg=input('>>: ').strip()
if len(msg) == 0:continue
if msg == 'quit':break
s.send(msg.encode('utf-8')) #傳送給一個指令
l=s.recv(4) #先接收4個位元組的資料,因為我們將要傳送過來的內容打包成了4個位元組,所以先取出4個位元組
x=struct.unpack('i',l)[0] #解包,是一個元祖,第一個元素就是我們的內容的長度
print(type(x),x)
# print(struct.unpack('I',l))
r_s=0
data=b''
while r_s < x: #根據內容的長度來繼續接收4個位元組後面的內容。
r_d=s.recv(1024)
data+=r_d
r_s+=len(r_d)
# print(data.decode('utf-8'))
print(data.decode('gbk')) #windows預設gbk編碼
關於網路程式設計的內容有很多,在這裡只是大致說一下,如果你對這方面有興趣,可以在網上搜索一下,今天就到這裡