
JAVA集合體系回顧
這次來講一些java基礎知識,關於集合大家都不陌生了,幾乎每天都在使用, 本篇文章適合新手學習.
好了廢話不多說,下面開始介紹把.
什麼是集合?
儲存物件的容器,面嚮物件語言對事物的體現都是以物件的形式,所以為了方便對多個物件的操作,儲存物件,集合是儲存物件最常用的一種方式。
集合的出現就是為了持有物件。集合中可以儲存任意型別的物件, 而且長度可變。在程式中有可能無法預先知道需要多少個物件, 那麼用陣列來裝物件的話, 長度不好定義, 而集合解決了這樣的問題。
集合和陣列的區別
1.陣列和集合類都是容器。
2.陣列長度是固定的,集合長度是可變的。
3.陣列中可以儲存基本資料型別,集合只能儲存物件。
4.陣列中儲存資料型別是單一的,集合中可以儲存任意型別的物件。
5.陣列和集合在儲存物件的時候都儲存的都是物件的引用(記憶體地址),而非物件本身。
6.集合可以很方便的操作物件引用的增刪改查。
集合的體系圖
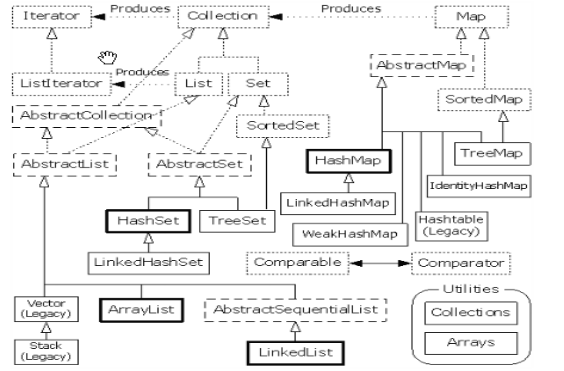
為什麼出現這麼多集合容器,因為每一個容器對資料的儲存方式不同,這種儲存方式稱之為資料結構(data structure)
單列集合和雙列集合
集合分為單列集合和雙列集合.單列集合的根介面是Collection,Collection的繼承關係圖:
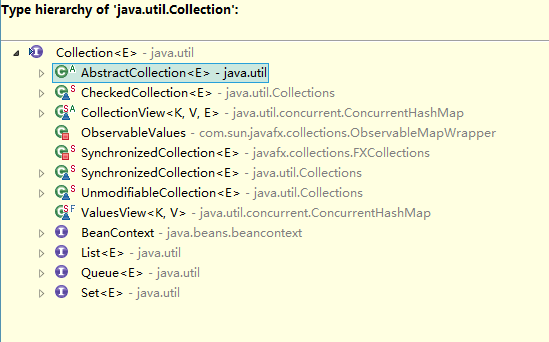
其中List和Set是2個Collection介面中最常用的子介面.
1.List集合的特點:儲存有序,元素可以重複
- ArrayList: 底層是陣列資料結構,查詢快,增刪慢,在增和刪的時候 會牽扯到陣列增容, 以及拷貝元素所以慢。陣列是可以直接按索引查詢, 所以查詢時較快,如果查詢較多, 那麼使用ArrayList
- LinkedList: 底層是連結串列資料結構,查詢慢,增刪快,增加時只要讓前一個元素記住自己就可以, 刪除時讓前一個元素記住後一個元 素, 後一個元素記住前一個元素. 這樣的增刪效率較高但查詢時需要一個一個的遍歷, 所以效率較低。如果增刪較多, 那麼使用LinkedList
- Vector: 底層是陣列資料結構,執行緒安全的,效率低,如果需要執行緒安全, 那麼使用Vector
2.Set集合的特點:元素不可以重複儲存,存取速度都快.
- HashSet: 底層是雜湊表資料結構,儲存元素無序,通過hashCode和equals方法保證元素的唯一性,Set集合的實現類,如果不需要對元素排序, 使用HashSet, HashSet比TreeSet效率高.
- TreeSet: 底層是二叉樹資料結構,儲存元素無序,但是元素有排序,通過比較性來保證元素的唯一性,Set集合的實現類,如果需要對元素排序, 那麼使用TreeSet.
- LinkedHashSet: 儲存元素有序,且元素不可重複,這點和上面2個不同,Set集合的實現類.
3.雙列集合的根介面Map的特點:存在鍵值的對映關係,鍵有唯一性,鍵相同則替換值,儲存無序.
- HashMap: 底層是雜湊表資料結構,存取快,儲存無序,通過hashCode和equals方法保證鍵有唯一性
性.,HashMap最多隻允許一條記錄的鍵為NULL,允許多條記錄的值為NULL,Map的實現類. - TreeMap:底層是二叉樹資料結構,存取都快,儲存無序,但是元素有排序,按照自然順序或自定義比較性儲存鍵,通過比較性保證鍵有唯一性,Map的實現類.
- HashTable: 底層是雜湊表資料結構,與HashMap類似,不同的是它不允許記錄的鍵或者值為空;
它支援執行緒的同步,即任一時刻只有一個執行緒能寫Hashtable,因此也導致了Hashtable在寫入時會比較慢,Map的實現類. - LinkedHashMap: 儲存有序,這點和上面的不同,鍵有唯一性,是HashMap的一個子類,允許使用null值和null鍵;
固定容量的基於最近最少使用演算法(LRU)的LinkedHashMap.可用作簡單快取.使用方法與LinkedHashMap一致;
利用LinkedHashMap實現簡單的快取,必須實現removeEldestEntry方法,預設沒有開啟LRU演算法,通過構造方法設定accessOrder引數為true則開啟LRU演算法儲存資料.
注意:
集合的儲存有序和無序是指存入元素的順序和取出元素的順序。如果是有序的話,是指存入元素時的順序和打印出來的順序是一樣的;而如果是無序的話是指存入元素的順序和取出元素的順序不一致;並不是說儲存的元素是否有排序。
Collection介面的共性方法
| 操作 | 含義 | 返回值 |
|---|---|---|
| add(Object o) | 將指定物件儲存到容器末尾處,add 方法的引數型別是Object 便於接收任意物件,新增成功返回true,否則false | boolean |
| addAll(Collection c) | 將指定集合中的元素新增到呼叫該方法的集合中 | boolean |
| remove(Object o) | 將指定的物件從集合中刪除 | boolean |
| removeAll(Collection c) | 將指定集合中的元素刪除 | boolean |
| clear() | 清空集合中的所有元素 | void |
| isEmpty() | 判斷集合是否為空 | boolean |
| contains() | 判斷集合何中是否包含指定物件 | boolean |
| containsAll() | 判斷集合中是否包含指定集合 | boolean |
| size() | 返回集合容器的大小 | int |
| toArray() | 集合轉換陣列 | Object[] |
| iterator() | 返回在此collection迭代元素的迭代器 | Iterator |
list介面的共性方法
| 操作 | 含義 | 返回值 |
|---|---|---|
| addadd(int index, E element) | 指定位置新增元素 | void |
| addAll(int index, Collection c) | 指定位置新增集合 | boolean |
| remove(int index) | 刪除指定位置元素並返回 | Object |
| set(int index, E element) | 修改指定位置上的元素並返回 | Object |
| get(int index) | 獲取指定位置上的元素,注意IndexOutOfBoundsException | Object |
| indexOf(Object o) | 獲取指定元素第一次出現的角標,和String類的indexOf相似, 找不到返回-1 | int |
| lastIndexOf(Object o) | 獲取指定元素最後一次出現的角標,和String類的indexOf相似 | int |
| subList(int fromIndex, int toIndex) | 獲取指定開始和結束位置的子集合,包頭不包尾 | List |
| listIterator() | 返回此列表元素的列表迭代器,它是Iterator的子介面 | ListIterator |
提示:List集合的特有方法都是和角標index有關的。
list集合元素遍歷的幾種方式
// 使用toArray方法將集合變成陣列來遍歷
Object[] arr = list.toArray();
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + ",");
}
// get方法逐個獲取集合的元素
for (int index = 0; index < list.size(); index++) {
System.out.print(list.get(index) + ",");
}
/*
* 使用列表迭代器listIterator的方式遍歷集合,listIterator是Iterator的子介面,特有方法如下:
* hasPrevious()是否有上一個元素
* previous()遊標先向上移動一個單元,然後取出當前遊標指向的元素
* next()首先取出當前遊標執行的元素,然後遊標向下移動一個單元
* add(E e)把元素新增到當前遊標指向的位置
* set(E e)替換迭代器最後一次返回的元素
* remove()從列表中移除由next或 previous返回的最後一個元素
* 如果需要在遍歷的過程中修改集合中的元素個數,則只能使用listIterator,而不能使用Iterator
* 否則會丟擲ConcurrentModificationException異常
*/
ListIterator it = list.listIterator();
while (it.hasNext()) {
System.out.print(it.next() + ",");
}
//使用Collection介面的Iterator方法遍歷集合
Iterator itt = list.iterator();
while(itt.hasNext()){
System.out.print(itt.next() + ",");
}除去ArraysList集合中的重複元素
注意:ArrayList集合是可以儲存重複元素的,如果要去除重複元素,可以使用contains方法,contains方法底層會呼叫傳入引數的equals方法,所以還需要複寫元素的equals方法,自定義去除重複的規則。
需求 : 使用ArrayList儲存一批書籍,然後該片書籍是有重複元素的,定義一個函式清除集合中的重複元素,返回一個沒有重複元素的集合。只要id號相同的書籍就認為是同一本書。
實體類:
/**
* 實體類
* @author mChenys
*
*/
public class Book {
private int id;
private String name;
public Book(int id, String name) {
this.id = id;
this.name = name;
}
// 複寫Object的equals方法,否則預設比較的是物件的記憶體地址
@Override
public boolean equals(Object obj) {
if (obj instanceof Book) {
Book b = (Book) obj;
if (this.id == b.id) {
return true;// 如果id相同,則認為是同一個物件
}
}
return super.equals(obj);
}
@Override
public String toString() {
return "{name=" + this.name + ",id=" + this.id + "}";
}
}
去重操作
/**
* ArrayList的去重複操作
* @author mChenys
*
*/
public class ListSort {
public static void main(String[] args) {
List<Book> books = new ArrayList();
books.add(new Book(110, "java神書"));
books.add(new Book(220, "java核心技術"));
books.add(new Book(330, "精通javascript"));
books.add(new Book(110, "java神書2"));
System.out.println("去重複前:"+books);
books = removeRepeate(books);
System.out.println("去重複後:"+books);
}
private static List<Book> removeRepeate(List<Book> books) {
ArrayList newList = new ArrayList();//建立新集合
for(Book b : books){
if(newList.contains(b)){//contains方法底層會呼叫所傳引數的equals方法
continue;
}
newList.add(b);
}
return newList;
}
}輸出結果:

從上面的輸出結果中可以看到,ArrayList中的書籍已經成功的去重複的,同時還可以發現元素的儲存是有序的.
LinkedList的特有方法
| 操作 | 含義 | 返回值 |
|---|---|---|
| addFirst(E e) | 把元素新增到集合的首位置上 | void |
| addLast(E e): | 把元素新增到集合的末尾處 | void |
| getFirst() | 獲取集合的首元素 | Object |
| getLast() | 獲取集合的末尾元素 | Object |
| removeFirst() | 刪除首元素並返回所刪除的元素 | Object |
| removeLast() | 刪除末尾的元素並返回刪除的元素 | Object |
| push() | jdk1.6出現,棧資料結構(後進先出),往棧中新增元素,呼叫addFirst()實現 | void |
| pop() | 與push對應,往棧中彈出元素,呼叫removeFirst()實現 | Object |
| offer() | jdk1.5出現,雙端佇列資料結構(先進先出),往佇列中新增元素,呼叫add()實現 | void |
| poll() | 與offer對應,從佇列中刪除元素,類似remove() | Object |
| descendingIterator() | 返回逆序的迭代器物件,輸出的結果和Iterator及listIterator的遍歷結果順序相反 | Iterator |
將ArrayList中的元素進行自定義的排序
需求:使用ArrayList儲存一批人物件進去,然後定義一個方法對集合中的人按照年齡排序。
實體類
/**
* 實體類
*
* @author mChenys
*
*/
public class Person {
public String name;
public int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "{姓名:" + this.name + " 年齡:" + this.age + "}";
}
}按年齡排序集合
/**
* 對ArrayList集合進行排序
* @author mChenys
*
*/
public class ListSort {
public static void main(String[] args) {
List<Person> list = new ArrayList<Person>();
list.add(new Person("哈哈", 12));
list.add(new Person("呵呵", 7));
list.add(new Person("痴痴", 32));
list.add(new Person("嘻嘻", 22));
System.out.println("排序前: " + list);
sortList(list);
System.out.println("排序後:" + list);
}
private static void sortList(List<Person> list) {
// 直接排序的思想
for (int i = 0; i < list.size() - 1; i++) {
for (int j = i + 1; j < list.size(); j++) {
// 取出兩個要比較的人。
Person p1 = (Person) list.get(i);
Person p2 = (Person) list.get(j);
if (p1.age > p2.age) {
// 交換位置,此處不需要定義第三方變數,因為這裡集合儲存的是物件的記憶體地址池
list.set(i, p2); // set方法就是設定指定索引值的位置替換指定的元素。
list.set(j, p1);
}
}
}
}
}輸出結果:

Set集合
該介面沒有特有的方法,都是繼承了Collection父介面的方法,特點: 無序,不可重複。
HashSet儲存的原理
往HashSet新增元素的時候,首先會呼叫元素的hashCode方法得到該元素的雜湊碼值,然後經過一些運算就可以算出該元素在雜湊表的儲存位置。
情況1:根據元素的hashCode方法算出的位置如果目前沒有任何的元素儲存的話,那麼該元素可以直接新增到雜湊表中。
情況2:如果根據元素的雜湊碼值算出的位置目前已經有儲存元素了,那麼接著還會呼叫該元素的equals方法與該位置的元素再比較一次,如果equals返回的是true,那麼就視為同一個元素,這時候就不允許在新增該元素了,如果返回的是false,那麼才可以新增該元素。
注意:HashSet的add和remove方法會依賴於hashCode方法和equals方法;因為add方法需要確保元素的唯一性,remove方法需要在雜湊表中找出元素的位置。
自定義hashCode方法和equals方法
注意:一般底層資料結構是使用雜湊表的時候才需要重寫hashCode和equals方法.
1.自定義hashCode方法的原因是:
hashCode方法是Object的方法,該方法預設比較的是物件的記憶體地址值,每一個物件的記憶體地址值都是不一樣的。而HashSet集合中是使用該方法來計算出雜湊表的,當我們儲存自定義物件的時候,例如person物件,現實生活中同一個人的話,雜湊值就應該是一樣的,但是如果不復寫Object 的hashCode方法的話,HashSet集合在呼叫該方法的時候得到的值就是person物件的記憶體地址值,即會出現同一個人,卻有不同的雜湊值,這就違背了我們認為的同一個人的意思。最嚴重的問題還會造成該集合可以儲存多個重複的人物件,因為當HashSet集合判斷了物件的hashcode值,如果不相同的話,就不會再判斷物件的equals結果了,直接就儲存到集合中了。
在String類中已經複寫了hashCode方法,如果字串的內容相同且字元順序也相同的話,則hashCode返回值是一樣的。
2.自定義equals方法的原因是:
HashSet集合的特點是當新增物件的時候,如果發現新增物件的hashCode值一樣的情況的話,HashSet集合底層還會呼叫物件的equals方法來比較該這兩個物件是否為同一個物件,由於equals方法是Object的方法,預設比較的還是物件的記憶體地址值。同樣對於Person類物件,在顯示生活中同一個人的話equals比較的內容應該也是相同的,但是如果不復寫equals方法的話,得到的結果就是一樣的。這就會造成該集合可以儲存多個重複的人物件了。
在String類中已經複寫了equals方法,對於字串物件通過equals方法比較的是字串內容是否相同而不是記憶體地址值。
使用HashSet自定義去重規則
需求:實現一個註冊使用者的功能,接收鍵盤錄入一個帳號、密碼。 如果帳號與密碼一致,那麼視為同一個使用者,不允許新增到hashset中。
實體類
/**
* 實體類
* @author mChenys
*
*/
public class User {
String name;
int password;
public User(String name, int password) {
this.name = name;
this.password = password;
}
/**
* 類已經重寫了Object的hashCode方法,返回的int值是根據字串的字元編碼來生成的,
* 所以如果字串的內容相同且字元順序也相同的話,這hashCode返回值是一樣的。
*/
@Override
public int hashCode() {
return this.name.hashCode() + this.password;
}
/**
* 定義比較是否重複的依據,如果hashcode值相同就會的呼叫equals方法再比較是否相同。
*/
@Override
public boolean equals(Object obj) {
if (obj instanceof User) {
User p = (User) obj;
// 這裡的equals是比較的字串內容是否相同,字串比較不能使用==來比較,因為==用於字串比較的話比較的是記憶體地址。
return this.name.equals(p.name) && this.password == p.password;
}
return false;
}
@Override
public String toString() {
return "{" + this.name + "," + this.password + "}";
}
}去重操作
public class SetRemoveRepeat {
public static HashSet hashset = new HashSet();
public static void main(String[] args) {
login();
}
public static void login() {
while (true) {
Scanner sc = new Scanner(System.in);
System.out.println("請輸入你的姓名");
String name = sc.next(); // 該方法返回的是通過new建立的字串物件。因此記憶體地址是不同的。
System.out.println("請輸入你的密碼");
int password = sc.nextInt();
boolean success = hashset.add(new User(name, password));
if (success) {
System.out.println("恭喜你註冊成功");
} else {
System.out.println("註冊失敗,該名字已被註冊");
}
System.out.println("當前的使用者有" + hashset);
}
}
}執行結果
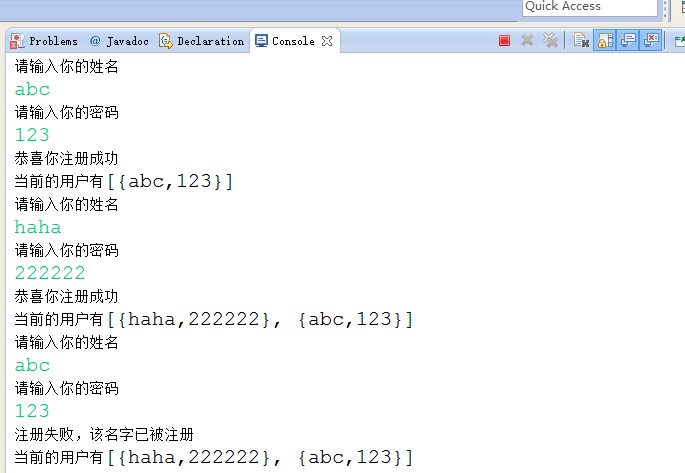
TreeSet集合類的使用
TreeSet類是Set介面的其中一個實現類,儲存無序且不可重複的(元素有排序,那是因為通過定義比較規則來實現).特點:往TreeSet新增元素的時候,如果新增的元素具備了自然順序的特性,那麼treeSet會按照元素的自然順序進行排序儲存。否則需要自定義比較規則。
TreeSet出現的原因
由於ArrayList 、 LinkedList儲存的元素雖然儲存是有序的,但是元素卻可以出現重複的;而HashSet儲存的元素雖然是不能重複的,但是儲存順序卻是無序的;為了解決這個問題,TreeSet集合就誕生了,TreeSet集合雖然儲存元素是無儲存順序的,但是由於存入的元素要有自然順序,或者需要實現排序規則,所以TreeSet集合儲存的元素都是有排序的。記住,儲存元素是否有序和元素是否排序是兩個不同的概念,前面也已經解釋過了。
TreeSet新增元素需要注意的事項
1.TreeSet在儲存元素的時候必須要保證存入的元素是具有可比性的,否則新增後會編譯失敗,提示ClassCastException異常。
2.往TreeSet新增元素的時候,如果元素本身具備了自然順序的特性,那麼treeSet會按照元素的自然順序特性排序進行儲存。
3.如果新增的元素本身不具備比較性,那麼元素所屬的類必須要實現Comparable介面或者自定義類實現Comparator介面來構建”比較器”。建議採用實現後者的方式,因為這種方法的靈活性高。
4.如果採用實現Comparable介面的方式,那麼需要複寫compareTo方法,在該方法中自定義元素比較的規則。compareTo方法返回的結果是0,則表示新增的是重複的元素,不允許新增。
5.如果採用自定義類構建比較器的方式,那麼需要該自定義的類必須要複寫Comparator介面的compare方法,並在方法中定義元素比較的規則。然後在建立TreeSet集合物件的時候,把該自定義的類物件作為引數傳遞到TreeSet集合的構造方法中。
6.如果新增的元素本身不具備自然順序,且元素所屬的類也實現了Comparable介面,然後也定義了比較器。那麼在建立TreeSet集合物件的時候,優先採用比較器的方式。
7.如果採用比較器的方式,可以根據需要自定義多種不同比較方式的比較器,然後使用 的時候只需要在建立TreeSet集合物件的時候傳入所需的比較器即可滿足不同的需求。
實現Comparable介面實現比較性
/**
* 定義比較性,按照員工工資進行排序
*
* @author mChenys
*
*/
public class Emp implements Comparable { // 元素所屬的類必須實現Comparable介面
int id;
String name;
int salary;
public Emp(int id, String name, int salary) {
this.id = id;
this.name = name;
this.salary = salary;
}
@Override
public String toString() {
return "{ 編號:" + this.id + " 名字:" + this.name + " 薪水:" + this.salary
+ "}";
}
/**
* 複寫compareTo方法,實現按照工資來比較
*/
public int compareTo(Object obj) {
Emp emp = (Emp) obj;
return this.salary - emp.salary;
}
}TreeSet的排序
/**
* 自定義TreeSet的比較性,按照員工的工資來排序
*
* @author mChenys
*
*/
public class TreeSetSort {
public static void main(String[] args) {
// 建立一個TreeSet物件
TreeSet<Emp> tree = new TreeSet<Emp>();
tree.add(new Emp(117, "錦濤", 3000));
tree.add(new Emp(220, "澤東", 1000));
tree.add(new Emp(119, "家寶", 2000));
tree.add(new Emp(115, "近平", 400));
Iterator<Emp> it = tree.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}執行結果:
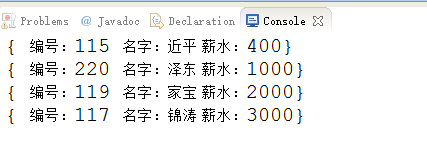
建立Comparable實現類定義比較器
/**
* 自定義一個比較器類,通過id
*
* @author mChenys
*
*/
public class MyComparator implements Comparator {
/**
* Compare方法中就寫兩個元素比較的規則。
* 如果o1小於o2,返回一個負數;如果o1大於o2,返回一個正數;如果他們相等,則返回0;
*/
public int compare(Object o1, Object o2) {
if (o1 instanceof Emp && o2 instanceof Emp) {
Emp e1 = (Emp) o1;
Emp e2 = (Emp) o2;
return e1.id - e2.id;
}
return 0;
}
}/**
* 通過自定義比較器按照員工的id進行排序
* @author mChenys
*
*/
public class TreeSetSort2 {
public static void main(String[] args) {
// 1.建立一個比較器物件
MyComparator comparator = new MyComparator();
// 2.建立一個TreeSet物件,將比較器物件傳入TeeSet構造方法
TreeSet<Emp> tree = new TreeSet<Emp>(comparator);
tree.add(new Emp(117, "錦濤", 3000));
tree.add(new Emp(220, "澤東", 1000));
tree.add(new Emp(119, "家寶", 2000));
tree.add(new Emp(115, "近平", 400));
Iterator<Emp> it = tree.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
執行結果:
String物件的自然排序
String字串也是有自然順序的。因為String類已經實現了Comparable介面,所以可以直接呼叫compareTo方法進行排序了。
這點通過原始碼可以發現:

字串的比較規則:
情況1:可以找到對應的不同字元,那麼比較的就是第一個對應的不同字元。
情況2:找不到對應不同的字元,那麼比較的就是字串的長度。長度小的排在前面,長度大的排在後面。
注意: 即使字串的長度不一致,但是有對應不同的字元,那麼比較的還是對應不同的字元。 對應字元的編碼值小的排在前面,即從小到大排序。
一個demo瞭解字串的自然順序規則
/**
* 字串的自然順序規則
* @author mChenys
*
*/
public class StringSort {
public static void main(String[] args) {
TreeSet<String> tree = new TreeSet<String>();
tree.add("abc");
tree.add("bca");
tree.add("bc");
System.out.println(tree); // [abc, bc, bca]
String str1 = "100";
String str2 = "2";
// 結果是-1;因為比較的是第一個對應的不同字元即:1比2小
System.out.println(str1.compareTo(str2));
}
}
使用TreeSet集合對字串物件進行排序
最後一個demo加強對TreeSet集合的認識
需求:目前有字串 String str=”8 10 15 5 2 7”; 對字串裡面的數字排序。返回一個有序的字串資料.”2 5 7 8 10 15”
思路:
1.將字串變成字元陣列toCharArray()
2.遍歷字元陣列,然後將陣列中的字元轉成int型別的資料並存儲到TreeSet集合中,這時集合中的元素就有了自然順序了。
3.通過迭代器遍歷集合,取出集合中的int型別資料,將其新增到StringBuilder容器中,然後通過toString方法返回的就是字串物件了。
public class TreeSetSort3 {
public static void main(String[] args) {
String str = "8 10 15 5 2 7";
System.out.println("有序的字串資料為:" + sortString(str));
}
public static String sortString(String str) {
String[] datas = str.split(" "); // 切割
// 建立一個treeSet物件
TreeSet<Integer> tree = new TreeSet<Integer>();
// 遍歷陣列,把陣列的元素新增到treeSet中。
for (int i = 0; i < datas.length; i++) {
int temp = Integer.parseInt(datas[i]);
// Integer.parseInt 把字串轉成了int型別 的資料,因為字串的比較方式是有問題的。
tree.add(temp); // 新增到TreeSet集合的時候,這些int型別的數值就變的有序了。
}
// 遍歷treeSet集合。
StringBuilder sb = new StringBuilder();
Iterator<Integer> it = tree.iterator(); // 獲取到了迭代器
while (it.hasNext()) {
sb.append(it.next() + " ");// 加一個空格
}
return sb.toString();
}
}執行結果:
