
A-Fast-RCNN 論文筆記
前言
近期為了學術彙報,閱讀了這篇CVPR 2017論文,該論文將對抗學習的思路應用在目標檢測中,通過對抗網路生成遮擋和變形圖片樣本來訓練檢測網路,取得了一定的效果。現將論文大意做了翻譯和理解,不一定完全對。
摘要
如何使得物體檢測器能夠應對被遮擋或者變形的影象?我們目前的解決方法是使用資料驅動的策略——收集一個足夠大的資料集,能覆蓋不同的情況,並希望通過訓練能夠讓分類器學會把它們識別為同一個物體。但是資料集真的能夠覆蓋所有的情況嗎?我們認為像分類、遮擋與變形這樣的特性也符合長尾理論。一些遮擋與變形非常罕見,幾乎永遠不會發生,但我們希望訓練出的模型是能夠應付所有情況的。本文中,我們提出了一種新的解決方案。使用一種對抗網路來自動生成遮擋和變形的樣本。對抗學習的目標是生成檢測器難以識別的樣本。在我們的框架中,原始檢測器與它的對手共同進行學習。實驗表明,我們的方法與 Fast-RCNN 相比,在 VOC07 上mAP 提升了 2.3%,在 VOC2012 上 mAP 提升了 2.6%。
介紹
在目標檢測任務中,我們常常要求模型能夠適應不同的光照條件、遮擋、形變等。標準的做法是使用一個包含各種不同情況的大規模資料集,例如COCO資料集就有10000多個不同遮擋形變情形的汽車樣本。我們希望通過足夠多的不同場景樣本,檢測器能學到更好的魯棒不變性,這也是卷積神經網路能成功用於目標檢測任務的重要原因。
然而並沒有這麼簡單,作者認為遮擋和形變的情況也遵循長尾理論,就是說一些遮擋和形變的情況很罕見,幾乎不會出現在大規模資料集中,例如圖1的一些情況。那麼如何學習這些罕見的遮擋和形變呢?使用更大的資料集是一個辦法,但是也很難突破長尾理論的限制。

通過對抗學習來生成這種困難正樣本在理論上是可行的,但具體方案還要分析。比如方案一:直接學習這些罕見的遮擋形變樣本,通過尾部分佈生成以假亂真的樣本圖片,結論是不可行,太過複雜,效果還難說。方案二:生成各種可能的遮擋和形變樣本,結論是情況太多,根本不可能完備。作者提出的方案是,不直接生成新的圖片,二是在原有圖片上“人為”新增遮擋和形變,也算是生成了困難的正樣本,讓檢測器難以進行分類判斷。
也就是訓練一個生成網路:它在卷積特徵圖空間上進行操作,通過遮罩特徵圖的一部分實現空間遮擋,通過操控特徵響應來實現空間變形,以這種方式生成困難正樣本。Fast R-CNN作為判別網路,是很難對這些樣本作出判斷的,當然生成網路想要騙過判別網路也很困難。二者在學習中共同提升,最終就提升了檢測器的效能。關鍵問題就是如何在卷積特徵空間中建立對抗樣本。
相關工作
作者在文中總結,針對目標檢測問題,目前學術界主要從三個思路進行探索:
一是設計更好的網路架構來提升效能,主要是使用更深的網路結構,例如 ResNet,Inception-ResNet ,ResNetXt ;
二是結合上下文推理,充分利用各個卷積層的特徵;
三是充分利用訓練資料來提升效能,例如hard example mining。
本文的工作就屬於第三條思路,充分利用現有資料,作者強調工作重點是以更好的方式利用資料,而不是試圖篩選資料來尋找困難樣本,當然,核心是利用對抗學習生成很難的樣本,拿給Fast R-CNN檢測,以提升其檢測魯棒性。
用於目標檢測的對抗學習
作者的對抗網路是在空間上受到限制:只管遮擋和形變。在數學上,檢測器(Fast R-CNN)的損失函式可以如下表示,它是softmax loss和bbox loss的求和。
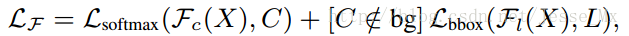
其中,
假定
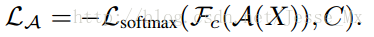
理解起來還是比較容易,如果對抗網路生成的特徵很好分類,其損失就比較大。當然如果能騙過檢測器,損失函式就變小了。
A-Fast-RCNN:技術細節
Fast R-CNN概述
作者簡介了所用的Fast R-CNN檢測框架,我這裡就不詳述了,具體可以參考這篇博文:Fast R-CNN論文詳解
對抗網路設計
作者設計了兩個對抗網路,分別用於遮擋和形變,注意到這兩個對抗網路是和Fast R-CNN聯合訓練的,主要是為了防止固定生成模式下的過擬合。實驗發現在特徵空間上的操作要比在輸入圖片更為高效,因此作者設計的對抗網路可修改圖片特徵層,使得檢測器難以判別。一開始它們是分開的,後面的階段它們將會被整合到統一的框架中。
用於遮擋的對抗網路
首先介紹Adversarial Spatial Dropout Network(ASDN,對抗空間丟棄網路),以下簡稱ASDN。如下圖2所示,ASDN網路的輸入是Fast R-CNN中RoI-pooling之後的特徵圖,然後通過全連線層生成掩模,確定特徵圖的哪些部分應該減掉(dropout),這樣生成的困難樣本最好要讓檢測器誤判,掩模會自動根據損失函式作出調整。
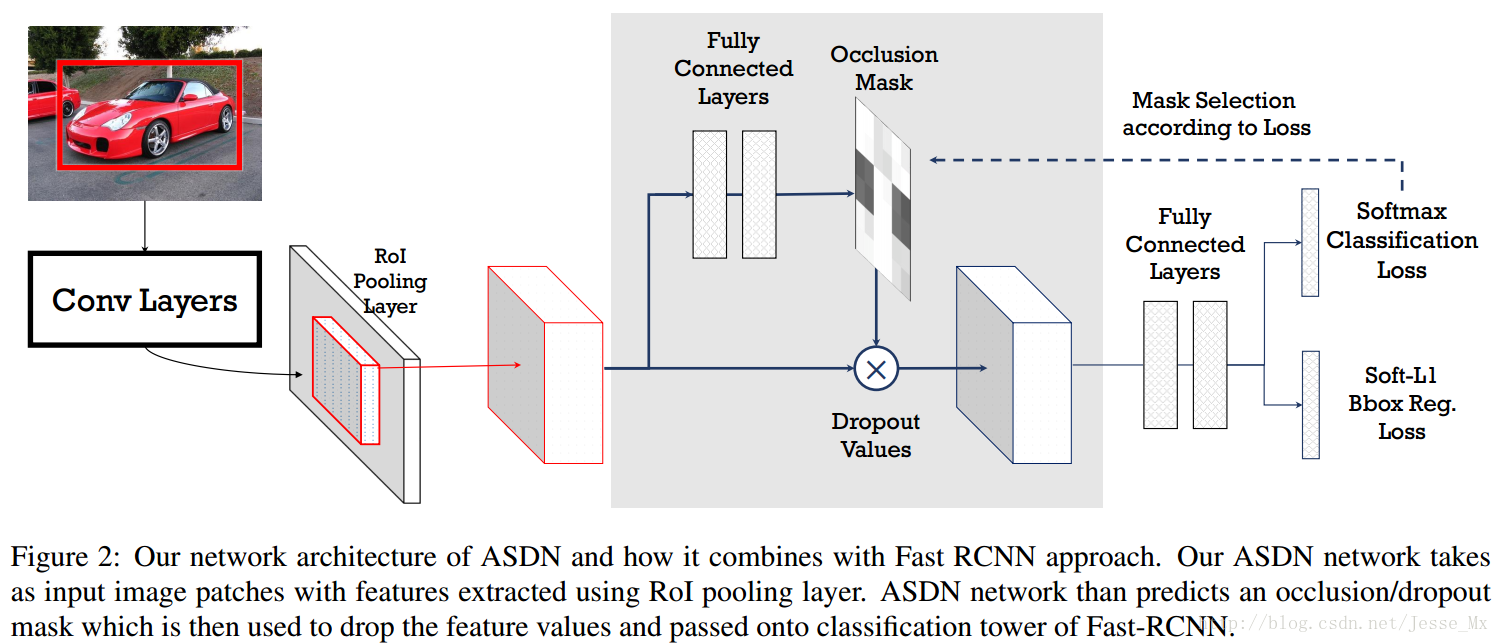
假設ASDN的輸入特徵圖是
網路結構。作者使用了標準的Fast R-CNN框架,對抗網路共享基底卷積層和RoI-pooling層,但是沒有共享引數。
模型預訓練。作者首先在沒有ASDN的情況下迭代Fast R-CNN模型10000次,然後才來訓練ASDN。
ASDN網路初始化。假設輸入ASDN的特徵圖維度是

取樣閾值。當然,由ASDN生成的結果不會是上述簡單的矩形二值化掩模,它應該是一個連續的熱圖(heatmap)。作者沒有使用固定閾值,二是按照重要性排序,將前面1/3的畫素值給遮蔽掉。具體而言的操作是,選擇概率值前1/2的畫素,再隨機選擇其中的2/3設為0,剩下的1/3設為1,這樣總共將1/3的畫素給遮蔽掉,造成遮擋的情況。
聯合訓練。作者將ASDN和Fast R-CNN進行了聯合訓練,並且受到增強學習的啟發,著重訓練導致分類效果顯著降低的二值化掩碼。
用於形變的對抗網路
然後介紹Adversarial Spatial Transformer Network(ASTN,對抗空間變換網路),以下簡稱ASTN。ASTN的關鍵是在特徵圖上產生形變使得檢測器難以判別。
STN概述。STN網路有三個組成部分,分別是:定位網路(localisation network)、網格生成器(grid generator)和取樣器(sampler)。定位網路將估計形變引數(如旋轉度、平移距離和縮放因子),網格生成器和取樣器將會用到這些引數來產生新的形變後的特徵圖。這個空間變換神經網路仍然是複雜的概念,我自己概括就是:相當於在傳統的卷積層中間,裝了一個“外掛”,可以使得傳統的卷積帶有了裁剪、平移、縮放、旋轉等特性,具體內容參見DeepMind論文:Spatial Transformer Networks 。
STN對抗網路。空間變換有好幾種形式(裁剪、平移、縮放、旋轉等),針對本文中的形變要求,作者僅關注旋轉特徵,意味著ASTN只需要學習出讓檢測器難以判別的旋轉特徵就可以了。如圖4所示,對抗網路長得和前面的ASDN相似,其中定位網路由3個全連線層構成,前兩層是由fc6和fc7初始化來的。ASTN和Fast R-CNN還是要聯合訓練,如果ASTN的變換讓檢測器將前景誤判為背景,那麼這種空間變換就是最優的。作者也提到,可直接使用Fast R-CNN的softmax loss進行反向傳播,因為空間變換是可微的。
實施細節。作者在試驗中發現,限制旋轉角度很重要,不加限制容易將物體上下顛倒,這樣最難識別,也沒啥意義。作者把旋轉角度限制在了正負10度,而且按照特徵圖的維度分成4塊,分別加以不同的旋轉角度,這樣可以增加任務複雜性,防止網路預測瑣碎的變形 。(作者並未給出形象的視覺化圖形,理解的費勁)
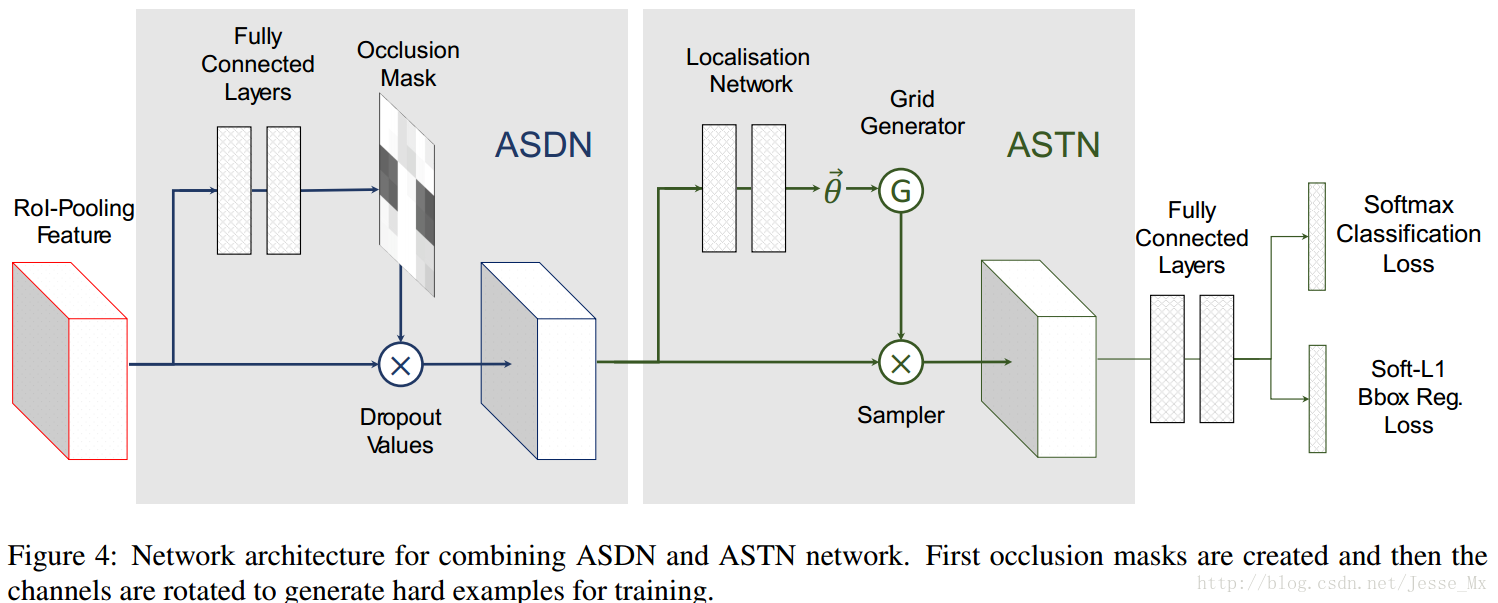
對抗網路融合
如圖4,作者將這兩個對抗網路結合在一起進行訓練,由於這兩個對抗網路提供不同型別的資訊,通過同時競爭這兩個網路,我們的檢測器可以變得的更魯棒。
實驗
Pascal VOC 2007的結果
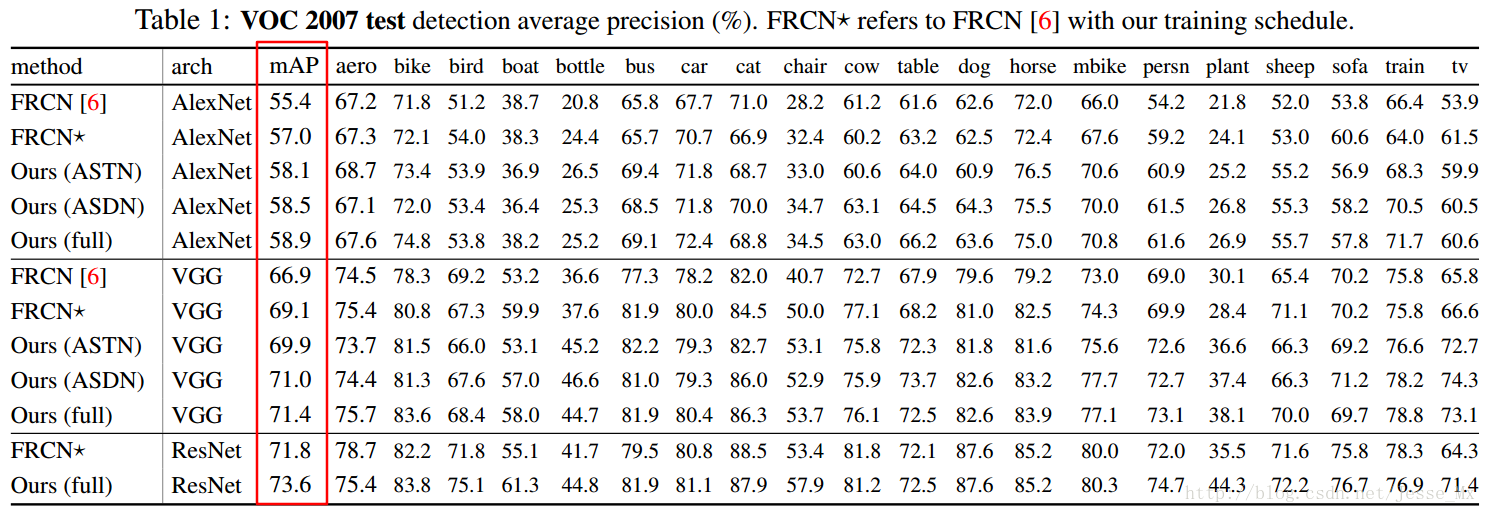
如表一所示:在AlexNet網路基礎上,作者訓練的Fast R-CNN的基準mAP是57%,加上ASTN後提示到58.1%,加上ASDN後提升到58.5%,二者都加則提升到58.9%。在VGG16網路基礎上,作者訓練的Fast R-CNN的基準mAP是57%是69.1%,加上ASTN後提示到69.9%,加上ASDN後提升到71.0%,二者都加則提升到71.4%。作者還試驗了非常深的網路ResNet-101,同時加上ASTN和ASDN,mAP從基準的71.8%提升到73.6%。
進一步分析(燒灼分析)
ASDN分析。作者將四種形成遮擋的丟棄(dropout)方式做了對比,如表2所示。在AlexNet網路基礎上,看到隨機dropout效果最差;將困難樣式窮盡提取的hard dropout表現不錯,但是窮盡策略不適合於大資料空間;固定ASDN引數的方式表現比hard dropout還差,因為缺乏來自Fast R-CNN的反饋;最後ASDN聯合訓練效果最好。

ASTN分析。作者將ASTN和隨機抖動(random jittering)做了對比(沒有給出對比表格),發現使用AlexNet,mAP分別是58.1%h和57.3%,使用VGG16,mAP分別是69.9%和68.6%,總之ASTN比隨機抖動效果好。
基於種類的分析
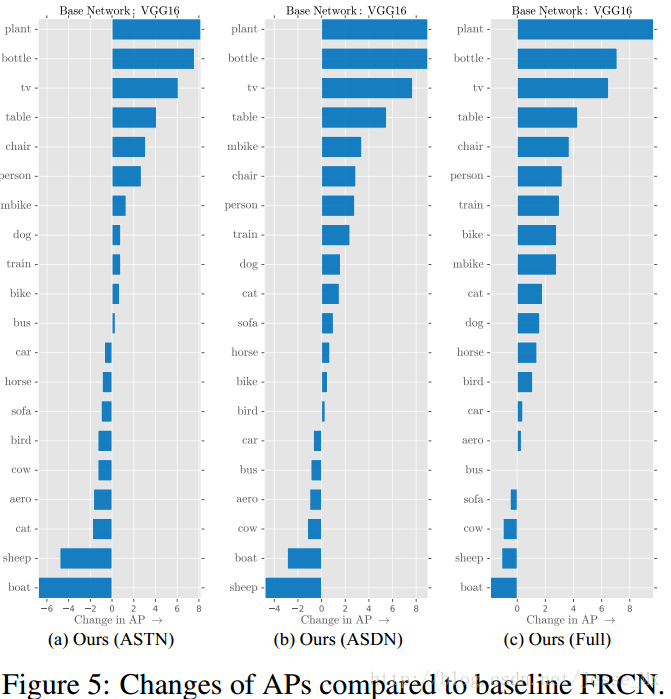
圖5展示了每個類別的效能如何隨著遮擋和形變而變化,ASDN和ASTN的表現還蠻相似,一多半的種類mAP得到提升,另外有那麼幾類下降了,總體當然是提升了。目標檢測中一些重要的類別,如car,person,bike能得到提升,說明該方法還是用武之地的。
定性分析
圖6是手動挑選出來的典型例子,它們展示了對抗學習的缺點:容易造成假陽性(false positive)。有時候,對抗網路建立的遮擋、形變樣本可能和其他類別過於相似,使得模型過度泛化。比如,本文方法遮擋了自行車的輪子,導致輪椅被錯誤地分類為自行車。

Pascal VOC 2012和MS COCO的結果
作者接著展示了VOC 2012資料集的結果,如表3,VGG16網路下,mAP從66.4%提升到69.0%。在MS COCO資料集下,VGG16網路下,基準mAP是42.7%(VOC標準)和25.7%(COCO標準),使用對抗網路後,mAP提升到了46.2%(VOC標準)和27.1(COCO標準)。

和OHEM的對比
本文方法和OHEM(Online Hard Example Mining)很有聯絡,二者都是充分利用訓練資料的典型。本文方法是建立並不存在的困難正樣本,效果很好,而OHEM是挖掘利用現有的困難樣本,現實意義更高。在VOC 2007資料集上,本文方法略好(71.4% vs. 69.9%),而在VOC 2012資料集上,OHEM更好(69.0% vs. 69.8%)。作者又做了實驗,VOC 2012資料集下,our approach+OHEM(71.7%),two OHEM(71.2),two our approach(70.2%),後面二者效果沒有混合使用的好,說明這兩種方法可以有效互補。
總結
作者首次將對抗學習引入到了目標檢測領域,idea是非常創新的,而且對比實驗做得很充分。但是文中使用的是較老的Fast R-CNN,而不是更好的Faster R-CNN,從簡化問題的角度分析,也是可以理解的。該方法網路設計和訓練較困難,mAP的提升卻比較有限,總體感覺學術意義大於工程意義。