
【中文編碼】使用Python處理中文時的文字編碼問題
0x00 正文
最近,在處理中文編碼的資料的時候,遇到了一些還是令人頭疼的問題。
亂碼!
亂碼!!
亂碼!!!
稍微整理一下處理過程,順帶著記錄一下解決方案啥的……
0x01 文字轉碼
最初,拿到很多GB2312(Simplify)編碼的HTML檔案,稍微有點頭疼,因為在Shell裡開啟一看,都是下面這樣奇怪的東西
<p><span style="font-family: ; font-size: 14px;"> </span><span style="font-fami˨λ[H
pan></p>
<p><span style=" 然後就encode/decode忙了半天都看不出來這到底是個啥……
於是就想方設法……把它們都變成UTF-8試試看
關鍵句: (需要import commands)
iconv -f gb18030 -t utf-8 FileA.html > FileB.html
將
FileA.html由gb18030轉換到UTF-8,輸出至檔案FileB.html
完整轉換程式碼如下:
# -*- coding: gbk -*-
from bs4 import BeautifulSoup
from multiprocessing import Pool
import os
import re
import sys
import urllib2
import commands
import ConfigParser
def CheckTitle(soup) :
pos = 0
for p in soup.find_all('p'):
if 程式碼解釋:遍歷當前目錄下的html資料夾,將其中所有的檔案轉換編碼之後輸出至html-UTF資料夾中,命名為與原先同名的檔案
0x02 中文字元的split用法
獲得了中文字串之後,想要用split函式將其按逗號分號和句號等分割成小短句方便處理,然而,將中文字元中的逗號分號句號等為split函式傳參的時候,會出現問題,一萬個報錯,大概意思都是編碼問題:不能出現在position多少到多少之間blablabla……
那麼,該怎麼辦呢
像我這樣轉成了UTF-8的html中提取的中文字串,python檔案頭上如果加上#-*- coding: UTF-8 -*-,python在判斷傳參的中文字元的時候就可以編碼正確了,順手再寫一個多字元匹配分割的demo備忘:
#-*- coding: UTF-8 -*-
import os
import re
import sys
import commands
import ConfigParser
def my_split(s, seps):
res = [s]
for sep in seps:
s, res = res, []
for seq in s:
res += seq.split(sep)
return res
if __name__ == '__main__' :
inputText = "今天天氣不錯。啥?下雨了!12345"
txt = inputText.strip()
mylist = my_split(txt,['\n','\r','\t',',',';',',','。',';'])0x03 正確獲得中文字串的len()
通常,我們需要知道某個中文字串的長度,然而我們檢視的時候,由於編碼的問題,往往長度會變為需求值的整數倍(倍數與編碼型別有關,剛剛在Python中測試了len(str)是中文字數的3倍,這個很有趣,到時候可以去查一查具體何種編碼佔多少個字元位置),如下為C++中的測試
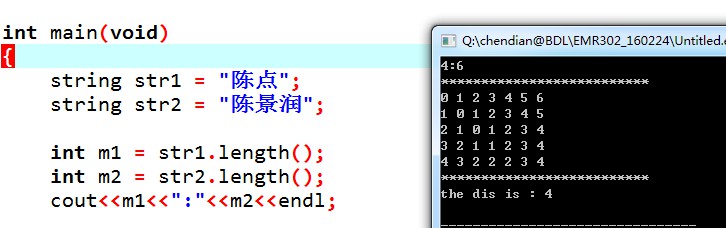
那麼在Python中我們該如何獲得正確的中文字元個數呢?
我們可以decode一下,將字串變為當前python所用的編碼方式,示例如下:
# s1,s2 請自主獲取,本人是讀的`UTF-8`編碼檔案中的字串
str1,str2 = s1.decode('utf-8'),s2.decode('utf-8')
print len(s1,s2)
print len(str1,str2)
print s1,s2,'\n',str1,str20x04 Shell中的亂碼現象
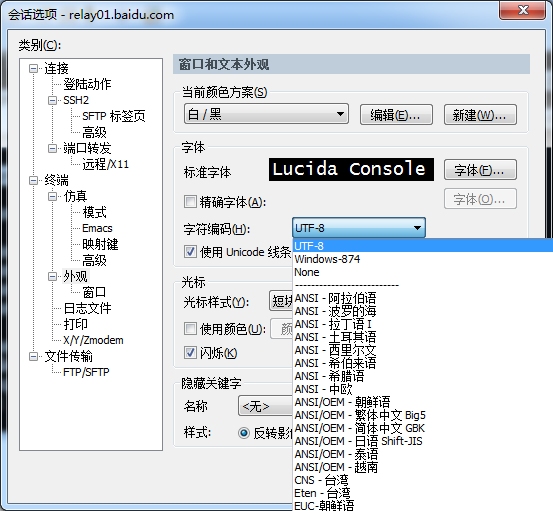
“我編碼都是對的,直接開啟也正常,為什麼在Shell裡看的就都是亂碼呢?”
嘛,你可以試試更改一下會話選項中的字元編碼哦,可能只是你的Shell會話的編碼設定得不對應罷了~
0x05 等以後遇到新的問題再接著寫吧~
編碼真是博大精深,Python要是沒有編碼問題這個世界該多美好呀QwQ
