
Regex Golf 正則表示式練習(持續更新)
Regex Golf 正則表示式練習
初步接觸正則化表示式,本文記錄regex golf(alf.nu/RegexGolf)上題目答案,一些拙見,歡迎指正或給出更好的答案。
一、Warmup

二、Anchors

三、It never ends
法一:(?!\w)表示後面沒有字母
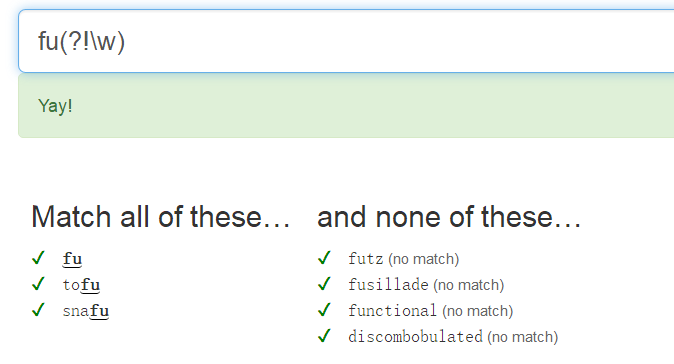
法二:
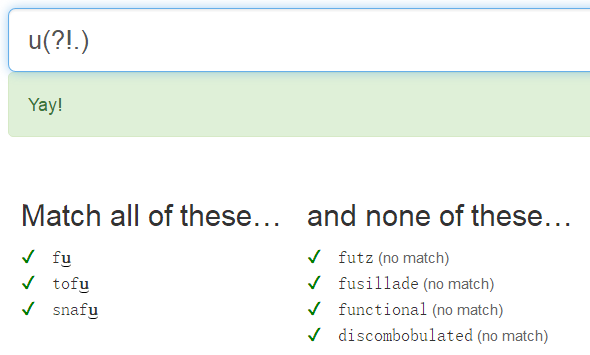
法三:\b為邊界匹配,後面不出現字母
\B為邊界匹配,後面可接字母
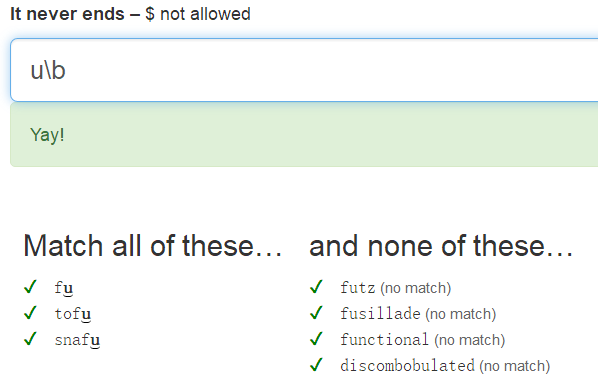
四、Ranges
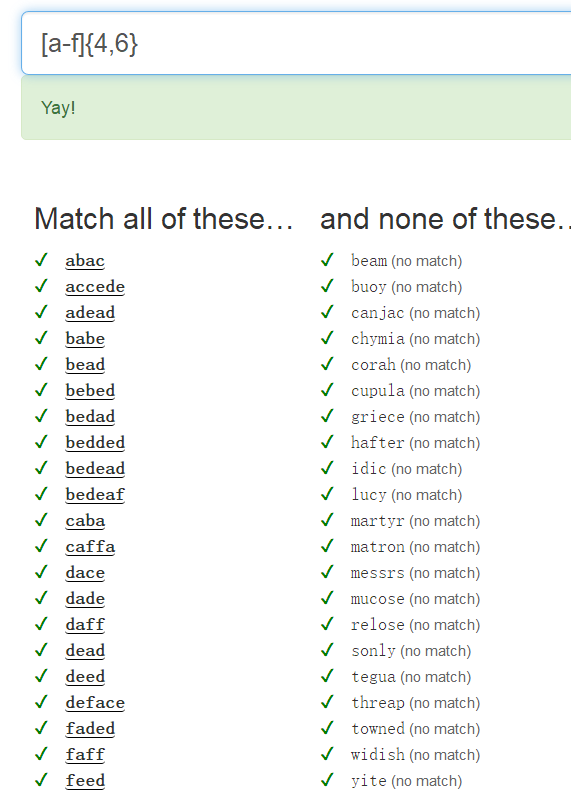
其實可以更簡潔

五、Backrefs
(...)表示取了前三個字元,\1表示前面(...)所代表的三個字元,即\1 == (...)

六、abba
法一:(.)(.)\2\1 可以匹配 abba這種型別的字元

法二:這個結果沒太看懂,先放著

七、A man, A plan

八、Prime

九、Four

十、Order(*)
這道題規律是左邊每個單詞後面的字母都在前一個之後,但是我不會實現,所以用了別的方法
法一:

法二:包含5個或者6個字母,且不以e結尾(只是會在這一種情況下有效)

十一、Triples
詳情看https://www.zhihu.com/question/24824487
法一:

法二:

相關推薦
Regex Golf 正則表示式練習(持續更新)
Regex Golf 正則表示式練習初步接觸正則化表示式,本文記錄regex golf(alf.nu/RegexGolf)上題目答案,一些拙見,歡迎指正或給出更好的答案。一、Warmup二、Anchors三、It never ends法一:(?!\w)表示後面沒有字母法二:法
js正則表示式替換(web作業)
運用正則表示式匹配“Paul;Puala,Pauline,paul,Paul”中的所以Paul,並將其替換成Ringo 程式碼如下: <!DOCTYPE html> <html> <head> <title>替換&
正則表示式全集(記錄用)
表示式全集 字元 描述 \ 將下一個字元標記為一個特殊字元、或一個原義字元、或一個向後引用、或一個八進位制轉義符。例如,“n”匹配字元“n”。“\n”匹配一個換行符。序列“\\”匹配“\”而“\(”則匹配“(”。
Linux正則表示式引擎(BRE ERE)支援的一些表達形式(Part.I BRE)
BRE(basic regular expression):以sed為例 純文字 :echo "Happy New Year" | sed -n '/Happy/p' 錨字元 : 匹配在行首 :echo "Happy New Year" | sed -n '/^
python 66:re正則表示式8(全- tcy)
目錄: 1.re-概述 https://mp.csdn.net/postedit/851568392.re-函式 https://mp.csdn.net/postedit/851569933.re-Pattern https://mp.csdn.net/postedit/85157
正則表示式大全(整理版)
測試字串的某個模式。例如,可以對一個輸入字串進行測試,看在該字串是否存在一個電話號碼模式或一個信用卡號碼模式。這稱為資料有效性驗證 替換文字。可以在文件中使用一個正則表示式來標識特定文字,然後可以全部將其刪除,或者替換為別的文字 根據模式匹配從字串中提取一個子字串。可以用來
轉載 Python 正則表示式入門(中級篇)
Python 正則表示式入門(中級篇) 初級篇連結:http://www.cnblogs.com/chuxiuhong/p/5885073.html 上一篇我們說在這一篇裡,我們會介紹子表示式,向前向後查詢,回溯引用。到這一篇開始前除了回溯引用在一些場合不可替代以外,大部分情況下的正則表示式你應該都會寫了
正則表示式——python(學習記錄)
<span style="font-size:18px;">>>> import re >>> help (re) This module exports the following functions:</span><span style="
js正則表示式在(replace()方法)
有字串var=’abc455efgabcab’ 去掉字串中的a、b、c字元,形成結果345efg <script type="text/javascript"> var str='abc345efgabcab';
正則表示式學習記錄(持續更新)
特殊字元含義: 字元 含義 字元 含義 * 匹配前面的子表示式零次或多次 + 匹配一次或多次 $ 匹配輸入字串的結尾位置,設定RegExg物件的
<MySQL學習二>用正則表達式進行搜索(持續更新)
例子 表達式 比較 特殊 通配 HERE 足夠 字符 mysql學習 1、正則表達式介紹 前面的過濾例子允許使用匹配、比較和通配操作符尋找數據。對於基本操作就足夠了,但是隨著過濾條件的復雜性的增加,WHERE子句本身的復雜性也有必要的增加。 正則表達式是用來匹配文本
Python正則表示式初識(九)
繼續分享Python正則表示式的基礎知識,今天給大家分享的特殊字元是[\u4E00-\u9FA5],這個特殊字元最好能夠記下來,如果記不得的話通過百度也是可以一下子查到的。 該特殊字元是固定的寫法,其代表的意思是漢字。換句話說,只要字元中是漢字,就可以通過該字元進行匹配,該特殊字元也是用中括號括起來的。
RE正則表示式總結(一)
一、概念 正則表示式,又稱規則表示式。(英語:Regular Expression,在程式碼中常簡寫為regex、regexp或RE),電腦科學的一個概念。正則表示式是對字元串(包括普通字元(例如,a 到 z 之間的字母)和特殊字元(稱為“
劍指offer——正則表示式匹配(遞迴呼叫)
當模式中的第二個字元不是“*”時: 1、如果字串第一個字元和模式中的第一個字元相匹配,那麼字串和模式都後移一個字元,然後匹配剩餘的。 2、如果 字串第一個字元和模式中的第一個字元相不匹配,直接返回false。 而當模式中的第二個字元是“*”時: 如果字串第一個字元跟模式第一個字元
劍指Offer 52. 正則表示式匹配 (字串)
題目描述 請實現一個函式用來匹配包括'.'和'*'的正則表示式。模式中的字元'.'表示任意一個字元,而'*'表示它前面的字元可以出現任意次(包含0次)。 在本題中,匹配是指字串的所有字元匹配整個模式。例如,字串"aaa"與模式"a.a"和"ab*ac*a"匹配,但是與"aa.a"和"ab*a"均不匹配 題目地
Leetcode 10:正則表示式匹配(最詳細的解法!!!)
給定一個字串 (s) 和一個字元模式 (p)。實現支援 '.' 和 '*' 的正則表示式匹配。 '.' 匹配任意單個字元。 '*' 匹配零個或多個前面的元素。 匹配應該覆蓋整個字串 (s) ,而不是部分字串。 說明: s 可能為空,且只包含從 a-z 的小寫字母
python html抓取,並用re正則表示式解析(一)
html抓取,並用re進行解析 #coding=utf-8 import urllib.request import re ''' url :"http://money.163.com/special/pinglun/" 抓取第一頁的新聞資訊,並按照以下規格輸出。 [ {'ti
python html抓取,並用re正則表示式解析(二)
需求: url: “http://search.jd.com/Search?keyword=幼貓貓糧&enc=utf-8#filter” 給出一個jd_search(keyword)方法,keyword為你要查詢的東西,比如:貓糧、手機,替換上面url中的keyword,得到一個新網
C#正則表示式入門(下)
一、匹配郵政編碼,郵政編碼為6位數字組成。 string code; code = Console.ReadLine(); Regex reg = new Regex(@"^\d{6}$",RegexOptions.None); Console.WriteLine(reg.IsMat
C#正則表示式入門(中)
一、忽略匹配優先模式 *? 重複任意次,但儘可能少重複 +? 重複1次或更多次,但儘可能少重複 ?? 重複0次或1次,但儘可能少重複 {n,m}? 重複n到m次,但儘可能少重複 {n,}? 重複n次以上,但儘可能少重複 【例二】在滿足匹配時