
SQL實現group by 分組後組內排序
在一個月黑風高的夜晚,自己無聊學習的SQL的時候,練習,突發奇想的想實現一個功能查詢,一張成績表有如下欄位,班級ID,英語成績,資料成績,語文成績如下圖
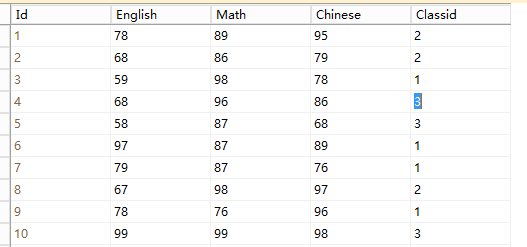
實現 查詢出 每個班級英語成績最高的前兩名的記錄。
看起來不難的業務,做起來才知道還挺麻煩的,說白了其實就是實現分組後的組內排序,一般不思考的話我們會寫出這樣的語句:
select top 2 English,Classid from CJ group by Classid order by English desc

出現這個錯誤,應該就明白了其實資料庫的查詢順序是先分組的,最後才將結果進行排序。通過正常邏輯思考,通過班級分組,不就是分了三個組:班級1,班級2,班級3 。我們可以通過聚合函式查詢出,每個組的個數,平均值等。可是你後面跟了英語成績什麼鬼?分組之後意味著,我們不能查詢單個的記錄了,我們查詢的單位都是關於組的資訊。
第一種實現 1
SELECT * FROM CJ m
where(
select COUNT(*) from CJ n
where m.Classid = n.Classid and n.English > m.English)<2
order by Classid, English desc
也是當網上查的,可以這樣理解,要找出前兩名的成績,只要符合比你成績高的不超過2個人就行了。其實是一個表的自連線,where條件就是一條一條記錄對比,首先在m表中拿一條記錄,是否符合 在同一班級中 比你成績高的不超過2個人。這樣就可以找到每個班的前兩名成績。然後按照降序排列。
在這種實現中,也可以加上其他篩選條件 比如查詢每個班級女生中英語成績前兩名的記錄
SELECT * FROM (select * from CJ where Gender='女') m where( select COUNT(*) from (select * from CJ where Gender='女') n where m.Classid = n.Classid and n.English > m.English)<2 order by Classid, English desc SELECT * FROM CJ m where(select COUNT(*) from CJ n where m.Classid = n.Classid and n.English > m.English and n.Gender='女')<2 --指的是內表 and Gender='女' --指的是外表 order by Classid, English desc
第二種是實現
select a.Classid,a.English from (select Classid,English,row_number() over(partition by Classid order by English desc) as n from CJ) a where n<=2
最官方,最好的實現方式
簡單的說row_number()從1開始,為每一條分組記錄返回一個數字
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根據COL1分組,在分組內部根據 COL2排序,而此函式計算的值就表示每組內部排序後的順序編號(組內連續的唯一的)
同樣的加上條件
select a.Classid,a.English,n,test from (select Classid,English,row_number() over(partition by Classid order by English desc) as n,123 test from CJ where CJ.Gender='女') a where n<=2
可以看出先執行的是where 進行篩選後,再通過分組,組內再排序,排序後在新增編號,其實是和正常的執行順序一樣的,只不過位置變了