
CUDA程式設計學習一
CUDA簡介
CUDA(Compute Unified Device Architecture),是顯示卡廠商NVIDIA推出的運算平臺。是一種通用平行計算架構,該架構使GPU能夠解決複雜的計算問題。說白了就是我們可以使用GPU來並行完成像神經網路、影象處理演算法這些在CPU上跑起來比較吃力的程式。通過GPU和高並行,我們可以大大提高這些演算法的執行速度。
安裝連結:CUDA—toolkit
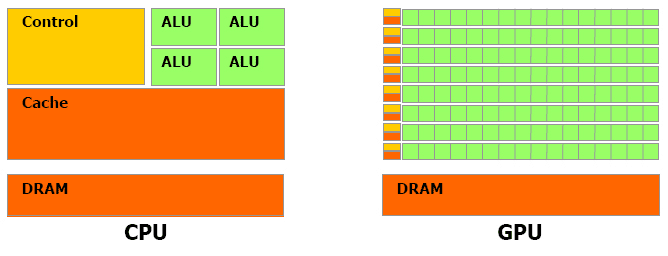
對於浮點數操作能力,CPU與GPU的能力相差在GPU更適用於計算強度高,多並行的計算中。因此,GPU擁有更多電晶體,而不是像CPU一樣的資料Cache和流程控制器。這樣的設計是因為多平行計算的時候每個資料單元執行相同程式,不需要那麼繁瑣的流程控制,而更需要高計算能力,這也不需要大cache。但也因此,每個GPU的計算單元的結構是十分簡單的,因此對程式的可並行性的要求也是十分苛刻的。
GPU計算的優缺點(摘自《深入淺出談CUDA》,所以舉的例子稍微老了一點,但不影響意思哈):
使用顯示晶片來進行運算工作,和使用 CPU 相比,主要有幾個好處:
顯示晶片通常具有更大的記憶體頻寬。例如,NVIDIA 的 GeForce 8800GTX 具有超過50GB/s 的記憶體頻寬,而目前高階 CPU 的記憶體頻寬則在 10GB/s 左右。
顯示晶片具有更大量的執行單元。例如 GeForce 8800GTX 具有 128 個 “stream processors”,頻率為 1.35GHz。CPU 頻率通常較高,但是執行單元的數目則要少得多。
和高階 CPU 相比,顯示卡的價格較為低廉。例如一張 GeForce 8800GT 包括512MB 記憶體的價格,和一顆 2.4GHz 四核心 CPU 的價格相若。
當然,使用顯示晶片也有它的一些缺點:
顯示晶片的運算單元數量很多,因此對於不能高度並行化的工作,所能帶來的幫助就不大。
顯示晶片目前通常只支援 32 bits 浮點數,且多半不能完全支援 IEEE 754 規格, 有些運算的精確度可能較低。目前許多顯示晶片並沒有分開的整數運算單元,因此整數運算的效率較差。
顯示晶片通常不具有分支預測等複雜的流程控制單元,因此對於具有高度分支的程式,效率會比較差。
由於顯示晶片大量平行計算的特性,它處理一些問題的方式,和一般 CPU 是不同的。主要的特點包括:
記憶體存取 latency 的問題:CPU 通常使用 cache 來減少存取主記憶體的次數,以避免記憶體 latency 影響到執行效率。顯示晶片則多半沒有 cache(或很小),而利用並行化執行的方式來隱藏記憶體的 latency(即,當第一個 thread 需要等待記憶體讀取結果時,則開始執行第二個 thread,依此類推)。
分支指令的問題:CPU 通常利用分支預測等方式來減少分支指令造成的 pipeline bubble。顯示晶片則多半使用類似處理記憶體 latency 的方式。不過,通常顯示晶片處理分支的效率會比較差。
因此,最適合利用 CUDA 處理的問題,是可以大量並行化的問題,才能有效隱藏記憶體的latency,並有效利用顯示晶片上的大量執行單元。使用 CUDA 時,同時有上千個 thread 在執行是很正常的。因此,如果不能大量並行化的問題,使用 CUDA 就沒辦法達到最好的效率了。
第一個CUDA程式
在 CUDA 的架構下,一個程式分為兩個部份:host 端和 device 端。Host 端是指在 CPU 上執行的部份,而 device 端則是在顯示晶片上執行的部份。Device 端的程式又稱為 “kernel”。通常 host 端程式會將資料準備好後,複製到顯示卡的記憶體中,再由顯示晶片執行 device 端程式,完成後再由 host 端程式將結果從顯示卡的記憶體中取回。
NVCC編譯器
任何一種程式設計語言都需要相應的編譯器將其編譯為二進位制程式碼,進而在目標機器上得到執行。對於異構計算而言,這一過程與傳統程式設計語言是有一些區別的。為什麼?因為CUDA它本質上不是一種語言,而是一種異構計算的程式設計模型,使用CUDA C寫出的程式碼需要在兩種體系結構完全不同的裝置上執行:1、CPU;2、GPU。因此,CUDA C的編譯器所做的工作就有點略多了。一方面,它需要將原始碼中執行在GPU端的程式碼編譯得到能在CUDA裝置上執行的二進位制程式。另一方面,它也需要將原始碼中執行在CPU端的程式編譯得到能在主機CPU上執行的二進位制程式。最後,它需要把這兩部分有機地結合起來,使得兩部分程式碼能夠協調執行。
CUDA C為我們提供了這樣的編譯器,它便是NVCC。嚴格意義上來講,NVCC並不能稱作編譯器,NVIDIA稱其為編譯器驅動(Compiler Driver),本節我們暫且使用編譯器來描述NVCC。使用nvcc命令列工具我們可以簡化CUDA程式的編譯過程,NVCC編譯器的工作過程主要可以劃分為兩個階段:離線編譯(Offline Compilation)和即時編譯(Just-in-Time Compilation)。
- 離線編譯
離線編譯(Offline Compilation): 在CUDA原始碼中,既包含在GPU裝置上執行的程式碼,也包括在主機CPU上執行的程式碼。因此,NVCC的第一步工作便是將二者分離開來,這一過程結束之後:
運行於裝置端的程式碼將被NVCC工具編譯為PTX程式碼(GPU的彙編程式碼)或者cubin物件(二進位制GPU程式碼);
運行於主機端的程式碼將被NVCC工具改寫,將其中的核心啟動語法(如<<<…>>>)改寫為一系列的CUDA Runtime函式,並利用外部編譯工具(gcc for linux,或者vc compiler for windows)來編譯這部分程式碼,以得到運行於CPU上的可執行程式。 完事之後,NVCC將自動把輸出的兩個二進位制檔案連結起來,得到異構程式的二進位制程式碼。
2 . 即時編譯
任何在執行時被CUDA程式載入的PTX程式碼都會被顯示卡的驅動程式進一步編譯成裝置相關的二進位制可執行程式碼。這一過程被稱作即時編譯(just-in-time compilation)。即時編譯增加了程式的裝載時間,但是也使得編譯好的程式可以從新的顯示卡驅動中獲得性能提升。同時到目前為止,這一方法是保證編譯好的程式在還未問世的GPU上執行的唯一解決方案。
在即時編譯的過程中,顯示卡驅動將會自動快取PTX程式碼的編譯結果,以避免多次呼叫同一程式帶來的重複編譯開銷。NVIDIA把這部分快取稱作計算快取(compute cache),當顯示卡驅動升級時,這部分快取將會自動清空,以使得程式能夠自動獲得新驅動為即時編譯過程帶來的效能提升。
>which nvcc //檢測是否install nvcc如下程式碼為cuda-7.5/samples/0-samplePrintf中的例程,先實驗一波。
/*
* Copyright 1993-2015 NVIDIA Corporation. All rights reserved.
// System includes
#include <stdio.h>
#include <assert.h>
// CUDA runtime
#include <cuda_runtime.h>
// helper functions and utilities to work with CUDA
#include <helper_functions.h>
#include <helper_cuda.h>
#ifndef MAX
#define MAX(a,b) (a > b ? a : b)
#endif
__global__ void testKernel(int val)
{
printf("[%d, %d]:\t\tValue is:%d\n",\
blockIdx.y*gridDim.x+blockIdx.x,\
threadIdx.z*blockDim.x*blockDim.y+threadIdx.y*blockDim.x+threadIdx.x,\
val);
}
int main(int argc, char **argv)
{
int devID;
cudaDeviceProp props;
// This will pick the best possible CUDA capable device
devID = findCudaDevice(argc, (const char **)argv);
//Get GPU information
checkCudaErrors(cudaGetDevice(&devID));
checkCudaErrors(cudaGetDeviceProperties(&props, devID));
printf("Device %d: \"%s\" with Compute %d.%d capability\n",
devID, props.name, props.major, props.minor);
printf("printf() is called. Output:\n\n");
//Kernel configuration, where a two-dimensional grid and
//three-dimensional blocks are configured.
dim3 dimGrid(2, 2);
dim3 dimBlock(2, 2, 2);
testKernel<<<dimGrid, dimBlock>>>(10);
cudaDeviceSynchronize();
// cudaDeviceReset causes the driver to clean up all state. While
// not mandatory in normal operation, it is good practice. It is also
// needed to ensure correct operation when the application is being
// profiled. Calling cudaDeviceReset causes all profile data to be
// flushed before the application exits
cudaDeviceReset();
return EXIT_SUCCESS;
}
執行結果如下(呼叫了sample/common/inc中的部分函式):
GPU Device 0: "GeForce GTX 960M" with compute capability 5.0
Device 0: "GeForce GTX 960M" with Compute 5.0 capability
printf() is called. Output:
[3, 0]: Value is:10
[3, 1]: Value is:10
[3, 2]: Value is:10
[3, 3]: Value is:10
[3, 4]: Value is:10
[3, 5]: Value is:10
[3, 6]: Value is:10
[3, 7]: Value is:10
[2, 0]: Value is:10
[2, 1]: Value is:10
[2, 2]: Value is:10
[2, 3]: Value is:10
[2, 4]: Value is:10
[2, 5]: Value is:10
[2, 6]: Value is:10
[2, 7]: Value is:10
[1, 0]: Value is:10
[1, 1]: Value is:10
[1, 2]: Value is:10
[1, 3]: Value is:10
[1, 4]: Value is:10
[1, 5]: Value is:10
[1, 6]: Value is:10
[1, 7]: Value is:10
[0, 0]: Value is:10
[0, 1]: Value is:10
[0, 2]: Value is:10
[0, 3]: Value is:10
[0, 4]: Value is:10
[0, 5]: Value is:10
[0, 6]: Value is:10
[0, 7]: Value is:10
Tips
在嘗試執行helloworld.cu程式時,遇到/bin/..//include/host_config.h:82:2: error: #error – unsupported GNU version! gcc 4.9 and up are not supported!問題:
因為我的cuda版本為7.5,不支援我的gcc,執行如下指令更新gcc版本:
sudo apt-get install gcc-4.8 g++-4.8
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.8 50
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.8 50在執行時執行make命令,自己單獨使用nvcc呼叫還有問題,估計時環境變數的問題,留待明天解決(solver:是因為引用了sample/common/inc中的部分.h檔案)。