
【高效能MySQL】第六章查詢效能優化 查詢優化器侷限
剛才誤關了瀏覽器,啊~~~
6.5MySQL查詢優化器侷限性
6.5.1關聯子查詢
where子查詢實現的非常糟糕,最糟一類where包含in

優化:
exists等效改寫:

或使用group_concat()在in中構造由逗號分隔的列表:【源】
GROUP_CONCAT()函式,主要用來處理一對多的查詢結果,通常會結合GROUP BY一起使用
GROUP_CONCAT([DISTINCT] expr [,expr ...] [ORDER BY {unsigned_integer | col_name | expr} [ASC | DESC] [,col_name ...]] [SEPARATOR str_val])
GROUP_CONCAT後,SELECT裡如果使用了LIMIT是不起作用的
SELECT s.stu_id AS studentId, s.stu_name AS studentName, //數值型別的資料轉化成二進位制BLOB型別 //CAST(expr AS type)或CONVERT(expr, type)將數值型別的資料轉化成字串 GROUP_CONCAT(CAST(c.course_id AS CHAR) ORDER BY c.course_id) AS courseId, GROUP_CONCAT(c.course_name) AS studentCourse FROM student s LEFT JOIN stu_course sc ON s.stu_id = sc.stu_id LEFT JOIN course c ON sc.course_id = c.course_id GROUP BY studentId
如何用好關聯子查詢
上面說子查詢不好,但是沒有絕對真理,具體問題具體分析,explain好工具。值得利用:通過測試驗證猜想
6.5.2union的限制
如希望union各個子句能據limit取部分結果集,或希望先排好序再合併結果集,要在union各個子句中分別使用這些個子句
6.5.3索引合併優化
where子句包多個複雜條件、mysql能訪問單個表的多個索引以合併和交叉過濾的方式來定位需要查詢的行
6.5.4等值傳遞:
某些時候,等值傳遞會帶來些額外消耗
6.5.5並行執行
mysql無法利用多核特性來並行執行查詢
6.5.6雜湊關聯
參考第5章自定義雜湊索引
6.5.7鬆散索引掃描
mysql5.6之後的版本,通過索引條件下推方式解決鬆散索引掃描的一些限制
explain的extra欄位顯示using index for group-by 表示使用了鬆散索引掃描
6.6查詢優化器的提示hint
在查詢中加入相應的提示,可控制該查詢的執行計劃
HIGHT_PRIORITY 和 LOW_PRIORITY 執行順序相關
當多個語句同時訪問某一個表時,哪些語句的優先順序高、低
H*:select語句,mysql將其放在表佇列的前面;insert語句,簡單抵消全域性low_priority設定的影響
L*:讓語句一直等待
對使用表鎖的引擎有效,不要在innodb或有細粒度鎖機制 併發控制的引擎中使用:導致併發插入被禁
DELAYED:對insert replace有效
將 使用該提示的語句 立即返回給客戶端,將插入的行資料放入到快取區 在表空閒時批量將資料寫入
不是all的儲存引擎都支援,會導致last_insert_id無法正常工作
STRAIGHT_JOIN: 關聯順序相關
放在select後:查詢中all表按在語句中順序進行關聯
可放任何兩個關聯表的名字間:固定器前後兩表的關聯順序
可使explain語句查優化器選擇的關聯順序,然後使用該提示重寫查詢,在看順序,升級需重審視查詢
SQL_SMALL_RESULT和SQL_BIG_RESULT:select
告訴優化器對group by或distinct查詢如何使用臨時表及排序
*SM*:告訴器結果集會很小,可將結果集放在記憶體的索引臨時表,避免排序
*B*:告訴器結果集可能非常大,建議使用磁碟臨時表做排序操作
SQL_BUFFER_RESULT:
告訴器將查詢結果放入到一臨時表,儘可能快地釋放表鎖,伺服器端需more記憶體,客戶端稍解放
SQL_CACHE和SQL_NO_CACHE:
這個結果集是否應該快取在查詢快取中
SQL_CALC_FOUND_ROWS:
讓返回的結果集包含more資訊,不應該使用,可通found_row獲得這個值
FOR UPDATE和LOCK IN SHARE MODE:只對實現了行級鎖的引擎有效
控制select語句鎖機制,會對符合查詢條件的資料行加鎖,避免使用,鎖掙用
USE INDEX 、IGNORE INDEX和FORCE INDEX:
使用或不使用哪些索引來查詢記錄
5.1及後可通過FOR ORDER BY 和FOR GROUP BY指定是否對排序和分組有效
force index同use index(除for*會告訴優化器全表掃描成本高於索引掃描)
5.6新增:
1、optimizer_search_depth:控制優化器在窮舉執行計劃時的限度
2、optimizer_prune_level:預設開啟,讓優化器據需要掃描的行數來決定是否跳過某些執行計劃
3、optimizer_switch:包含些開啟/關閉優化器特性的標誌位
前兩個引數控制優化器走一些捷徑:讓優化器處理複雜sql時仍高效,但也可能錯過些真正最優的執行計劃
自定義設定的 優化器提示 可能使新版的優化策略失效:耍小聰明 不太好
6.7優化特定型別的查詢
多數優化技巧和特定版本有關,注意版本
6.7.1優化count查詢
作用:
1、統計某個列的數量、行數,如果count()指定列或列的表示式,統計的是這個表示式有值的結果數 非null
2、統計結果集的行數,mysql確認()內表示式值不為空,便是在統計行數
關於MyISAM:無where的count會非常快
取小的範圍、近似值、彙總表、快取系統
6.7.2優化關聯查詢
1、確保on或using子句中列上有索引,無其他理由,只在關聯順序的第二張表相應列建索引
2、group by 和order by 的表示式只涉及一個表中的列,才能使用索引
3、版本升級,注意關聯語法、運算子優先順序等可能發生變化的地方
6.7.3優化子查詢
儘可能使用關聯查詢代替,mysql5.6及更新的版本或mariadb可忽略
6.7.4優化group by和distinct
可使用索引來優化
無法使用索引時:
group by使用臨時表或檔案排序做分組,可通過提示sql_big_result和sql_samll_result‘指揮’優化器
對關聯查詢做分組,且按照查詢表的某個列進行分組,採用查詢表的標識列來分組的效率會更高
優化group by with rollup:
如對返回分組結果再做一次超級聚合,可使用with rollup實現,儘可能將with rollup功能轉移到程式中處理
6.7.5優化limit分頁
偏移量很大但是要的資料很少,優化 要麼在頁面中限制分頁的數量 要麼優化大偏移量的效能
1、儘可能使用索引覆蓋掃描,據需要做一次關聯操作再返回需要的列
2、
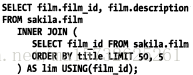
延遲關聯:提效率,掃描儘可能少的頁,獲取要訪問的記錄後據關聯列回原表查詢需的列
3、將limit查詢轉換為已知位置的查詢,讓mysql通過範圍掃描獲得對應的結果
預先計算出邊界值,between * and *,limit 20 ,下次從20個後開始
6.7.6優化SQL_CALC_FOUND_ROWS:
分頁時,技巧在limit語句中加SQL_CALC_FOUND_ROWS提示,可獲得去掉limit後滿足條件的行數,作為分頁的總數,會掃描all滿足條件的行、拋棄不需要的行,代價可能有點高
1、將具體的頁數換成“下一頁”按鈕,每頁顯示20條但查詢21條哦,21條存在則有資料,否則沒有資料(哈哈~優秀優秀)
2、先獲取快取較多資料,每次分頁從快取中獲取:程式據結果集大小採取不同策略,<1000 顯示all分頁連結 >1000 靈活設計 比 找到all再拋棄效率高
使用explain結果中的rows值作為結果集總數的近似值,需精確結果再count(*)
6.7.7使用者union查詢
通過建立、填充臨時表來執行union查詢,很多優化策略在union中無法很好使用,需要手工將where 、limit、 order by 等下推到union各個子查詢中,讓優化器充分利用這些條件進行優化
除非需要伺服器消除重複行,否則一定要使用union all ,無all ,mysql會給臨時表加上distinct:導致對臨時表做唯一性查詢,代價高
6.7.8靜態查詢分析
percona toolkit 的pt-query-advisor能解析查詢日誌、分析查詢模式、給出all可能會有潛在問題的查詢、給出建議