Zookeeper + Hadoop2.6 叢集HA + spark1.6完整搭建與所有引數解析
安裝環境變數:
使用linx下的解壓軟體,解壓找到裡面的install 或者 ls 執行這個進行安裝
yum install gcc
yum install gcc-c++
安裝make,這個是自動編譯原始碼的工具
yum install make
yum install autoconfautomake libtool cmake
封裝了底層的終端功能
yum install ncurses-devel
OpenSSL是一個軟體包,用於支援SSL傳輸協議的軟體包
yum install openssl-devel
git就不用多說了
yum install git git-svn git-email git-gui gitk
安裝protoc(需用root使用者), 作用是把某種資料結構的資訊,以某種格式儲存起來。主要用於資料儲存、傳輸協議格式等
1 tar -xvf protobuf-2.5.0.tar.bz2
2 cd protobuf-2.5.0
3 ./configure --prefix=/opt/protoc/
4 make && make install
安裝wget (以後備用~)
sudo yum -y install wget
二、增加使用者組
groupadd hadoop 新增一個組
useradd hadoop -g hadoop 新增使用者
三、編譯hadoop
mvn clean package -Pdist,native -DskipTests -Dtar
編譯完的hadoop在 /home/hadoop/ocdc/hadoop-2.6.0-src/hadoop-dist/target 路徑下
四、各節點配置hosts檔案 vi/etc/hosts
10.1.245.244 master
10.1.245.243 slave1
10.1.245.242 slave2
命令列輸入 hostname master
ssh到其他主機 相應輸入 hostName xxxx
五、各節點免密碼登入:
各節點 免密碼登入
ssh-keygen -t rsa
cd /root/.ssh/
ssh-copy-id master
將生成的公鑰id_rsa.pub 內容追加到authorized_keys(執行命令:cat id_rsa.pub >> authorized_keys)
時間等效性同步
ssh master date; ssh slave1 date;ssh slave2 date;
六、hadoop路徑下建立相應目錄(namenode,datenode 等資訊存放處)
Mkdir data
(在data路徑下建立目錄)
mkdir yarn
mkdir jn
mkdir current
(hadoop路徑下)
mkdir name
(jn目錄下)
mkdir streamcluster
七、Zookeeper叢集配置:
解壓zookeeper
Tar zxvf zookeeper-3.4.6.tar.gz
修改temp檔案為可用
Cp zoo_sample.cfg zoo.cfg
修改zoo.cfg檔案:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/hadoop/ocdc/zookeeper-3.4.6/data
dataLogDir=/home/hadoop/ocdc/zookeeper-3.4.6/logs
# the port at which the clients will connect
clientPort=2183
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
#寫入節點ip與埠
server.1=master:2898:3898
server.2=slave1:2898:3898
server.3=slave2:2898:3898
在zookeeper目錄下:
mkdir data
vi myid (寫入id為1,)
拷貝zookeeper到各個目錄下(將slave1中的myid改為2,slave2中的myid改為3....)
隨後在 bin目錄下 逐個啟動zookeeper
./zkServer.sh start
./zkServer.sh status (檢視狀態)
八、hadoop相關配置檔案及引數說明
core-site.xml
預設檔案系統的名稱,如果是HA模式,不加埠
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs:// streamcluster </value>
</property>
io.file.buffer.size都被用來設定快取的大小,較大的快取可以提供高效的資料傳輸,但太大也會造成更大的記憶體消耗和延遲
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
hadoop檔案系統依賴的基本配置,很多配置路徑都依賴它,它的預設位置在/tmp/{$user}下面
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/ocdc/hadoop-2.6.0/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
叢集的邏輯名,要注意的是,如果為HA模式,需要與core-site.xml中的fs.defaultFS名一致
<property>
<name>dfs.nameservices</name>
<value>streamcluster</value>
</property>
datanode的埠,執行tcp/ip伺服器以支援塊傳輸,預設為0.0.0.0:50010
<property>
<name>dfs.datanode.address</name>
<value>0.0.0.0:50012</value>
</property>
datanode的http伺服器地址和埠
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50077</value>
</property>
datanode的rpc伺服器的地址和埠, 提供程序間互動通訊
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50022</value>
</property>
dfs.ha.namenodes.[nameservice ID]在名稱服務中每一個nameNode的唯一識別符號,streamcluster為之前配置的nameservice的名稱,這裡配置高可用,所以配置兩個NN
<property>
<name>dfs.ha.namenodes.streamcluster</name>
<value>nn1,nn2</value>
</property>
由namenode儲存元資料的目錄地址
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/ocdc/hadoop-2.6.0/name</value>
<final>true</final>
</property>
由datanode存放資料塊的目錄列表
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/ocdc/hadoop-2.6.0/data</value>
<final>true</final>
</property>
由寫操作所需要建立的最小副本數目
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
如果是 true,則開啟許可權系統
<property>
<name>dfs.permission</name>
<value>true</value>
</property>
設定成true, 通過知道每個block所在磁碟,可以在排程cpu資源時讓不同的cpu讀不同的磁碟,避免查詢內和查詢間的IO競爭
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
是否在HDFS中開啟許可權檢查。
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
HA模式下該引數為streamcluster中namenode1節點對外服務的RPC地址
<property>
<name>dfs.namenode.rpc-address.streamcluster.nn1</name>
<value>master:8033</value>
</property>
HA模式下該引數為streamcluster中namenode1節點對外服務的RPC地址
<property>
<name>dfs.namenode.rpc-address.streamcluster.nn2</name>
<value>slave1:8033</value>
</property>
HA模式下該引數為streamcluster中namenode1節點對外服務的HTTP地址
<property>
<name>dfs.namenode.http-address.streamcluster.nn1</name>
<value>master:50083</value>
</property>
HA模式下該引數為streamcluster中namenode1節點對外服務的HTTP地址
<property>
<name>dfs.namenode.http-address.streamcluster.nn2</name>
<value>slave1:50083</value>
</property>
設定的為journalNode的地址,Activity狀態中的Namenode會將edits的Log寫入JournalNode,而standby狀態中的Namenode會讀取這些edits log.
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8489;slave1:8489;slave2:8489/streamcluster</value>
</property>
JournalNode 所在節點上的一個目錄,用於存放 editlog 和其他狀態資訊。
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/ocdc/hadoop-2.6.0/data/jn</value>
</property>
journalNode RPC服務地址和埠
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8489</value>
</property>
journalNode HTTP服務地址和埠
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8484</value>
</property>
此引數為客戶端與activity狀態下的Namenode進行互動的java實現類,DFS客戶端通過該類尋找當前activity的Namenode
<property>
<name>dfs.client.failover.proxy.provider.streamcluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
使HA模式下不會同時出現兩個master,不允許出現兩個activity狀態下的Namenode
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
SSH的超時時間設定,倘若超過此時間,則認為執行失敗.
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>10000</value>
</property>
指定streamcluster的兩個NameNode共享edits檔案目錄時,使用的JournalNode叢集資訊
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
每個datanode任一時刻可以開啟的檔案數量上限。
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
DataNode傳送資料出入的最大執行緒數,等同於dfs.datanode.max.xcievers。
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>4096</value>
</property>
塊的位元組大小
<property>
<name>dfs.blocksize</name>
<value>67108864</value>
</property>
一般原則是將其設定為叢集大小的自然對數乘以20,即20logN, NameNode有一個工作執行緒池用來處理客戶端的遠端過程呼叫及叢集守護程序的呼叫。處理程式數量越多意味著要更大的池來處理來自不同DataNode的併發心跳以及客戶端併發的元資料操作。
<property>
<name>dfs.namenode.handler.count</name>
<value>20</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2183,slave1:2183,slave2:2183</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- Resource Manager Configs -->
NodeManager的心跳間隔
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
是否啟用RM HA,預設為false(不啟用)。這裡設定為啟用。
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
是否啟用自動故障轉移。預設情況下,在啟用HA時,啟用自動故障轉移。
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
啟用內建的自動故障轉移。預設情況下,在啟用HA時,啟用內建的自動故障轉移。
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
叢集的ID,確保ResourceManager不會為成為其他叢集的Activity活躍狀態。
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-rm-cluster</value>
</property>
HA下兩個ResourceManager的邏輯名稱
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
用於標識ResourceManager,這裡要注意一點,HA備用的RM的伺服器需要修改為rm2
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
啟用重啟ResourceManager的功能,預設為false
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
用於狀態儲存的類,可以設定為
org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore,基於Hadoop檔案系統的實現,這裡的設定是基於ZooKeeper的實現
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
儲存RM狀態的ZooKeeper Znode全路徑。
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>master:2183,slave1:2183,slave2:2183</value>
</property>
被RM用於狀態儲存的ZooKeeper伺服器的主機:埠號
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2183,slave1:2183,slave2:2183</value>
</property>
Scheduler失聯等待的時間
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
ResourceManager1的地址和埠
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>master:23140</value>
</property>
ResourceManager1排程器地址:埠
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>master:23130</value>
</property>
ResourceManager 1對外web ui地址。可通過該地址在瀏覽器中檢視叢集各類資訊。
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master:23188</value>
</property>
NodeManager通過該地址向ResourceManager1彙報心跳,領取任務等的地址。
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>master:23125</value>
</property>
ResourceManager 1對管理員暴露的訪問地址。管理員通過該地址向RM傳送管理命令等。
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>master:23141</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>master:23142</value>
</property>
HA ResourceManager2相關引數同上 rm1
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>slave1:23140</value>
</property>
HA ResourceManager2相關引數同上 rm1
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value> slave1:23130</value>
</property>
HA ResourceManager2相關引數同上 rm1
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value> slave1:23188</value>
</property>
HA ResourceManager2相關引數同上 rm1
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value> slave1:23125</value>
</property>
HA ResourceManager2相關引數同上 rm1
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value> slave1:23141</value>
</property>
HA ResourceManager2相關引數同上 rm1
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value> slave1:23142</value>
</property>
<!-- Node Manager Configs -->
localizer IPC
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:23344</value>
</property>
http服務埠
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:23999</value>
</property>
通過該配置,使用者可以自定義一些服務,例如Map-Reduce的shuffle功能就是採用這種方式實現的,可執行mapReduce程式
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
之前定義了為mapreduce_shuffle,那麼相對應屬性的類就定義為org.apache.hadoop.mapred.ShuffleHandle
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
NodeManager會通過引數yarn.nodemanager.local-dirs配置一系列目錄(磁碟),用於儲存Application中間結果(比如MapReduce中Map Task的中間輸出結果)
<property>
<name>yarn.nodemanager.local-dirs</name>
<value> /home/hadoop/ocdc/hadoop-2.6.0/data/yarn/local</value>
</property>
同上NodeManager配置的日誌檔案
<property>
<name>yarn.nodemanager.log-dirs</name>
<value> /home/hadoop/ocdc/hadoop-2.6.0/data/yarn/log</value>
</property>
MapReduce JobHistory Server Web UI地址。
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:12345</value>
</property>
每個節點可用的最大記憶體,RM中的兩個值不應該超過此值。此數值可以用於計算container最大數目,即:用此值除以RM中的最小容器記憶體。虛擬記憶體率,是佔task所用記憶體的百分比,預設值為2.1倍;注意:第一個引數是不可修改的,一旦設定,整個執行過程中不可動態修改,且該值的預設大小是8G,即使計算機記憶體不足8G也會按著8G記憶體來使用。
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.4</value>
</property>
每個節點可用的記憶體,單位為MB
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>16384</value>
</property>
單個任務可申請的最大記憶體,預設為8192MB
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
</property>
啟用的資源排程器主類。目前可用的有FIFO、Capacity Scheduler和Fair Scheduler。
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
為applications配置相應的ClassPath
<property>
<name>yarn.application.classpath</name>
<value>
$HADOOP_CONF_DIR,
$HADOOP_COMMON_HOME/share/hadoop/common/*,
$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,
$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,
$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_YARN_HOME/share/hadoop/yarn/*,
$HADOOP_YARN_HOME/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
mapred-site.xml
<configuration>
配置引擎為yarn,如果要配置Tez則改為yarn-tez. 其中的奧妙在於使用了JDK6+的一個特性ServiceLoader類。其為JDK實現了一個依賴注入的機制。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
mapreduce.jobhistory.webapp.address和mapreduce.jobhistory.address引數配置的主機上對Hadoop歷史作業情況經行檢視。
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
mapreduce.jobhistory.webapp.address和mapreduce.jobhistory.address引數配置的主機上對Hadoop歷史作業情況經行檢視。
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
指定壓縮型別,預設是RECORD型別,它會按單個的record壓縮,如果指定為BLOCK型別,它將一組record壓縮,壓縮效果自然是BLOCK好。
<property>
<name>mapred.output.compression.type</name>
<value>BLOCK</value>
</property>
</configuration>
slaves
vi slaves
master1
slave1
slave2
隨後將拷貝配置好的hadoop到各個伺服器中
九、啟動Hadoop各元件
啟動jounalnode
./hadoop-daemon.sh start journalnode
進行namenode格式化
./hadoop namenode -format
格式化後會在根據core-site.xml中的hadoop.tmp.dir配置生成個檔案,之後通過下面命令,啟動namenode程序在namenode2上執行
sbin/hadoop-daemon.sh start namenode
完成主備節點同步資訊
./hdfs namenode –bootstrapStandby
格式化ZK(在namenode1上執行即可, 這句命令必須手工打上,否則會報錯)
./hdfs zkfc –formatZK
啟動HDFS(在namenode1上執行)
./start-dfs.sh
啟動YARN(在namenode1和namenode2上執行)
./start-yarn.sh
在namenode1上執行${HADOOP_HOME}/bin/yarn rmadmin -getServiceState rm1檢視rm1和rm2分別為active和standby狀態
我們在啟動hadoop各個節點時,啟動namenode和datanode,這個時候如果datanode的storageID不一樣,那麼會導致如下datanode註冊不成功的資訊:
這個時候,我們需要修改指定的datanode的current檔案中的相應storageID的值,直接把它刪除,這個時候,系統會動態新生成一個storageID,這樣再次啟動時就不會發生錯誤了。
檢視埠是否佔用
Netstat-tunlp |grep 22
檢視所有埠
Netstat -anplut
十、spark搭建與引數解析
修改spark-env..sh 增加如下引數(路徑根據伺服器上的路徑修改)
HADOOP_CONF_DIR=/home/hadoop/ocdc/hadoop-2.6.0/etc/hadoop/
HADOOP_HOME=/home/hadoop/ocdc/hadoop-2.6.0/
SPARK_HOME=/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/
該引數決定了yarn叢集中,最多能夠同時啟動的EXECUTOR的例項個數。
SPARK_EXECUTOR_INSTANCES=3
設定每個EXECUTOR能夠使用的CPU core的數量。
SPARK_EXECUTOR_CORES=7
該引數設定的是每個EXECUTOR分配的記憶體的數量
SPARK_EXECUTOR_MEMORY=11G
該引數設定的是DRIVER分配的記憶體的大小
SPARK_DRIVER_MEMORY=11G
Spark Application在Yarn中的名字
SPARK_YARN_APP_NAME="asiainfo.Spark-1.6.0"
指定在yarn中執行,提交方式為client
MASTER=yarn-cluster
修改spark-default.conf檔案 (路徑根據伺服器上的路徑修改)
如果沒有適合當前本地性要求的任務可供執行,將跑得慢的任務在空閒計算資源上再度排程的行為,這個引數會引發一些tmp檔案被刪除的問題,一般設定為false
spark.speculation false
如果設定為true,前臺用jdbc方式連線,顯示的會是亂碼
spark.sql.hive.convertMetastoreParquet false
應用程式上載到HDFS的複製份數
spark.yarn.submit.file.replication 3
Spark application master給YARN ResourceManager 傳送心跳的時間間隔(ms)
spark.yarn.scheduler.heartbeat.interal-ms 5000
僅適用於HashShuffleMananger的實現,同樣是為了解決生成過多檔案的問題,採用的方式是在不同批次執行的Map任務之間重用Shuffle輸出檔案,也就是說合並的是不同批次的Map任務的輸出資料,但是每個Map任務所需要的檔案還是取決於Reduce分割槽的數量,因此,它並不減少同時開啟的輸出檔案的數量,因此對記憶體使用量的減少並沒有幫助。只是HashShuffleManager裡的一個折中的解決方案。
spark.shuffle.consolidateFiles true
用來調整cache所佔用的記憶體大小。預設為0.6。如果頻繁發生Full GC,可以考慮降低這個比值,這樣RDD Cache可用的記憶體空間減少(剩下的部分Cache資料就需要通過Disk Store寫到磁碟上了),會帶來一定的效能損失,但是騰出更多的記憶體空間用於執行任務,減少Full GC發生的次數,反而可能改善程式執行的整體效能。這要看你的具體業務邏輯,是cache的多還是計算的多。
spark.storage.memoryFraction 0.3
一個partition對應著一個task,如果資料量過大,可以調整次引數來減少每個task所需消耗的記憶體.
spark.sql.shuffle.partitions 800
Spark SQL在每次執行次,先把SQL查詢編譯JAVA位元組碼。針對執行時間長的SQL查詢或頻繁執行的SQL查詢,此配置能加快查詢速度,因為它產生特殊的位元組碼去執行。但是針對很短的查詢,可能會增加開銷,因為它必須先編譯每一個查詢
spark.sql.codegen true
我們都知道shuffle預設情況下的檔案資料為map tasks * reduce tasks,通過設定其為true,可以使spark合併shuffle的中間檔案為reduce的tasks數目。
spark.shuffle.consolidateFiles true
相關jar包的載入地址
spark.driver.extraClassPath /home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib/mysql-connector-java-5.1.30-bin.jar:/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib/datanucleus-api-jdo-3.2.6.jar:/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib
/datanucleus-core-3.2.10.jar:/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib/datanucleus-rdbms-3.2.9.jar:/home/hadoop/ocdc/spark-1.6.1-bin-hadoop2.6/lib/ojdbc14-10.2.0.3.jar
最終:
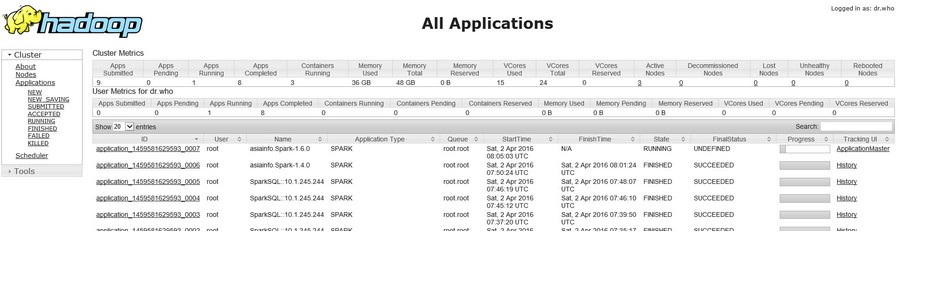
Hadoop監控頁面(根據yarn-site.xml的引數yarn.resourcemanager.webapp.address.rm1中配置的埠決定的):
http://10.1.245.244: 23188
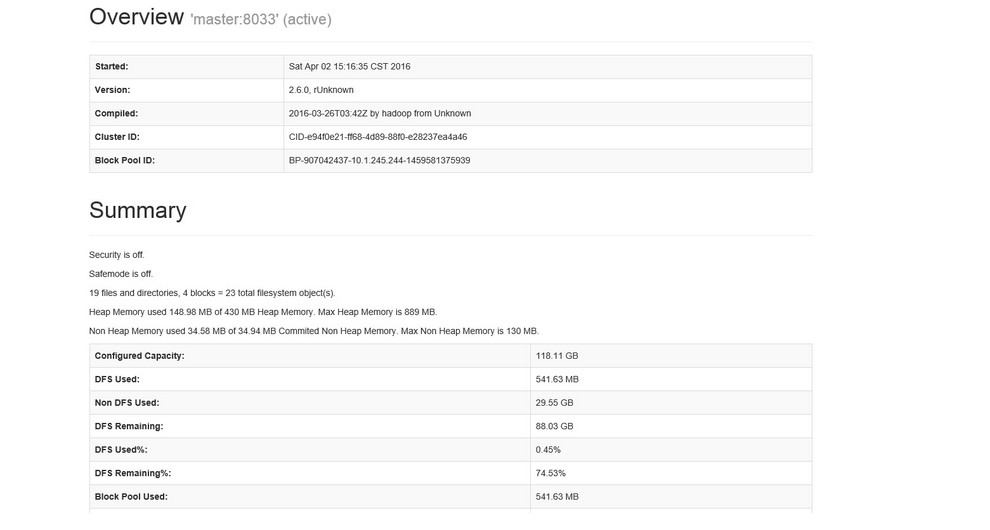
Hadoop namenode監控頁面( 根據hdfs-site.xml中配置的引數 dfs.namenode.http-address.streamcluster.nn1中的埠決定):
http://10.1.245.244: 50083
spark thriftserver註冊啟動: