吳恩達-DeepLearning.ai-05 序列模型(一)
阿新 • • 發佈:2019-01-06
吳恩達-DeepLearning.ai-05 序列模型
迴圈序列模型
1、為什麼選擇序列模型?
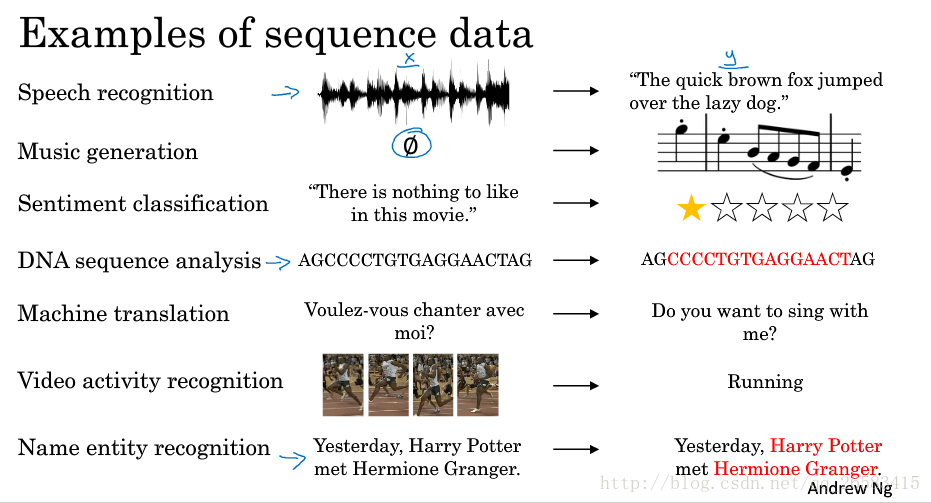
舉了幾個例子:語音識別、音樂生成、情感分析、DNA序列分析、機器翻譯、視訊動作識別、命名實體識別等
2、數學符號
文字資料的表示:命名實體識別中,要識別的內容標籤為1,其他為0,。同時對句子中的詞進行數學符號表示(one-hot,word2vec,glove等)
one-hot詞向量表示: 首先有一個詞袋可以對句子中的詞進行編碼(詞袋越大越好一般3-5萬),然後就可以使用one-hot對句子中的詞進行one-hot編碼,把文字表示為數值形式。

3、迴圈神經網路模型

為什麼用一個標準的神經網路效果不好? 1、在不同的例子中輸入和輸出具有不同的長度,即使通過填充將句子表示為相同的長度,看起來也不太好。 2、不能共享從文字上面不同位置學習到的特徵,既在文字的上個位置學到的特徵希望在下一個位置可以有資訊保留(類似於CNN權值共享),可以減少模型引數。 什麼是迴圈神經網路?

首先把第一個單詞x(1)送入隱層中得到第一個預測結果y'(1),當把第二個單詞x(2)送入隱藏層得到y'(2),不僅用了x(2)的資料資訊,還利用了從第一個時間步驟中得到的a(1),然後重複到y'(Ty)。對於初始化引數a(0)一般為0向量。 迴圈神經網路是從左到右掃描資料,同時每個時間步驟上的輸入引數也是共享的(W_ax),水平軸上的引數也是共享的(W_aa),每個時間步驟上的輸出引數也是共享的(W_ya)表示。 缺點:只使用了當前詞之前的資訊進行預測,沒有考慮後面詞的影響,為了來解決提出了雙向迴圈神經網路(BRNN)。

需要迭代計算的兩個變數a(i)、y(i)的推導公式。

4、迴圈神經網路中的反向傳播(Backpropagation through time,TTBP)
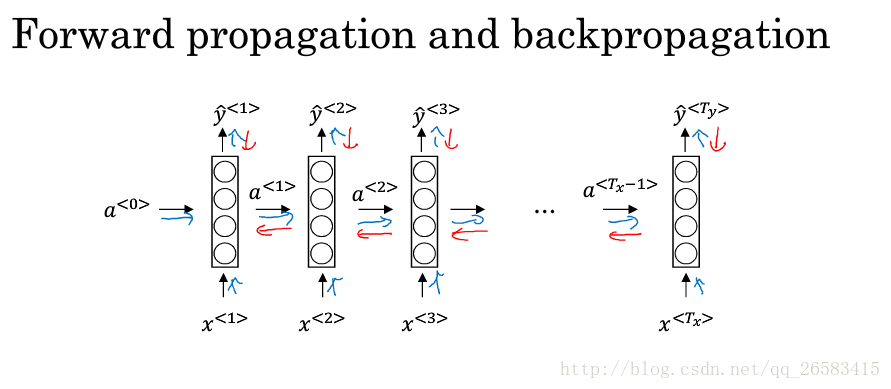
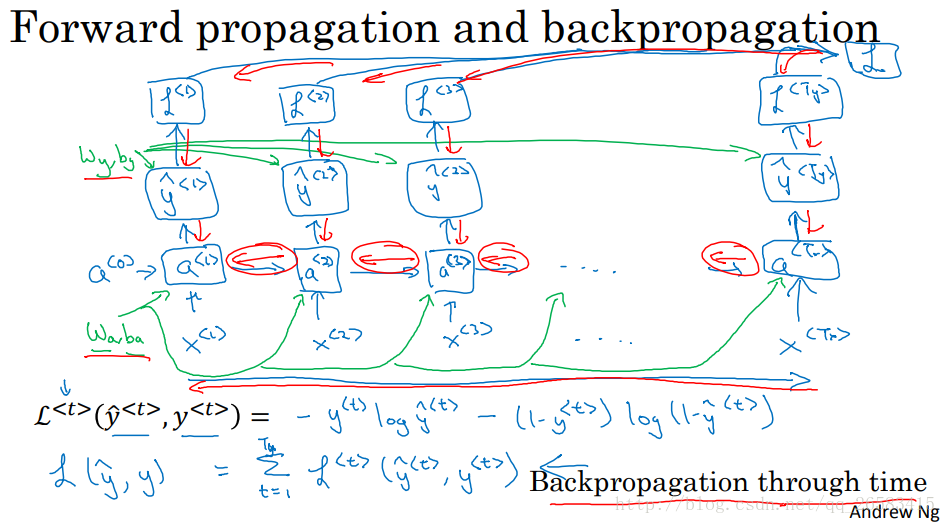
講述了TTBP是怎樣工作的,需要分別計算每個單獨的損失,然後計算損失之和,再使用反向傳播分別優化每個單獨的部分。
5、不同型別的迴圈神經網路
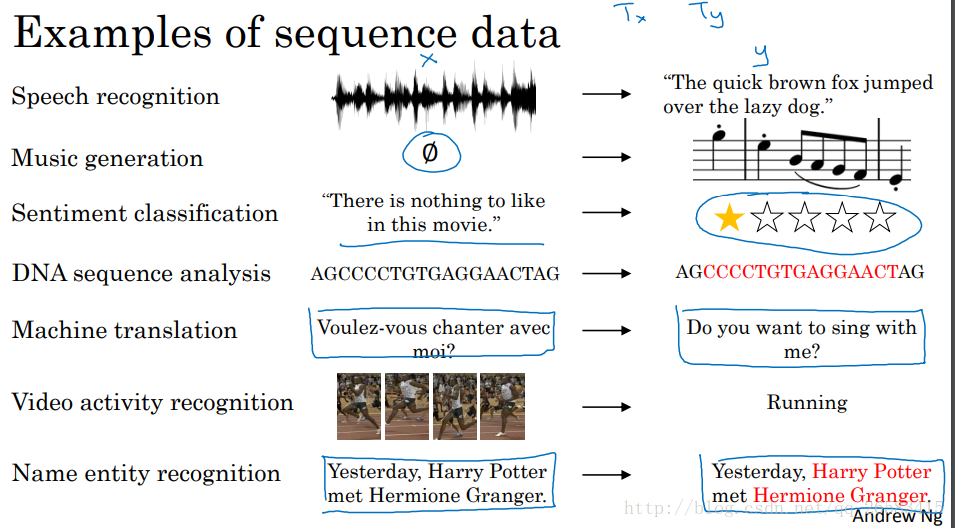
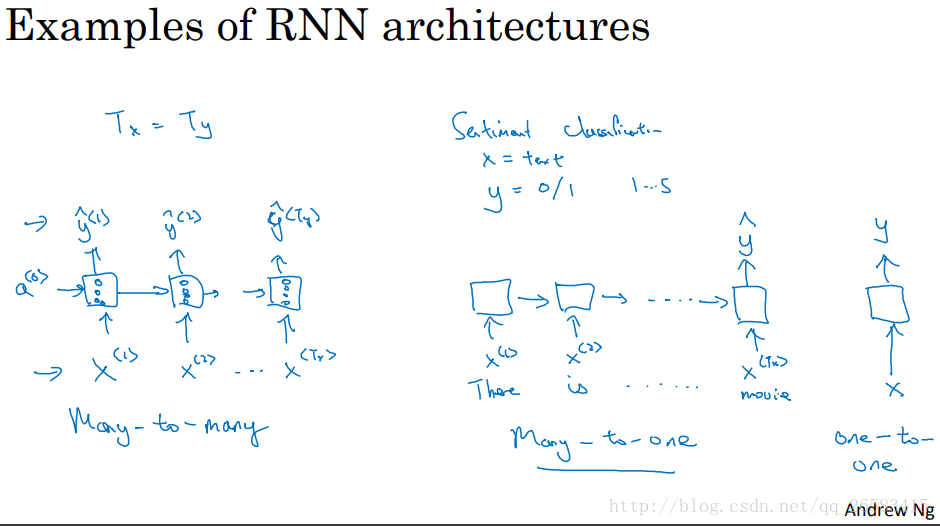
根據前面的不同例子可以分別用不同型別的模型取解決: 語音識別:many-to-many 音樂生成:ont-to-many 情感分析:many-to-one DNA序列分析:many-to-many 機器翻譯:many-to-many 視訊動作識別:many-to-one 命名實體識別:many-to-many

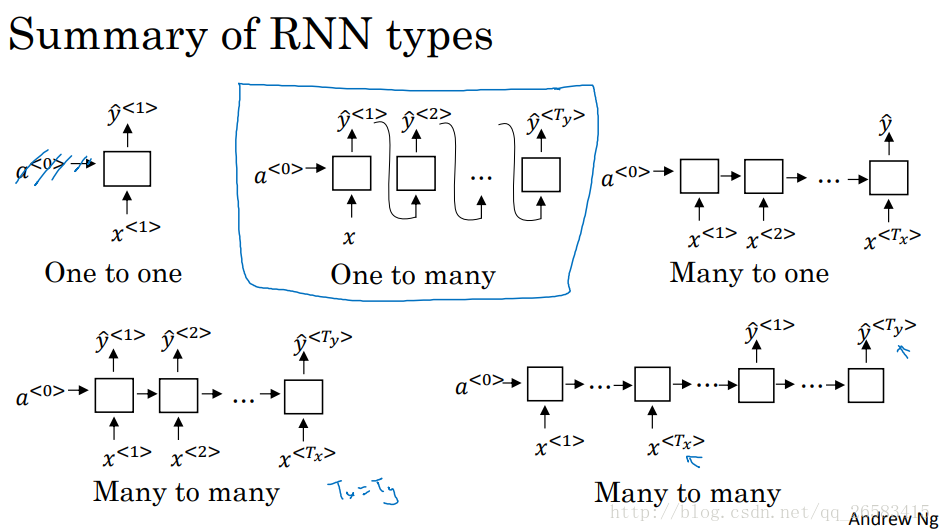
6、語言模型序列生成
什麼是語言模型? 計算出不同句話的概率,對於給定的一段文字序列,語言模型需要判斷各個單詞出現的概率大小。 怎樣建立一個語言模型? 預料——詞袋——詞向量(未知詞表示為UNK)——建立模型(如:RNN)
RNN模型的語言模型建立
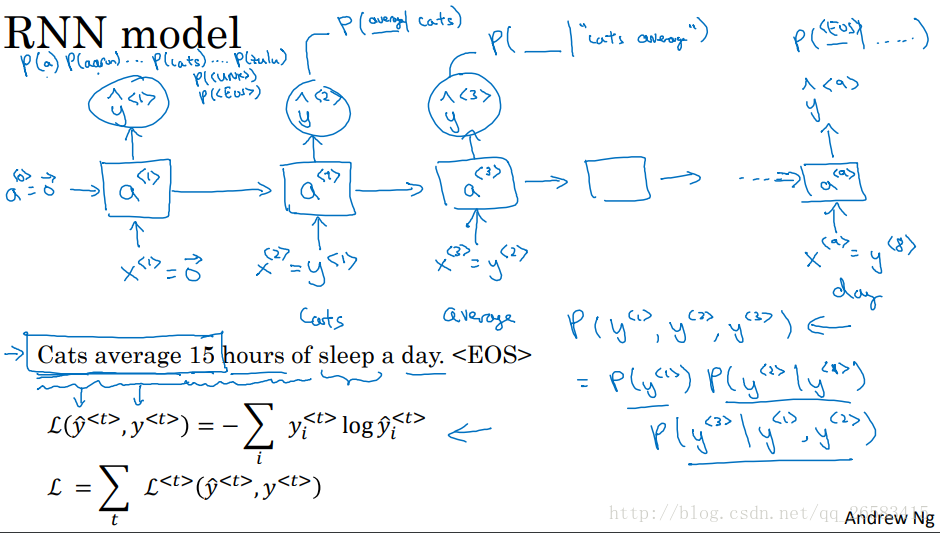
首先給定輸入x(1)=0向量,a(0)=0向量,通過然後輸出層用softmax進行預測詞典中詞出現在這裡的概率作為第一個輸出y'(1)(y'(1)的輸出是softmax的結果,而不管是哪個詞),接下來第二步我們設定x(2)=y(1)(表示直接告訴他第一個正確的此時cats),然後往上傳輸同樣經過softmax得到第二個輸出y'(2),這樣持續傳輸知道句子結尾。 在RNN中每一步都會考慮前面得到的詞,計算出下一個詞的概率(從左到右每次與此一個詞)。
7、從模型中進行取樣
在訓練完一個模型之後,想要知道模型到底學到了什麼?非正式的方法是進行一次新序列的取樣。 一個序列模型模擬了任意特定單詞序列的概率,我們要做的就是對這個單詞序列進行取樣,生成一個新的單詞序列。 取樣: 1、對你想要模型生成的第一個單詞進行取樣(既對第一個softmax的輸出進行隨機取樣)。 2、將剛取樣得到的結果作為第二個的輸入,從覆上面的取樣方法,得到第二個的輸出。 3、重複上面的步驟直到最後,這樣就得到了一串字元表示的句子(基於詞彙的RNN模型)。 基於詞彙的語言模型:單詞為最小變數。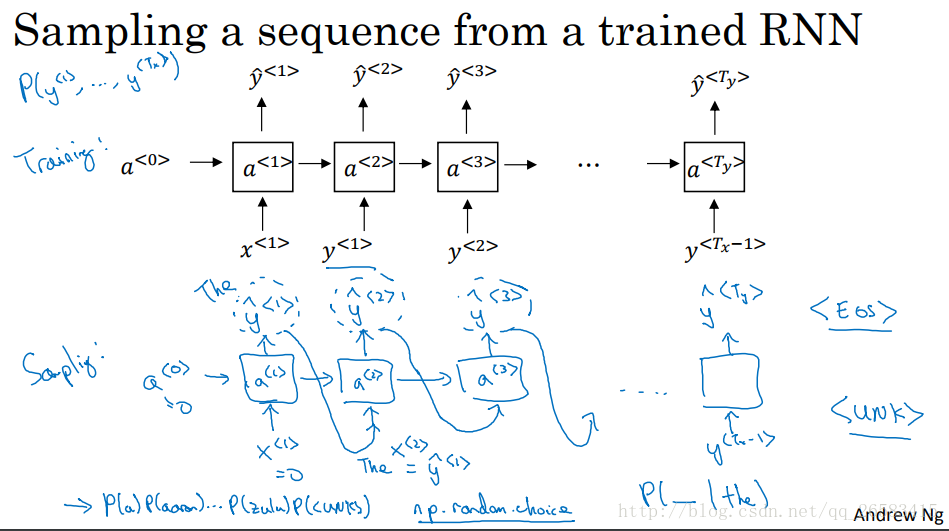 基於字元的語言模型:字母為最小變數。(計算量大,資料量大,目前效果不好,以後可能會好)
基於字元的語言模型:字母為最小變數。(計算量大,資料量大,目前效果不好,以後可能會好)

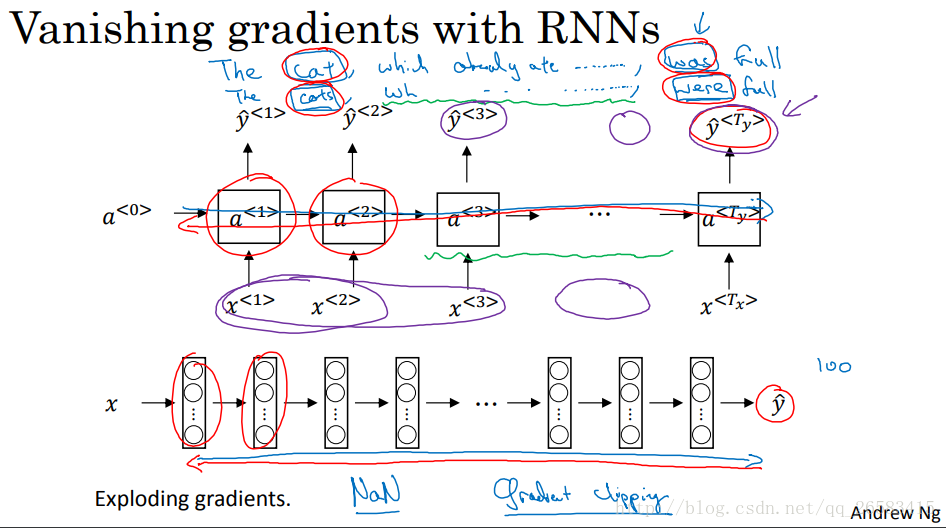
8、RNN神經網路的梯度消失和梯度爆炸
9、GRU單元(門控迴圈單元)
通過改變RNN的隱藏層,使其可以更好地捕捉深層連線(長範圍的依賴),並改善了梯度消失問題。
一個RNN單元的內部結構,基本表示了整個單元的運算流程。 當從左到右讀取文字時,GRU將會有一個新變數c(記憶細胞,提供了記憶能力,例如:對下面句子cat和was單數和複數的判斷,因為儲存了t時刻的資訊),這裡的c(t)=a(t)(LSTM中是不等的),用c'(t)替代表示c(t),公式如下圖。GRU重要的內容:有一個門(值域為[0,1]),公式如下圖。重要的就是這兩個公式用c'(t)來表示c(t)的更新公式,同時用門來決定是否進行更新。用cat和was舉了一個例子,當第一次見到cat時發現是一個新的資訊所以門開啟(假設為1),當後面遇到was時發現這就是單數的所以前面cat的資訊沒有用了,所以可以忘記這個資訊了門再開啟進行更新。從c(t)的真正更新公式可以看到當門的值為0是表示不會更新用的是就得資訊,當為1是表示可以更新用的是當前計算得到的c'(t)值作為更新值。對於下面的英文短句來說在cat時門為1沒到was之前門都是0表示不要更新,知道was時驗證了單數的資訊門又變為1更新為當前資訊。 GRU優點:通過門決定了資訊傳遞的記憶性。同時門的值一般很小(0.00001),所以緩解了梯度消失的問題,可以是模型執行在非常大的依賴詞上


10、長短時記憶網路(LSTM,long short term memory)
在LSTM中a(t)不在和c(t)相等。LSTM對於c(t)的更新反映了LSTM名稱的由來,你通過兩個門一個記憶門一個遺忘門可以選擇記憶或者遺忘。
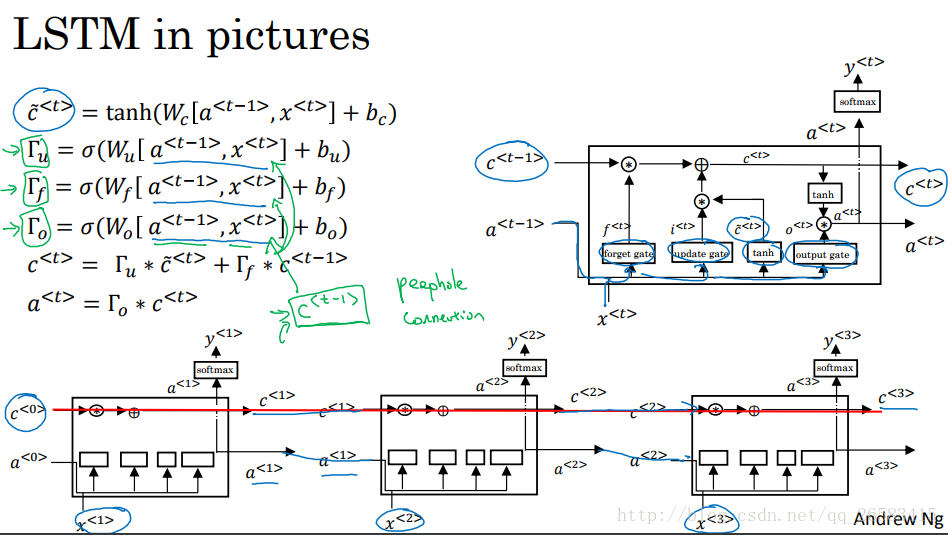
GRU:模型簡單,方便擴充套件,計算速度快,更適合大規模問題。 LSTM:模型靈活多變,計算速度稍慢。
11、雙向迴圈神經網路(Bidirectional RNN)
BRNN:在序列的某點不僅可以獲取之前的資訊而且可以獲取未來的資訊。 特點:同時考慮從左到右以前的資訊,而且考慮從右到左未來的資訊,可以對整個句子的任何位置進行預測,但是模型需要一段完整的資料序列(對於語音識別來說情況複雜,不是很適合),但是大多數的NLP任務都可以得到完整的資料序列,所以BILSTM,是NLP的首選。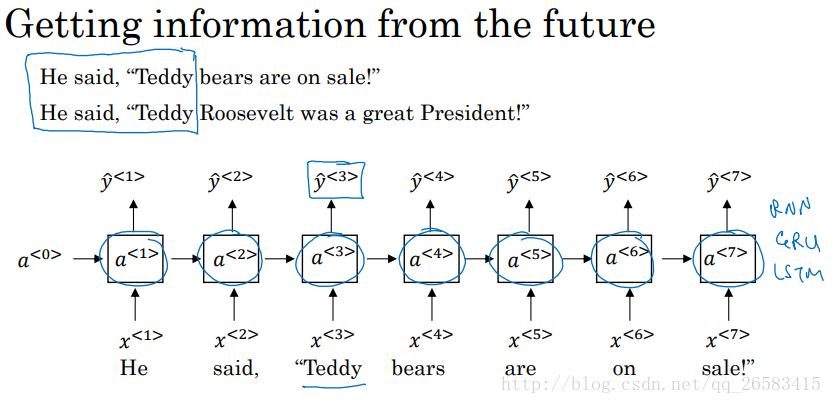

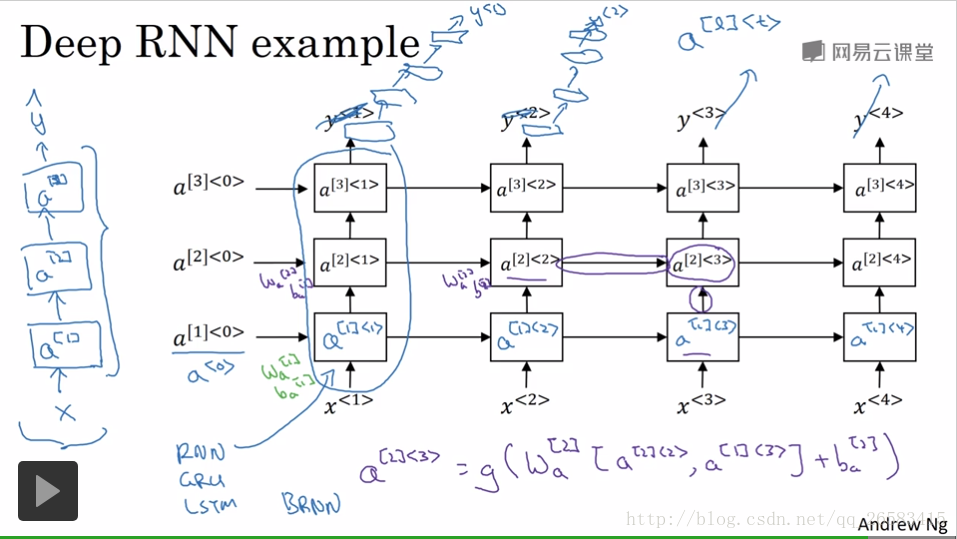
12、深度迴圈神經網路