
樹莓派實現目標實時檢測opencv-Moblenet
1、opencv3.3以上版本安裝
忽略,見部落格
效果圖
在OpenCV3.3版本釋出中把DNN模組從擴充套件模組移到了OpenCV正式釋出模組中,當前DNN模組最早來自Tiny-dnn,可以載入預先訓練好的Caffe模型資料,OpenCV做了近一步擴充套件支援所有主流的深度學習框架訓練生成與匯出模型資料載入,常見的有如下:
Caffe
TensorFlow
Torch/PyTorch
OpenCV中DNN模組已經支援與測試過這些常見的網路模組
AlexNet
GoogLeNet v1 (also referred to as Inception-5h)
ResNet-34/50/…
SqueezeNet v1.1
VGG-based FCN (semantical segmentation network)
ENet (lightweight semantical segmentation network)
VGG-based SSD (object detection network)
MobileNet-based SSD (light-weight object detection network)
一:GoogleNet Caffe模型資料說明
OpenCV通過支援載入這些預先訓練好的模型,實現影象分類、物件檢測、語義分割、風格遷移等功能。支援Android/iOS等移動端平臺開發。下面我們就以OpenCV3.3 使用Caffe的GoogleNet資料模型為例,實現對影象常見分類,OpenCV3.3的DNN模組使用的模型支援1000種常見影象分類、googlenet深度學習網路模型是2014影象分類比賽的冠軍、首先是下載相關的資料模型檔案
bvlc_googlenet.caffemodel
bvlc_googlenet.prototxt
其中prototxt是一個文字的JSON檔案、一看就明白啦,另外一個檔案二進位制檔案。文字檔案只有你下載了OpenCV3.3解壓縮之後就會在對應的目錄發現。模型檔案需要從以下地址下載即可:
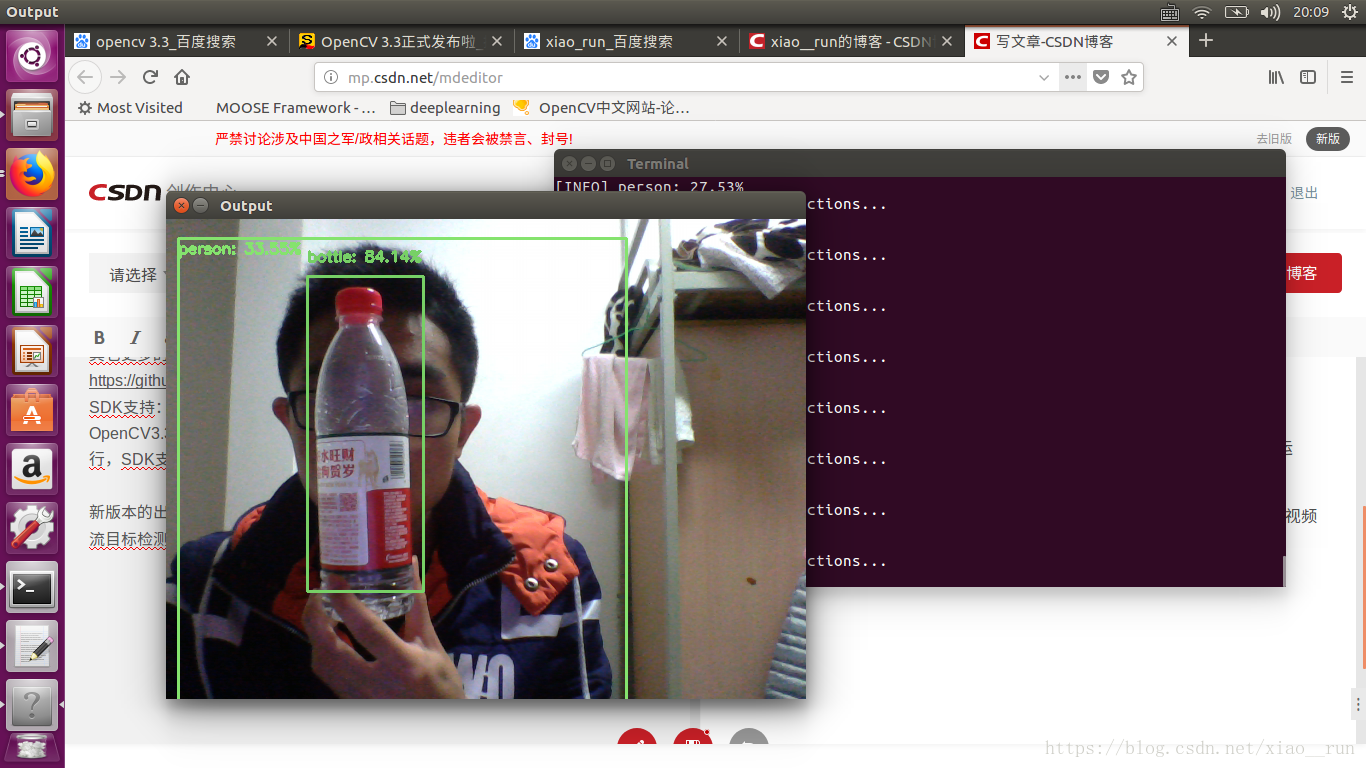
接下來我們用python呼叫Moblenet
# USAGE
# python deep_learning_object_detection.py --image images/example_01.jpg \
# --prototxt MobileNetSSD_deploy.prototxt.txt --model MobileNetSSD_deploy.caffemodel
# import the necessary packages
import numpy as np
import