
基於R-CNN的物體檢測(轉自 hjimce的專欄)
基於R-CNN的物體檢測
作者:hjimce
一、相關理論
本篇博文主要講解2014年CVPR上的經典paper:《Rich feature hierarchies for Accurate Object Detection and Segmentation》,這篇文章的演算法思想又被稱之為:R-CNN(Regions with Convolutional Neural Network Features),是物體檢測領域曾經獲得state-of-art精度的經典文獻。
這篇paper的思想,改變了物體檢測的總思路,現在好多文獻關於深度學習的物體檢測的演算法,基本上都是繼承了這個思想,比如:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》,所以學習經典演算法,有助於我們以後搞物體檢測的其它paper。
之前剛開始接觸物體檢測演算法的時候,老是分不清deep learning中,物體檢測和圖片分類演算法上的區別,弄得我頭好暈,終於在這篇paper上,看到了解釋。物體檢測和圖片分類的區別:圖片分類不需要定位,而物體檢測需要定位出物體的位置,也就是相當於把物體的bbox檢測出來,還有一點物體檢測是要把所有圖片中的物體都識別定位出來。
二、基礎知識
1、有監督預訓練與無監督預訓練
(1)無監督預訓練(Unsupervised pre-training)
無監督預訓練這個名詞我們比較熟悉,棧式自編碼、DBM採用的都是採用無監督預訓練。因為預訓練階段的樣本不需要人工標註資料,所以就叫做無監督預訓練。
(2)有監督預訓練(Supervised pre-training)
所謂的有監督預訓練,我們也可以把它稱之為遷移學習。比如你已經有一大堆標註好的人臉年齡分類的圖片資料,訓練了一個CNN,用於人臉的年齡識別。然後當你遇到新的專案任務是:人臉性別識別,那麼這個時候你可以利用已經訓練好的年齡識別CNN模型,去掉最後一層,然後其它的網路層引數就直接複製過來,繼續進行訓練。這就是所謂的遷移學習,說的簡單一點就是把一個任務訓練好的引數,拿到另外一個任務,作為神經網路的初始引數值,這樣相比於你直接採用隨機初始化的方法,精度可以有很大的提高。
圖片分類標註好的訓練資料非常多,但是物體檢測的標註資料卻很少,如何用少量的標註資料,訓練高質量的模型,這就是文獻最大的特點,這篇paper採用了遷移學習的思想。
2、IOU的定義
因為沒有搞過物體檢測不懂IOU這個概念,所以就簡單介紹一下。物體檢測需要定位出物體的bounding box,就像下面的圖片一樣,我們不僅要定位出車輛的bounding box 我們還要識別出bounding box 裡面的物體就是車輛。對於bounding box的定位精度,有一個很重要的概念,因為我們演算法不可能百分百跟人工標註的資料完全匹配,因此就存在一個定位精度評價公式:IOU。

IOU定義了兩個bounding box的重疊度,如下圖所示:
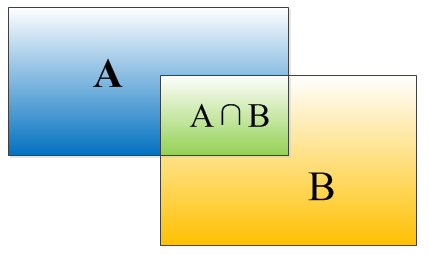
矩形框A、B的一個重合度IOU計算公式為:
IOU=(A∩B)/(A∪B)
就是矩形框A、B的重疊面積佔A、B並集的面積比例:
IOU=SI/(SA+SB-SI)
3、非極大值抑制
因為一會兒講RCNN演算法,會從一張圖片中找出n多個可能是物體的矩形框,然後為每個矩形框為做類別分類概率:

就像上面的圖片一樣,定位一個車輛,最後演算法就找出了一堆的方框,我們需要判別哪些矩形框是沒用的。非極大值抑制:先假設有6個矩形框,根據分類器類別分類概率做排序,從小到大分別屬於車輛的概率分別為A、B、C、D、E、F。
(1)從最大概率矩形框F開始,分別判斷A~E與F的重疊度IOU是否大於某個設定的閾值;
(2)假設B、D與F的重疊度超過閾值,那麼就扔掉B、D;並標記第一個矩形框F,是我們保留下來的。
(3)從剩下的矩形框A、C、E中,選擇概率最大的E,然後判斷E與A、C的重疊度,重疊度大於一定的閾值,那麼就扔掉;並標記E是我們保留下來的第二個矩形框。
就這樣一直重複,找到所有被保留下來的矩形框。
4、VOC物體檢測任務
三、演算法總體思路
開始講解paper前,我們需要先把握總體思路,才容易理解paper的演算法。
圖片分類與物體檢測不同,物體檢測需要定位出物體的位置,這種就相當於迴歸問題,求解一個包含物體的方框。而圖片分類其實是邏輯迴歸。這種方法對於單物體檢測還不錯,但是對於多物體檢測就……
因此paper採用的方法是:首先輸入一張圖片,我們先定位出2000個物體候選框,然後採用CNN提取每個候選框中圖片的特徵向量,特徵向量的維度為4096維,接著採用svm演算法對各個候選框中的物體進行分類識別。也就是總個過程分為三個程式:a、找出候選框;b、利用CNN提取特徵向量;c、利用SVM進行特徵向量分類。具體的流程如下圖片所示:
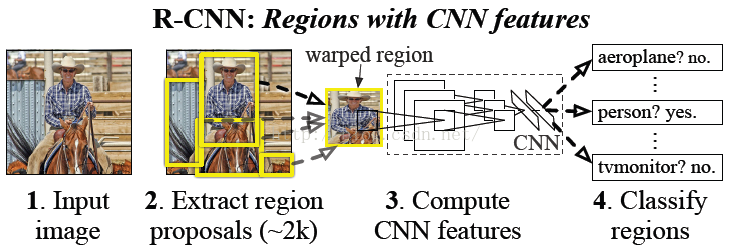
後面我們將根據這三個過程,進行每個步驟的詳細講解。
四、候選框搜尋階段
1、實現方式
當我們輸入一張圖片時,我們要搜尋出所有可能是物體的區域,這個採用的方法是傳統文獻的演算法:《search for object recognition》,通過這個演算法我們搜尋出2000個候選框。然後從上面的總流程圖中可以看到,搜出的候選框是矩形的,而且是大小各不相同。然而CNN對輸入圖片的大小是有固定的,如果把搜尋到的矩形選框不做處理,就扔進CNN中,肯定不行。因此對於每個輸入的候選框都需要縮放到固定的大小。下面我們講解要怎麼進行縮放處理,為了簡單起見我們假設下一階段CNN所需要的輸入圖片大小是個正方形圖片227*227。因為我們經過selective search 得到的是矩形框,paper試驗了兩種不同的處理方法:
(1)各向異性縮放
這種方法很簡單,就是不管圖片的長寬比例,管它是否扭曲,進行縮放就是了,全部縮放到CNN輸入的大小227*227,如下圖(D)所示;
(2)各向同性縮放
因為圖片扭曲後,估計會對後續CNN的訓練精度有影響,於是作者也測試了“各向同性縮放”方案。這個有兩種辦法
A、直接在原始圖片中,把bounding box的邊界進行擴充套件延伸成正方形,然後再進行裁剪;如果已經延伸到了原始圖片的外邊界,那麼就用bounding box中的顏色均值填充;如下圖(B)所示;
B、先把bounding box圖片裁剪出來,然後用固定的背景顏色填充成正方形圖片(背景顏色也是採用bounding box的畫素顏色均值),如下圖(C)所示;

對於上面的異性、同性縮放,文獻還有個padding處理,上面的示意圖中第1、3行就是結合了padding=0,第2、4行結果圖採用padding=16的結果。經過最後的試驗,作者發現採用各向異性縮放、padding=16的精度最高,具體不再囉嗦。
OK,上面處理完後,可以得到指定大小的圖片,因為我們後面還要繼續用這2000個候選框圖片,繼續訓練CNN、SVM。然而人工標註的資料一張圖片中就只標註了正確的bounding box,我們搜尋出來的2000個矩形框也不可能會出現一個與人工標註完全匹配的候選框。因此我們需要用IOU為2000個bounding box打標籤,以便下一步CNN訓練使用。在CNN階段,如果用selective search挑選出來的候選框與物體的人工標註矩形框的重疊區域IoU大於0.5,那麼我們就把這個候選框標註成物體類別,否則我們就把它當做背景類別。SVM階段的正負樣本標籤問題,等到了svm講解階段我再具體講解。
五、CNN特徵提取階段
1、演算法實現
a、網路結構設計階段
網路架構我們有兩個可選方案:第一選擇經典的Alexnet;第二選擇VGG16。經過測試Alexnet精度為58.5%,VGG16精度為66%。VGG這個模型的特點是選擇比較小的卷積核、選擇較小的跨步,這個網路的精度高,不過計算量是Alexnet的7倍。後面為了簡單起見,我們就直接選用Alexnet,並進行講解;Alexnet特徵提取部分包含了5個卷積層、2個全連線層,在Alexnet中p5層神經元個數為9216、 f6、f7的神經元個數都是4096,通過這個網路訓練完畢後,最後提取特徵每個輸入候選框圖片都能得到一個4096維的特徵向量。
b、網路有監督預訓練階段
引數初始化部分:物體檢測的一個難點在於,物體標籤訓練資料少,如果要直接採用隨機初始化CNN引數的方法,那麼目前的訓練資料量是遠遠不夠的。這種情況下,最好的是採用某些方法,把引數初始化了,然後在進行有監督的引數微調,這邊文獻採用的是有監督的預訓練。所以paper在設計網路結構的時候,是直接用Alexnet的網路,然後連引數也是直接採用它的引數,作為初始的引數值,然後再fine-tuning訓練。
網路優化求解:採用隨機梯度下降法,學習速率大小為0.001;
C、fine-tuning階段
我們接著採用selective search 搜尋出來的候選框,然後處理到指定大小圖片,繼續對上面預訓練的cnn模型進行fine-tuning訓練。假設要檢測的物體類別有N類,那麼我們就需要把上面預訓練階段的CNN模型的最後一層給替換掉,替換成N+1個輸出的神經元(加1,表示還有一個背景),然後這一層直接採用引數隨機初始化的方法,其它網路層的引數不變;接著就可以開始繼續SGD訓練了。開始的時候,SGD學習率選擇0.001,在每次訓練的時候,我們batch size大小選擇128,其中32個事正樣本、96個事負樣本(正負樣本的定義前面已經提過,不再解釋)。
2、問題解答
OK,看完上面的CNN過程後,我們會有一些細節方面的疑問。首先,反正CNN都是用於提取特徵,那麼我直接用Alexnet做特徵提取,省去fine-tuning階段可以嗎?這個是可以的,你可以不需重新訓練CNN,直接採用Alexnet模型,提取出p5、或者f6、f7的特徵,作為特徵向量,然後進行訓練svm,只不過這樣精度會比較低。那麼問題又來了,沒有fine-tuning的時候,要選擇哪一層的特徵作為cnn提取到的特徵呢?我們有可以選擇p5、f6、f7,這三層的神經元個數分別是9216、4096、4096。從p5到p6這層的引數個數是:4096*9216 ,從f6到f7的引數是4096*4096。那麼具體是選擇p5、還是f6,又或者是f7呢?
文獻paper給我們證明了一個理論,如果你不進行fine-tuning,也就是你直接把Alexnet模型當做萬金油使用,類似於HOG、SIFT一樣做特徵提取,不針對特定的任務。然後把提取的特徵用於分類,結果發現p5的精度竟然跟f6、f7差不多,而且f6提取到的特徵還比f7的精度略高;如果你進行fine-tuning了,那麼f7、f6的提取到的特徵最會訓練的svm分類器的精度就會飆漲。
據此我們明白了一個道理,如果不針對特定任務進行fine-tuning,而是把CNN當做特徵提取器,卷積層所學到的特徵其實就是基礎的共享特徵提取層,就類似於SIFT演算法一樣,可以用於提取各種圖片的特徵,而f6、f7所學習到的特徵是用於針對特定任務的特徵。打個比方:對於人臉性別識別來說,一個CNN模型前面的卷積層所學習到的特徵就類似於學習人臉共性特徵,然後全連線層所學習的特徵就是針對性別分類的特徵了。
還有另外一個疑問:CNN訓練的時候,本來就是對bounding box的物體進行識別分類訓練,是一個端到端的任務,在訓練的時候最後一層softmax就是分類層,那麼為什麼作者閒著沒事幹要先用CNN做特徵提取(提取fc7層資料),然後再把提取的特徵用於訓練svm分類器?這個是因為svm訓練和cnn訓練過程的正負樣本定義方式各有不同,導致最後採用CNN softmax輸出比採用svm精度還低。
事情是這樣的,cnn在訓練的時候,對訓練資料做了比較寬鬆的標註,比如一個bounding box可能只包含物體的一部分,那麼我也把它標註為正樣本,用於訓練cnn;採用這個方法的主要原因在於因為CNN容易過擬合,所以需要大量的訓練資料,所以在CNN訓練階段我們是對Bounding box的位置限制條件限制的比較鬆(IOU只要大於0.5都被標註為正樣本了);
然而svm訓練的時候,因為svm適用於少樣本訓練,所以對於訓練樣本資料的IOU要求比較嚴格,我們只有當bounding box把整個物體都包含進去了,我們才把它標註為物體類別,然後訓練svm,具體請看下文。
六、SVM訓練、測試階段
這是一個二分類問題,我麼假設我們要檢測車輛。我們知道只有當bounding box把整量車都包含在內,那才叫正樣本;如果bounding box 沒有包含到車輛,那麼我們就可以把它當做負樣本。但問題是當我們的檢測視窗只有部分包好物體,那該怎麼定義正負樣本呢?作者測試了IOU閾值各種方案數值0,0.1,0.2,0.3,0.4,0.5。最後我們通過訓練發現,如果選擇IOU閾值為0.3效果最好(選擇為0精度下降了4個百分點,選擇0.5精度下降了5個百分點),即當重疊度小於0.3的時候,我們就把它標註為負樣本。一旦CNN f7層特徵被提取出來,那麼我們將為每個物體累訓練一個svm分類器。當我們用CNN提取2000個候選框,可以得到2000*4096這樣的特徵向量矩陣,然後我們只需要把這樣的一個矩陣與svm權值矩陣4096*N點乘(N為分類類別數目,因為我們訓練的N個svm,每個svm包好了4096個W),就可以得到結果了。
OK,就講到這邊吧,懶得打字了,打到手痠。
個人總結:學習這篇文獻最大的意義在於作者把自己的試驗過程都講的很清楚,可以讓我們學到不少的調參經驗,真的是很佩服作者背後的思考。因為文獻很長、細節非常之多,本人也對物體檢測不感興趣,只是隨便看看文獻、學學演算法罷了,所以很多細節沒有細看,比如7.3 bounding box的迴歸過程;最後看這篇文獻好累、十幾頁,細節一大堆,包含作者各種實驗、思考……
參考文獻:
1、《Rich feature hierarchies for Accurate Object Detection and Segmentation》
2、《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
**********************作者:hjimce 時間:2015.12.3 聯絡QQ:1393852684 原創文章,轉載請保留原文地址、作者等資訊***************