
python(四)網頁下載器
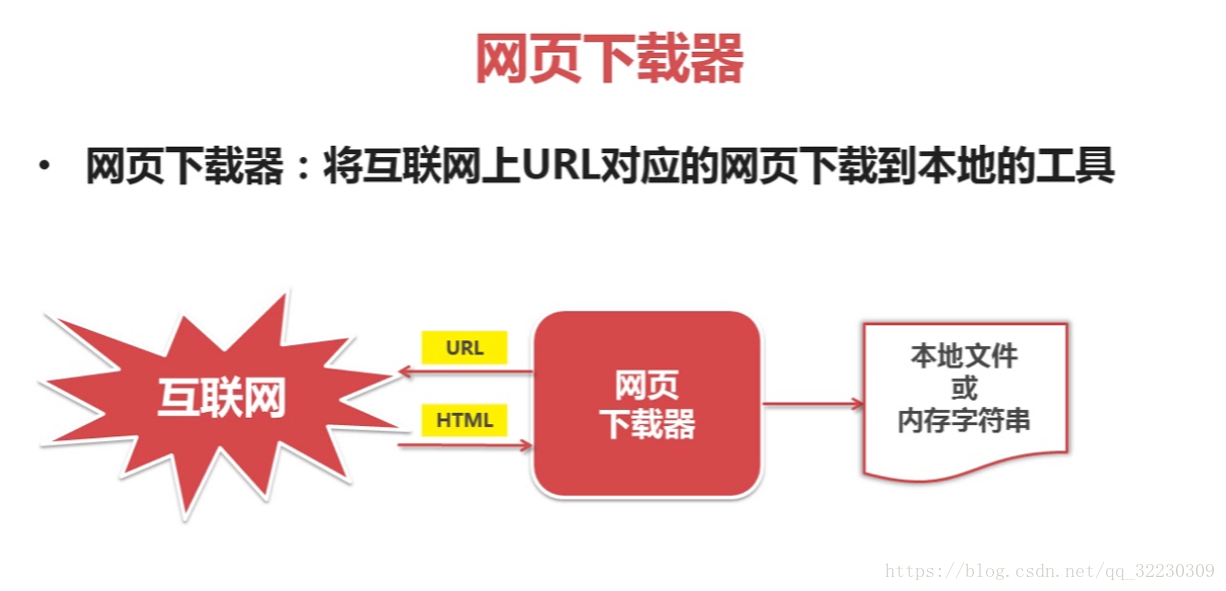
網頁下載器有兩種:
1 urllib2 —Python官網基礎模組
2 requests —第三方包更強大
urllib2
最簡潔的方法
urllib2.urlopen(url)
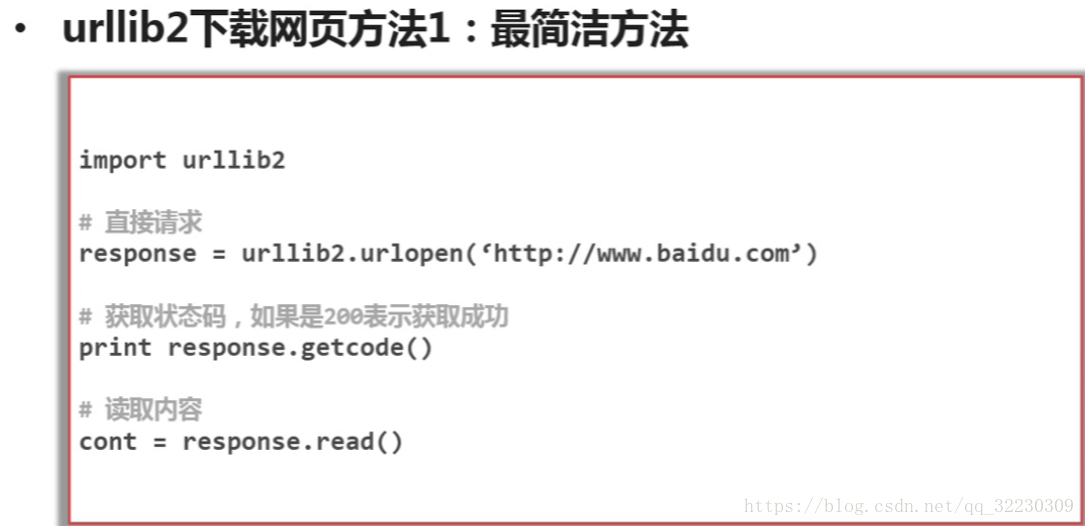
urllib2下載網頁方法2 :新增data,http header

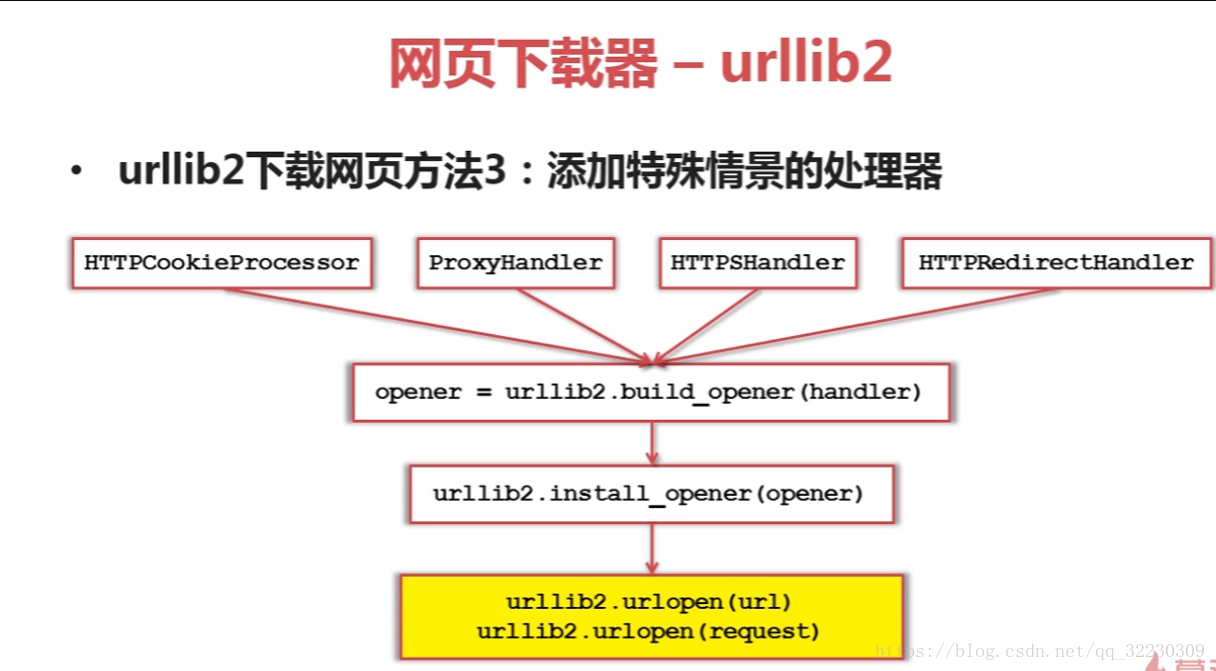
urllib2方法3 :新增特殊情景的處理器
HTTPCookieProcessor :有些網站需要登入才可以使用,我們就用這個.
ProxyHandle:有些網頁需要代理才可用使用,我們用這個.
HTTPSHandler:有些網頁是使用HTTPS加密訪問的,我們使用這個
HTTPRedirectHandler:有些網頁URL自動跳轉的關係,我們使用這個.
舉個coockie的栗子

程式碼栗子:
import urllib.request,http.cookiejar
url = “http://www.baidu.com”
print(“第一種方法”)
response1 = urllib.request.urlopen(url)
print(response1.getcode())
print(len(response1.read()))
print(“第二種方法”)
request = urllib.request.Request(url)
request.add_header(“user-agent”, ‘Mozilla/5.0’)
response2 = urllib.request.urlopen(request)
print(response2.getcode())
print(len(response2.read()))
print(“第三種方法”)
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
urllib.request.install_opener(opener)
response3 = urllib.request.urlopen(url)
print(response3.getcode())
print(cj)
print(response3.read())
學習自:慕課網