
Apache Flink 分散式執行時環境
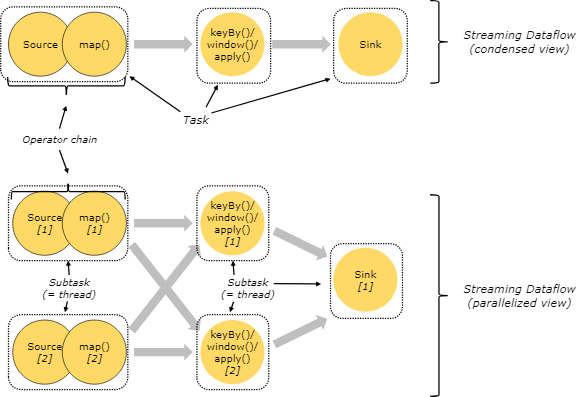
Tasks and Operator Chains(任務及操作鏈)
在分散式環境下,Flink將操作的子任務鏈在一起組成一個任務,每一個任務在一個執行緒中執行。將操作鏈在一起是一個不錯的優化:它減少了執行緒間的切換和緩衝,提升了吞吐量同時減低了時延。這些鏈式行為是可配置的,詳情請見:chaining docs
下圖中的示例以5個子任務來執行,因此有5個併發的執行緒
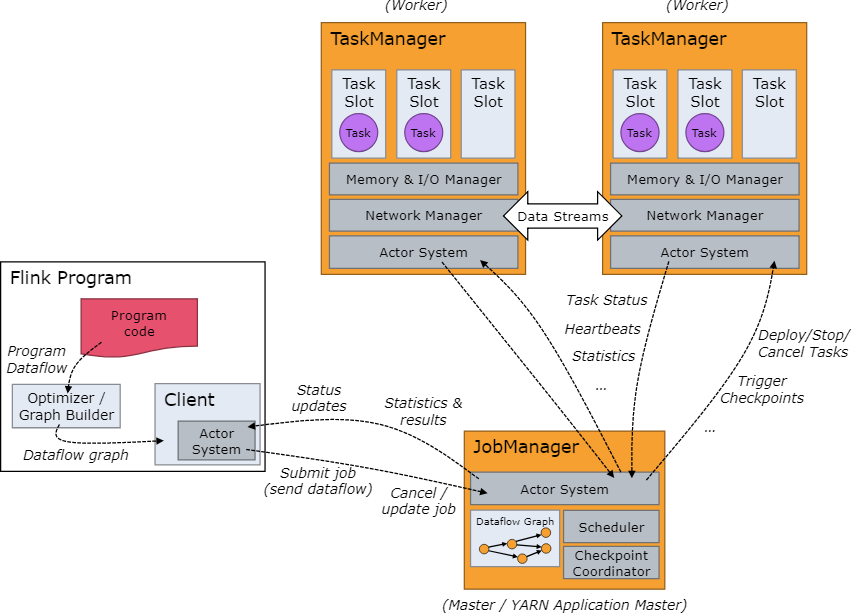
JobManagers, Task Managers, Clients
Flink的執行時環境由兩個程序組成:
- JobManagers :JobManager有時也叫Masters,主要是協調分散式執行。他們排程任務,協調checkpoint,協調失敗任務的恢復等等
一個Flink叢集中至少有一臺JobManager節點。高可用性的叢集中將會有多臺JobManager節點,其中有一臺是leader節點,其他的是備節點(standby)。
- TaskManagers: TaskManagers有時也叫Workers,TaskManager主要是執行dataflow中的任務(tasks),快取資料以及進行資料流的交換。
每一個叢集中至少有一個TaskManager。
JobManager和TaskManager可以有多種啟動方式:直接在物理機上以standalone叢集的形式啟動,在容器中啟動以及通過資源管理框架YARN或者Mesos來啟動。TaskManagers與JobManagers進行通訊,傳送心跳資訊來告知JobManager自己還處於活躍狀態,同時接受JobManager分配的任務。
Client並不是執行時環境或者程式執行的一部分,而是用來準備資料流和將資料流傳送到JobManager中。之後client可以斷開連線,或者繼續保持連線來接收處理報告。Client要麼作為觸發執行的Java/Scala程式的一部分,或者是在命令列程序./bin/flink run …中
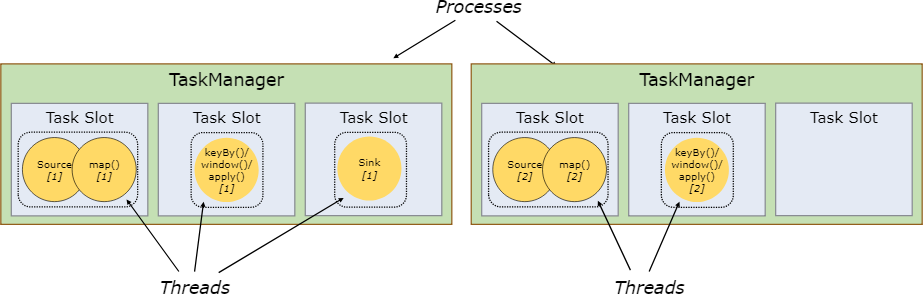
TaskSlots and Resources
每一個worker(TaskManager)是一個JVM程序,並在不同的執行緒中執行著一個或者多個子任務。為了控制每個worker可接受的最大任務數,每個worker需要有個task slots(任務槽)(至少有一個槽)。每一個task slot代表著TaskManager的一個固定的資源子集,例如一個TaskManager有三個slot的話,意味著該TaskManager將會分配1/3的資源到每一個slot中去。將資源納入槽中意味著一個任務不會跟作業中的其他任務競爭託管記憶體,而是會保留一定的託管記憶體。注意:現在的slot還沒有進行CPU的隔離,當前僅僅進行了託管記憶體的隔離。
通過調整slot的數量,使用者可以自定義多少個任務之間彼此隔離。一個TaskManager有一個slot意味著每一個任務執行在一個獨立的JVM程序中。有多個slot意味著多個任務共享一個JVM程序,共享JVM程序的任務之間共享TCP連線和心跳資訊,同時共享資料集和資料結構,從而節省了每個任務的開銷。
預設情況下,Flink允許subtask(子任務)之間共享slot,即使不是來自同一個task(任務),只要這些subtask(子任務)來自同一個作業。結果是一個槽可以持有作業的整個pipeline 。允許slot共享的有兩個好處:
1、Flink叢集需要與作業中使用的最高並行度一樣多的任務槽(task slot),不在需要再去計算一個程式中總共包含了多少了task(任務)。
2、使得獲取更好的資源利用率變得更加容易,沒有slot共享的話,非密集型的source/map子任務將會拆分成與密集型的window子任務一樣多的資源。有了slot共享,就可以提高任務的併發數,從2個到6個,充分利用了槽的資源,也保證了子任務公平地分佈在TaskManager叢集中。
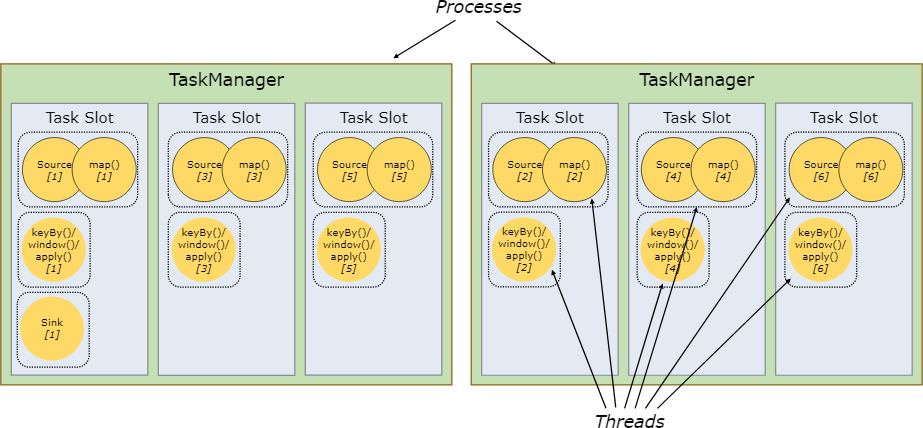
API中還包括了一個資源組機制,可以用來防止不需要的slot共享。
根據經驗法則,最好的slot數量配置是跟CPU核數一致,對於超執行緒,每個slot可以分配兩個或者更多的硬體執行緒上下文。
StateBackends
儲存key/value鍵值索引的切確資料結構取決於所選的state後端。一種state後端是將資料儲存在記憶體的雜湊map中 ,另一種則是以key/value的形式儲存在RocksDB中。除了定義儲存State的資料結構,State後端還實現了一個邏輯來獲取key/value state的時間點快照並作為checkpoint的一部分儲存起來。

Savepoints
用DataStream API書寫的程式可以從一個savepoint 中恢復執行。Savepoint允許更新您的程式而不丟失Flink中的任何state資訊。
Savepoints是手動觸發checkpoint,獲取程式的快照並將快照寫入到state後端。它們依靠定期的checkpoint機制,在執行過程中程式在work節點上產生週期性快照,並生成checkpoint。對於故障恢復,只需要最新生成的checkpoint,舊的checkpoint可以在新的checkpoint生成之後就丟棄掉了。
Savepoints類似於週期性的checkpoint,除了它們是由使用者手動觸發的,並且不會在新的checkpoint生成之後而自動過期。Savepoints可以通過命令列生成或者在取消一個作業時呼叫REST API產生。