
機器學習初步探索
**1、什麼是機器學習?
**機器學習還有模式識別、計算機視覺、語音識別、統計學習以及自然語言處理等,按其種類來說分為監督學習和非監督學習。
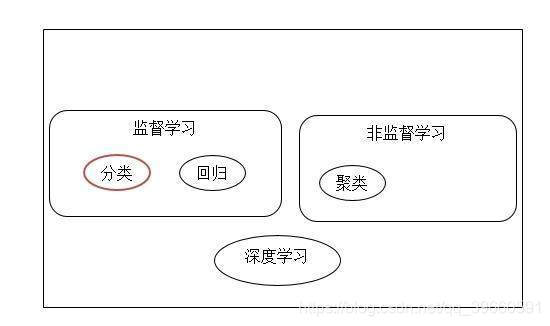
1.1監督學習
1.1.1分類
在文類資訊特徵提取中,向量空間模型(VSM: Vector Space Model),把對文字內容的處理簡化為向量空間中的向量運算,並且它以空間上的相似度表達語義的相似度。它特徵詞條(T1 ,T2 ,…Tn)及其權值Wi來表徵目標文字。在進行資訊匹配時,使用這些特徵項評價未知文字與目標樣本的相關程度。特徵詞條及其權值的選取稱為目標樣本的特徵提取。
比如基於NLP的樸素貝葉斯進行文字分類
以垃圾郵箱分類為例子來說明(以百度某個例子為例我覺得我比較容易理解)
將貝葉斯函式利用到工作中,它能幫助我們幹什麼呢?如果生活中你的工作郵件經常收到各種垃圾郵件,對你來說如果能夠有效的攔截和識別這些垃圾郵件是不是很好的一件事,那麼就有了以下做法:
我們現在要對郵件進行分類,識別垃圾郵件和普通郵件,如果我們選擇使用樸素貝葉斯分類器,那目標就是判斷P(“垃圾郵件”|“具有某特徵”)是否大於1/2。現在假設我們有垃圾郵件和正常郵件各1萬封作為訓練集。需要判斷以下這個郵件是否屬於垃圾郵件:
“我司可辦理正規發票(保真)17%增值稅發票點數優惠!”
也就是判斷概率P(“垃圾郵件”|“我司可辦理正規發票(保真)17%增值稅發票點數優惠!”)是否大於1/2。
計算的方法:就是寫個計數器,然後+1 +1 +1統計出所有垃圾郵件和正常郵件中出現這句話的次數啊,具體點說:
如果真的這麼做了,很多人會覺得如果這樣一個句子去做語料庫是不是太low了,傻子才會將文字資訊一句不差的發給所有人或者每次都是同樣的作弊特徵。本身我們能夠窮舉的訓練集是有限的,而句子的可能性則是無限的。那麼,我們就得找到可替代的方案——切詞/分詞
如果以句子作為訓練集,可能它的組合是無限,但是詞語的搭配都是按照語義去搭配的,我們漢語常用字2500個,常用詞語也就56000個。那麼我們再拆詞的時候就能夠抓住詞的作弊特徵。
比如“我司可辦理正規發票,17%增值稅發票點數優惠!”,這句話就比之前那句話少了“(保真)”這個詞,但是意思基本一樣。那我們可以作為訓練集的樣本數量就會增加,這就方便我們計算了。
我們以詞作為特徵去提取作弊特徵這樣我們可供訓練和提取的特徵明顯多了。eg:“正規發票”、“增值稅”可以作為一個單獨的詞語,如果在工作中再建立體套豁免機制豁免本公司白名單使用者,是不是這些詞明顯能夠提高垃圾郵件的攔截。
句子“我司可辦理正規發票,17%增值稅發票點數優惠!”就可以變為(“我”,“司”,“可”,“辦理”,“正規發票”,“保真”,“增值稅”,“發票”,“點數”,“優惠”))。
我們觀察(“我”,“司”,“可”,“辦理”,“正規發票”,“保真”,“增值稅”,“發票”,“點數”,“優惠”),這可以理解成一個向量:向量的每一維度都表示著該特徵詞在文字中的特定位置存在。這種將特徵拆分成更小的單元,依據這些更靈活、更細粒度的特徵進行判斷的思維方式,在自然語言處理與機器學習中都是非常常見又有效的。
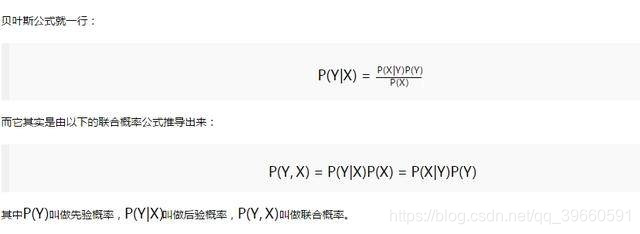
因此貝葉斯公式就變成了:

垃圾郵件識別,說明了一下樸素貝葉斯進行文字分類的思路過程。基本思路是先區分好訓練集與測試集,對文字集合進行分詞、去除標點符號等特徵預處理的操作,然後使用條件獨立假設,將原概率轉換成詞概率乘積,再進行後續的處理。
貝葉斯公式 + 條件獨立假設 = 樸素貝葉斯方法
1.1.2.迴歸
迴歸是由果索因“的過程。可以理解為–當我看到大量的事實所呈現的樣態,我推斷出原因或客觀蘊含的關係。
比如函式 y=wx+b,在給出一些x和y的取值後,我們可以推匯出w和b的取值,這就是簡單的一個迴歸。
迴歸可分為線性迴歸和非線性迴歸兩種。
線性迴歸就是向量和最終的函式值存在一種線性關係。
非線性迴歸在機器學習領域應用最多當屬邏輯迴歸,對於任何向量,這裡的函式值可以假設只存在兩種,即0和1,也可認為是“真”和“假”。
1.2非監督學習
1.2.1聚類分析
比如利用word2vec對關鍵詞進行聚類,加入我們要知道新聞的推薦和關鍵詞有什麼聯絡?首先析,我們收集一批資料,這裡不可能一下子就得到所有詞的集合,最常見的方法是自己寫個爬蟲去收集網頁上的資料,這裡的資料應該說越多越好。其次,我們開始分詞,將一些非文字的資訊去掉,這樣有助於對文字聚類的時候不會出現干擾項。然後利用谷歌開源的word2vec演算法進行聚類分析。由於word2vec計算的是餘弦值,距離範圍為0-1之間,值越大代表這兩個詞關聯度越高,所以越排在上面的詞與輸入的詞越緊密。
2.什麼是訓練集,是用來做什麼的?
訓練集用於建立模型,測試集評估模型的預測等能力。隨機選出一些資料作為模型(訓練集),發現其規律。
3.什麼是測試集,是用來做什麼的?
測試集則檢驗最終選擇最優的模型的效能如何。
一個典型的劃分是訓練集佔總樣本的50%,而其它各佔25%,三部分都是從樣本中隨機抽取。但是,當樣本總量少的時候,上面的劃分就不合適了。常用的是留少部分做測試集。然後對其餘N個樣本採用K折交叉驗證法。就是將樣本打亂,然後均勻分成K份,輪流選擇其中K-1份訓練,剩餘的一份做驗證,計算預測誤差平方和,最後把K次的預測誤差平方和再做平均作為選擇最優模型結構的依據。特別的K取N,就是留一法
測試集方法的代價是要減少一部分訓練資料。例如通常我們從訓練集中移除了30%的資料。這意味著相比於使用全量集合訓練來說,我們的模型會存在更大的偏差。在標準的流程中,評價完模型效果後,我們會用全量資料重新訓練來得到最終的模型。因此在這種情流程下,測試集的誤差評價結果是偏保守的,因為模型的實際誤差要比報告的誤差低一些。在實際中這種保守的誤差估計要比樂觀的誤差估計更有效。
這種技術的一個要點是在得到最終模型前不能以任何方式分析或使用測試集。一個常見錯誤是在效果評估後重新調整模型然後再次訓練評估。如果在一次建模中你重複使用一份測試集,這份測試集就被汙染了。由於測試集參與了模型調整,它就不能再給出模型誤差的一個無偏估計了。
4.什麼是模型
就是用來描述輸入輸出關係的函式
常用經典模型
1.線性迴歸:有監督迴歸,y=WX+b,X為m維向量,y、b為n維向量,W為n*m維矩陣
2.Logistic迴歸:有監督迴歸,y=logit(WX+b)
3.貝葉斯:有監督分類,最可能的分類是概率最大的分類
4.k近鄰:有監督分類,kNN,距離的定義
5.決策樹:有監督分類,樹形判斷分支,非線形邊界,+整合=隨機森林
6.支援向量機:有監督分類,將原空間變換到另一空間,在新空間裡尋找margin最大的分介面(hyperplane)
7.k-means:無監督聚類,初始化中心,不斷迭代,EM演算法
8.神經網路:有監督和無監督都有