
跟我學storm教程2-並行機制及資料流分組
阿新 • • 發佈:2019-01-06
topology的四個組成部分
Nodes(伺服器)
- 即為storm叢集中的supervisor,會執行topology的一部分運算,一個storm叢集一般會有多個node
workers(JVM虛擬機器)
- node節點上執行的相互獨立的jvm程序,每個節點上可以執行一個或者多個worker。一個複雜的topology會分配到多個worker上執行。
Executor(執行緒)
- 指某個jvm程序中執行的java執行緒。多個task可以指派給同一個executor執行。storm預設給每個executor分配一個task。
task(spout/bolt例項)
- task是spout或者bolt的例項,他們的netTuple()和execute()方法會被executor執行緒呼叫執行
示例
builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
// SentenceSpout --> SplitSentenceBolt
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2)
.setNumTasks(4)
.shuffleGrouping(SENTENCE_SPOUT_ID); 如上述配置的拓撲,其併發示意圖如下圖所示:
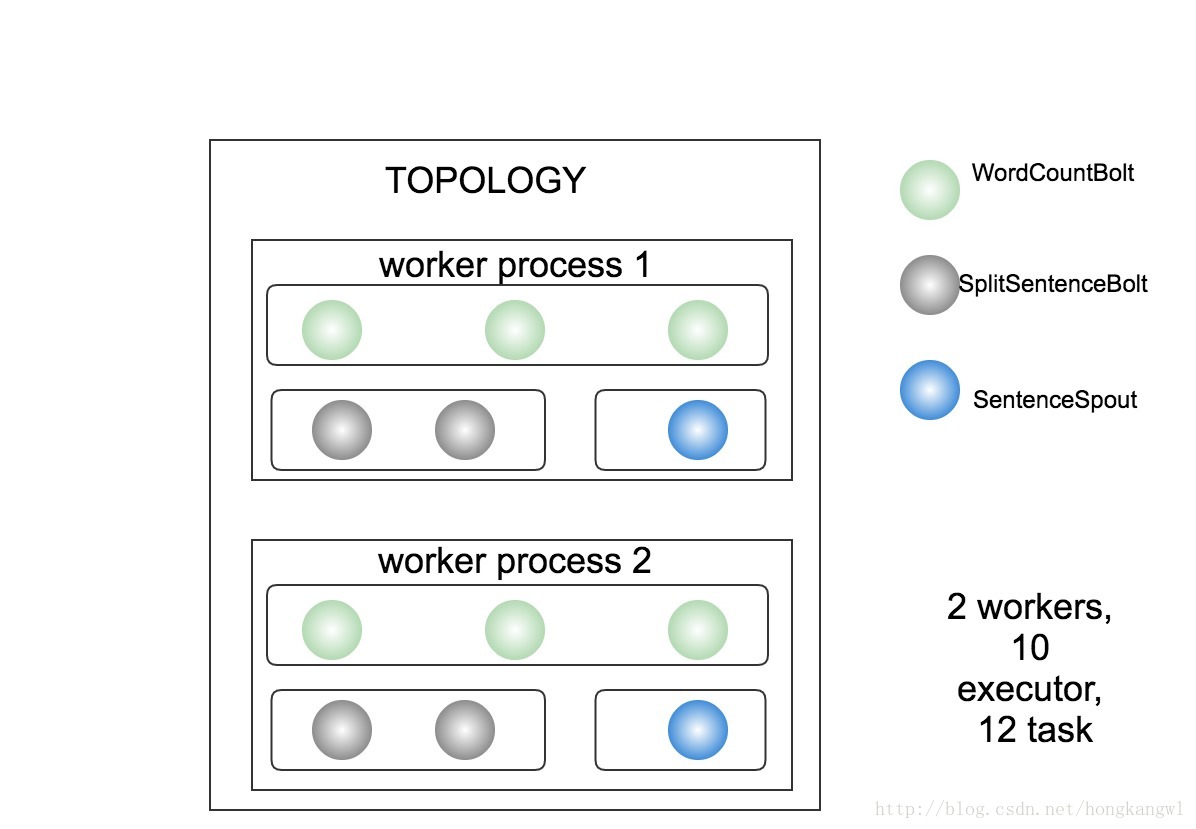
- 其共有2個worker,10個executor,帶圓角的矩形為executor,共12個task(2個spout, 10個bolt)
資料流分組
- Stream Grouping,告訴topology如何在兩個元件之間傳送tuple 。定義一個topology的其中一步是定義每個bolt接收什麼樣的流作為輸入。stream grouping就是用來定義一個stream應該如果分配資料給bolts上面的多個tasks
- Storm裡面有7種類型的stream grouping
Shuffle Grouping
- 隨機分組,隨機派發stream裡面的tuple,保證每個bolt task接收到的tuple數目大致相同。
Fields Grouping
- 按欄位分組,比如,按”user-id”這個欄位來分組,那麼具有同樣”user-id”的 tuple 會被分到相同的Bolt裡的一個task, 而不同的”user-id”則可能會被分配到不同的task。
All Grouping
- 廣播發送,對亍每一個tuple,所有的bolts都會收到
Global Grouping
- 全域性分組,整個stream被分配到storm中的一個bolt的其中一個task。再具體一點就是分配給id值最低的那個task。
None Grouping
- 不分組,這個分組的意思是說stream不關心到底怎樣分組。目前這種分組和Shuffle grouping是一樣的效果, 有一點不同的是storm會把使用none grouping的這個bolt放到這個bolt的訂閱者同一個執行緒裡面去執行(如果可能的話)。
Direct Grouping
- 指向型分組, 這是一種比較特別的分組方法,用這種分組意味著訊息(tuple)的傳送者指定由訊息接收者的哪個task處理這個訊息。只有被宣告為 Direct Stream 的訊息流可以宣告這種分組方法。而且這種訊息tuple必須使用 emitDirect 方法來發射。訊息處理者可以通過 TopologyContext 來獲取處理它的訊息的task的id (OutputCollector.emit方法也會返回task的id)
Local or shuffle grouping
- 本地或隨機分組。如果目標bolt有一個或者多個task與源bolt的task在同一個工作程序中,tuple將會被隨機發送給這些同進程中的tasks。否則,和普通的Shuffle Grouping行為一致。
其他
messageId
- 這裡插入講下messageId,messageId可以標識唯一一條訊息,我們通過messageId可以追蹤訊息的處理以及驗證分組是否符合我們的預期等待。可通過tuple.getMessageId()獲取messageId。
taskId
- storm中的每一個task對會對應唯一一個taskId,其可以通過topologyContext.getThisTaskId()獲取。
演示
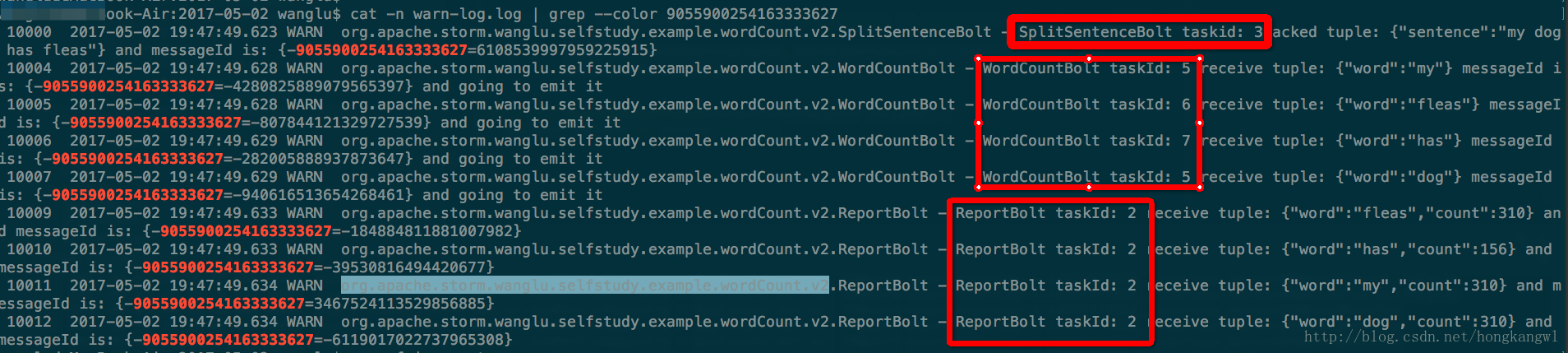
- 我們通過messageId追蹤一條訊息的宣告週期,如下圖所示。
可以清晰的看到一個語句被SplitSentenceBolt接收後並切分成單次傳送給WordCountBolt,WordCountBolt接收到各單次後計算然後傳送給ReportBolt進行列印。
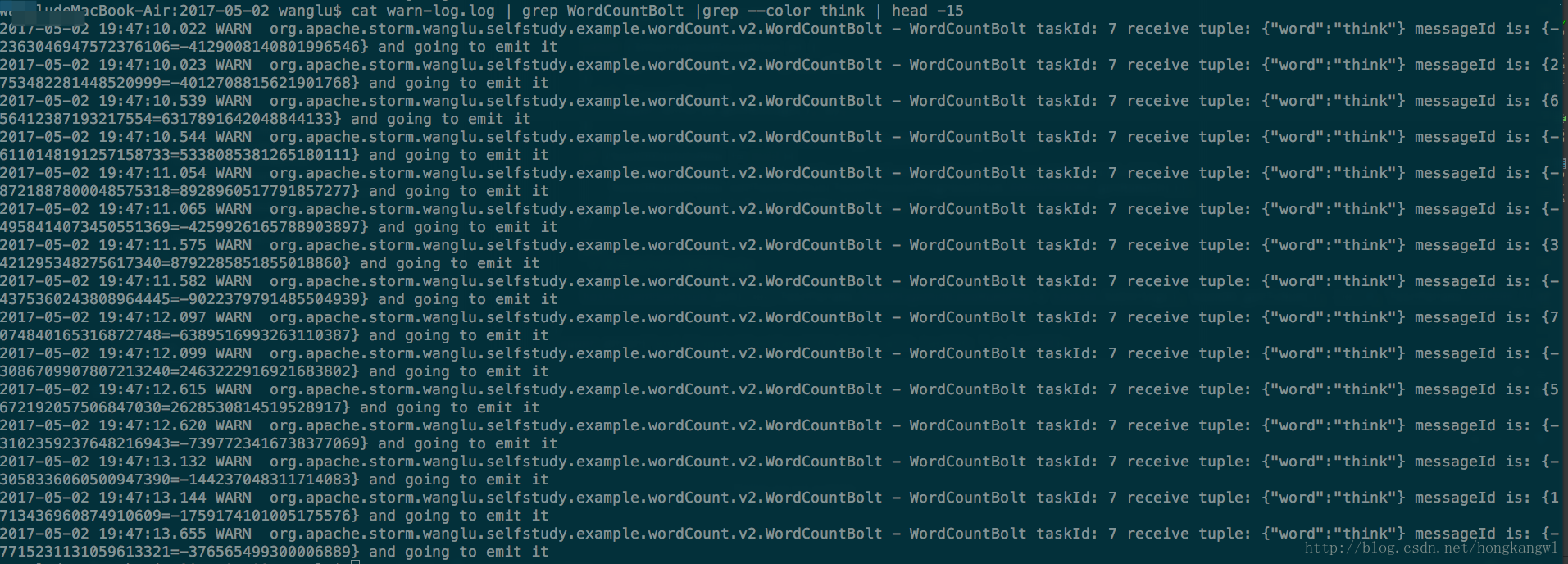
- 由於SplitSentenceBolt split後的欄位是按照fieldgroup後傳遞給WordCountBolt,從下圖中可以看到欄位相同的單次被髮往同一個WordCountBolt。大家也可以換成別的單次grep下看結果。
程式碼
SentenceSpout
public class SentenceSpout extends BaseRichSpout {
private static final Logger logger = LoggerFactory.getLogger(SentenceSpout.class);
private ConcurrentHashMap<UUID, Values> pending;
private SpoutOutputCollector collector;
private String[] sentences = {
"my dog has fleas",
"i like cold beverages",
"the dog ate my homework",
"don't have a cow man",
"i don't think i like fleas"
};
private AtomicInteger index = new AtomicInteger(0);
private Integer taskId = null;
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
public void open(Map config, TopologyContext context,
SpoutOutputCollector collector) {
this.collector = collector;
this.pending = new ConcurrentHashMap<UUID, Values>();
this.taskId = context.getThisTaskId();
}
public void nextTuple() {
Values values = new Values(sentences[index.getAndIncrement()]);
UUID msgId = UUID.randomUUID();
this.pending.put(msgId, values);
this.collector.emit(values, msgId);
if (index.get() >= sentences.length) {
index = new AtomicInteger(0);
}
logger.warn(String.format("SentenceSpout with taskId: %d emit msgId: %s and tuple is: %s",
taskId,
msgId,
JSONObject.toJSON(values)));
Utils.waitForMillis(100);
}
public void ack(Object msgId) {
this.pending.remove(msgId);
logger.warn(String.format("SentenceSpout taskId: %d receive msgId: %s and remove it from the pendingmap",
taskId,
JSONObject.toJSONString(msgId)));
}
public void fail(Object msgId) {
logger.error(String.format("SentenceSpout taskid: %d receive msgId: %s and remove it from the pendingmap",
taskId,
JSONObject.toJSONString(msgId)));
this.collector.emit(this.pending.get(msgId), msgId);
}
}
SplitSentenceBolt
public class SplitSentenceBolt extends BaseRichBolt {
private static final Logger logger = LoggerFactory.getLogger(SplitSentenceBolt.class);
private OutputCollector collector;
private Integer taskId = null;
public void prepare(Map config, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.taskId = context.getThisTaskId();
}
public void execute(Tuple tuple) {
String sentence = tuple.getStringByField("sentence");
String[] words = sentence.split(" ");
for(String word : words){
this.collector.emit(tuple, new Values(word));
}
this.collector.ack(tuple);
logger.warn(String.format("SplitSentenceBolt taskid: %d acked tuple: %s and messageId is: %s",
taskId,
JSONObject.toJSONString(tuple, SerializerFeature.WriteMapNullValue),
tuple.getMessageId()));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
WordCountBolt
public class WordCountBolt extends BaseRichBolt {
private static final Logger logger = LoggerFactory.getLogger(WordCountBolt.class);
private OutputCollector collector;
private HashMap<String, Long> counts = null;
private Integer taskId = null;
public void prepare(Map config, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
this.counts = new HashMap<String, Long>();
this.taskId = context.getThisTaskId();
}
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Long count = this.counts.get(word);
if(count == null){
count = 0L;
}
count++;
this.counts.put(word, count);
this.collector.ack(tuple);
logger.warn(String.format("WordCountBolt taskId: %d receive tuple: %s messageId is: %s and going to emit it",
taskId,
JSONObject.toJSONString(tuple),
tuple.getMessageId()));
this.collector.emit(tuple, new Values(word, count));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
WordCountTopology
public class WordCountTopology {
private static final String SENTENCE_SPOUT_ID = "sentence-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-topology";
public static void main(String[] args) throws Exception {
SentenceSpout spout = new SentenceSpout();
SplitSentenceBolt splitBolt = new SplitSentenceBolt();
WordCountBolt countBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
// SentenceSpout --> SplitSentenceBolt
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2)
.setNumTasks(4)
.shuffleGrouping(SENTENCE_SPOUT_ID);
// SplitSentenceBolt --> WordCountBolt
builder.setBolt(COUNT_BOLT_ID, countBolt, 6)
.fieldsGrouping(SPLIT_BOLT_ID, new Fields("word"));
// WordCountBolt --> ReportBolt
builder.setBolt(REPORT_BOLT_ID, reportBolt)
.globalGrouping(COUNT_BOLT_ID);
Config conf = JStormHelper.getConfig(null);
conf.setNumWorkers(2);
conf.setDebug(true);
boolean isLocal = true;
JStormHelper.runTopology(builder.createTopology(), TOPOLOGY_NAME, conf, 10,
new JStormHelper.CheckAckedFail(conf), isLocal);
}
}