
crash工具原始碼分析
【摘要】
crash工具用於解析kdump檔案,可用於核心crash事後分析。本文的產生是因為需要移植kdump、 crash工具到mips64架構,
本著方便後人的原則,順帶將crash流程分析整理,以備查閱。本文分析物件為截止2014年8月釋出的最新版本crash-7.0.7。
一、編譯框架
為什麼要分析編譯框架?因為標準crash工具不支援交叉編譯。crash只支援兩種執行方法,一種是host和target都是一個cpu架構,另外一種是host和target為不同的cpu架構,但是兩個程式都只能在host上編譯出來,然後執行。說簡單點,打個比方,crash支援:1)x86架構編譯出x86格式的程式,這個程式只能解析x86核心宕機儲存的dump檔案;2)x86架構編譯出x86格式的程式,這個程式只能解析arm核心宕機儲存的dump檔案。cgel的環境決定了我們非交叉編譯不可,所以就得硬著頭皮分析改造 crash的編譯框架。
crash編譯的入口在原始碼根目錄Makefile的all:
all: make_configure
@./configure ${CONF_TARGET_FLAG} -p "RPMPKG=${RPMPKG}" -b
@make --no-print-directory gdb_merge我們這裡提前把crash的大體編譯流程概括下:先執行make_configure將configure.c編譯成configure程式;再執行configure程式,把Makefile裡的一些全域性變數賦值;接著進入gdb_merge流程,該流程會先編譯出gdb庫,再同crash的原始碼編譯出來的物件連結在一起,成為最終的可執行程式。
為了支援交叉編譯,我們主要對Makefile和configure.c分別做了手腳,主體思想就是千方百計修改編譯工具為交叉工具鏈,以及修改gdb的configure引數為交叉編譯引數等。具體的修改可以檢視svn上的程式碼提交記錄。
下面是一條編譯的例子:
make target=mips64 CROSS_COMPILE=mips64_gcc4.1.2_glibc2.5.0/bin/mips64-unknown-linux-gnu-configure.c的流程:
configure.c的main函式裡,會根據target=xxx,來設定引數。
case 't': target_data.target_as_param = optarg; break;
以mips64為例,則target_data.target_as_param= mips64
接著configure解析-b,
case 'b':
build_configure(sp);
break;根據當前編譯工具鏈,設定target架構。
#ifdef __mips64
target_data.target = MIPS64;
#endif,如果是交叉工具鏈編譯,則 target_data.target = MIPS64;
接著set_initial_target並沒有做什麼事。 再後面,初始化target_data.host與target一樣:
target_data.host = target_data.target;
這樣host和target都是mips64了,後面會根據target_data.target_as_param,來修改target
(也就是說,target是編譯命令列指定,host是工具鏈的架構,因為crash一般支援的是在具體
架構下面直接編譯而非交叉編譯,工具鏈的架構也就是執行環境的架構)。
if (target_data.target_as_param) {
if ((target_data.target == X86_64) &&
(name_to_target((char *)target_data.target_as_param) == MIPS64)) {
/*
* Build an MIPS64 crash binary on an X86_64 host.
*/
target_data.target = MIPS64;在set_initial_target函式裡,target_data.initial_gdb_target = UNKNOWN;
由於gdb沒解壓,檔案crash.target不存在,因此不會對target_data.initial_gdb_target進行修正。
接著就是修正target_data的各種值:
strcat(target_data.program, "D");
strcpy(target_data.release, buf); case MIPS64:
target = TARGET_MIPS64;
target_CFLAGS = TARGET_CFLAGS_MIPS64;
gdb_conf_flags = GDB_TARGET_MIPS64_ON_X86_64;
break;makefile_setup(&fp1, &fp2);
接下來,將Makefile裡的各個變數賦值,其中比較重要的是這幾個變數:
TARGET=, TARGET_CFLAGS=, GDB_CONF_FLAGS=, LDFLAGS=
while (fgets(buf, 512, fp1)) {
if (strncmp(buf, "TARGET=", strlen("TARGET=")) == 0)
fprintf(fp2, "%s\n", target);
else if (strncmp(buf, "TARGET_CFLAGS=",
strlen("TARGET_CFLAGS=")) == 0)
fprintf(fp2, "%s%s%s\n", target_CFLAGS,
cflags ? " " : "", cflags ? cflags : "");
else if (strncmp(buf, "GDB_CONF_FLAGS=",
strlen("GDB_CONF_FLAGS=")) == 0)
fprintf(fp2, "%s\n", gdb_conf_flags);
else if (strncmp(buf, "GDB_FILES=",strlen("GDB_FILES=")) == 0)
fprintf(fp2, "%s\n", sp->GDB_FILES);
else if (strncmp(buf, "GDB_OFILES=",strlen("GDB_OFILES=")) == 0)
fprintf(fp2, "%s\n", sp->GDB_OFILES);
else if (strncmp(buf, "GDB_PATCH_FILES=",strlen("GDB_PATCH_FILES=")) == 0)
fprintf(fp2, "%s\n", sp->GDB_PATCH_FILES);
else if (strncmp(buf, "GDB_FLAGS=",strlen("GDB_FLAGS=")) == 0)
fprintf(fp2, "%s\n", sp->GDB_FLAGS);
else if (strncmp(buf, "GPL_FILES=", strlen("GPL_FILES=")) == 0)
fprintf(fp2, "GPL_FILES=%s\n", strcmp(sp->GPL, "GPLv2") == 0 ?
"COPYING" : "COPYING3");
else if (strncmp(buf, "GDB=", strlen("GDB=")) == 0) {
fprintf(fp2, "%s\n", sp->GDB);
sprintf(target_data.gdb_version, "%s", &sp->GDB[4]);
} else if (strncmp(buf, "LDFLAGS=", strlen("LDFLAGS=")) == 0) {
fprintf(fp2, "LDFLAGS=%s\n", ldflags ? ldflags : "");
} else
fprintf(fp2, "%s", buf);
}寫完後,將makefile.new改成makefile。
makefile_create:
if (system("mv Makefile.new Makefile") != 0) gdb_merge: force
make --no-print-directory gdb_unzip;
@echo "${LDFLAGS} -lz -ldl -rdynamic" > ${GDB}/gdb/mergelibs
@echo "../../${PROGRAM} ../../${PROGRAM}lib.a" > ${GDB}/gdb/mergeobj
(cd ${GDB}; ./configure ${GDB_CONF_FLAGS} --with-separate-debug-dir=/usr/lib/debug \
--with-bugurl="" --with-expat=no --with-python=no; \
make --no-print-directory CRASH_TARGET=${TARGET};
echo ${TARGET} > crash.target) ldflags = get_extra_flags("LDFLAGS.extra", NULL);
cflags = get_extra_flags("CFLAGS.extra", NULL);
gdb_conf_flags = get_extra_flags("GDBFLAGS.extra", gdb_conf_flags); ldflags = adjust_ldflags(ldflags);
target_CFLAGS = adjust_target_cflags(target_CFLAGS);
gdb_conf_flags = adjust_gdb_conf_flags(gdb_conf_flags);all:
@: $(MAKE); $(unstage)
@r=`${PWD_COMMAND}`; export r; \
s=`cd $(srcdir); ${PWD_COMMAND}`; export s; \
$(MAKE) $(RECURSE_FLAGS_TO_PASS) all-host all-target \
&& :.PHONY: all-host
all-host: maybe-all-bfd
all-host: maybe-all-opcodes
all-host: maybe-all-bison
all-host: maybe-all-cgen
all-host: maybe-all-dejagnu
all-host: maybe-all-etc
all-host: maybe-all-fastjar
all-host: maybe-all-fixincludes
all-host: maybe-all-flex
all-host: maybe-all-gprof
all-host: maybe-all-intl
all-host: maybe-all-tcl
all-host: maybe-all-itcl
all-host: maybe-all-libdecnumber
all-host: maybe-all-libgui
all-host: maybe-all-libiberty
all-host: maybe-all-libiconv
all-host: maybe-all-m4
all-host: maybe-all-readline
all-host: maybe-all-sid
all-host: maybe-all-sim
all-host: maybe-all-texinfo
all-host: maybe-all-gdb
all-host: maybe-all-expect
all-host: maybe-all-guile
all-host: maybe-all-tk
all-host: maybe-all-libtermcap
all-host: maybe-all-utils
all-host: maybe-all-gnattools
.PHONY: all-target
all-target: maybe-all-target-libmudflap
all-target: maybe-all-target-libssp
all-target: maybe-all-target-newlib
all-target: maybe-all-target-libbacktrace
all-target: maybe-all-target-libquadmath
all-target: maybe-all-target-libgfortran
all-target: maybe-all-target-libobjc
all-target: maybe-all-target-libgo
all-target: maybe-all-target-libtermcap
all-target: maybe-all-target-winsup
all-target: maybe-all-target-libgloss
all-target: maybe-all-target-libffi
all-target: maybe-all-target-libjava
all-target: maybe-all-target-zlib
all-target: maybe-all-target-boehm-gc
all-target: maybe-all-target-rda
all-target: maybe-all-target-libada
all-target: maybe-all-target-libitm
all-target: maybe-all-target-libatomic.PHONY: all-gdb maybe-all-gdb
maybe-all-gdb:
TARGET-gdb=all
maybe-all-gdb: all-gdb
all-gdb: configure-gdb
@: $(MAKE); $(unstage)
@r=`${PWD_COMMAND}`; export r; \
s=`cd $(srcdir); ${PWD_COMMAND}`; export s; \
$(HOST_EXPORTS) \
(cd $(HOST_SUBDIR)/gdb && \
$(MAKE) $(BASE_FLAGS_TO_PASS) $(EXTRA_HOST_FLAGS) $(STAGE1_FLAGS_TO_PASS) \
$(TARGET-gdb))也就是進入gdb子目錄,執行make all。
all: gdb$(EXEEXT)
@$(MAKE) -s $(FLAGS_TO_PASS) DO=all "DODIRS=`echo $(SUBDIRS) | sed 's/testsuite//'`" subdir_do即先執行gdb$(EXEEXT),最後執行subdir_do
先看subdir_do,如果子目錄有testsuite,則進入編譯:
subdir_do: force
@for i in $(DODIRS); do \
case $$i in \
$(REQUIRED_SUBDIRS)) \
if [ ! -f ./$$i/Makefile ] ; then \
echo "Missing $$i/Makefile" >&2 ; \
exit 1 ; \
fi ;; \
esac ; \
if [ -f ./$$i/Makefile ] ; then \
if (cd ./$$i; \
$(MAKE) $(FLAGS_TO_PASS) $(DO)) ; then true ; \
else exit 1 ; fi ; \
else true ; fi ; \
doneCC_LD=$(CC)
gdb$(EXEEXT): gdb.o $(LIBGDB_OBS) $(ADD_DEPS) $(CDEPS) $(TDEPLIBS)
@rm -f gdb$(EXEEXT)
@(cd ../..; make --no-print-directory GDB_FLAGS=-DGDB_7_6 library)//回到crash的makefile
$(CC_LD) $(INTERNAL_LDFLAGS) $(WIN32LDAPP) \
-o $(shell /bin/cat mergeobj) $(LIBGDB_OBS) \
$(TDEPLIBS) $(TUI_LIBRARY) $(CLIBS) $(LOADLIBES) $(shell /bin/cat mergelibs)
all_object_files = gdb.o $(LIBGDB_OBS) gdbtk-main.o \
test-cp-name-parser.o
LIBGDB_OBS的組成
LIBGDB_OBS= $(COMMON_OBS) $(TSOBS) $(ADD_FILES) init.o
COMMON_OBS = $(DEPFILES) $(CONFIG_OBS) $(YYOBJ) \
version.o \
annotate.o \
addrmap.o \
auto-load.o auxv.o \
agent.o \
bfd-target.o \
blockframe.o breakpoint.o break-catch-sig.o \
findvar.o regcache.o cleanups.o \
charset.o continuations.o corelow.o disasm.o dummy-frame.o dfp.o \
source.o value.o eval.o valops.o valarith.o valprint.o printcmd.o \
block.o symtab.o psymtab.o symfile.o symmisc.o linespec.o dictionary.o \
infcall.o \
infcmd.o infrun.o \再就是$(ADD_DEPS) $(CDEPS) $(TDEPLIBS),
這些gdb的相關依賴執行完畢後,會繼續回去執行crash的library。
library: make_build_data ${OBJECT_FILES}
ar -rs ${PROGRAM}lib.a ${OBJECT_FILES}最後gdb執行完library目標後,會生成crash,這就是:
$(CC_LD) $(INTERNAL_LDFLAGS) $(WIN32LDAPP) \
-o $(shell /bin/cat mergeobj) $(LIBGDB_OBS) \
$(TDEPLIBS) $(TUI_LIBRARY) $(CLIBS) $(LOADLIBES) $(shell /bin/cat mergelibs)之前在gdb_merger依賴的前面,有兩句:
@echo "${LDFLAGS} -lz -ldl -rdynamic" > ${GDB}/gdb/mergelibs
@echo "../../${PROGRAM} ../../${PROGRAM}lib.a" > ${GDB}/gdb/mergeobj把-lz -ldl -rdynamic寫入mergelibs
這樣,上句就變成:
cc -o ../../crash ../../crashlib.a $(LIBGDB_OBS) -lz -ldl -rdynamic二、程式碼流程
2.1vmcore_list--訪問宕機核心的關鍵結構
crash的工作原理,是解析捕獲核心/proc/vmcore匯出的dump檔案(這裡先不考慮makedumpfile的壓縮)。因此,需要分析捕獲核心的/proc/vmcore的工作原理。作為橋樑,/proc/vmcore就是通過解析捕獲核心裡攜帶的宕機核心記憶體位置資訊,來訪問宕機核心的記憶體資料。
下面,先以/proc/vmcore的讀取流程來看,如何獲取宕機核心的資料。
/proc/vmcore的讀取是靠read_vmcore函式,該函式入參offset,讀指定長度的資料:
start = map_offset_to_paddr(*fpos, &vmcore_list, &curr_m);
read_from_oldmem(buffer, tsz, &start, 1);其中,start變數可以看出,是實體地址。 也就是說,map_offset_to_paddr將偏移轉換成了宕機核心裡的實體地址。
再深入map_offset_to_paddr就可以知道,關鍵轉換就是:遍歷vmcore_list裡的vmcore成員,
找到包含一個vmcore成員,滿足vmcore.offset<offset<(vmcore.offset+size),
再返回(vmcore.paddr+offset-vmcore.offset)得到實體地址。
最後呼叫read_from_oldmem從實體地址讀出資料。也即,捕獲核心的vmcore.paddr和vmcore.offset有一一對應關係,可以互相反推。
因此,我們需要看,vmcore.offset和vmcore.paddr是怎麼賦值的?
2.2 vmcore_list的生成
vmcore_list的生成,是捕獲核心啟動時,通過:
parse_crash_elf_headers->parse_crash_elf64_headers來生成的:
static int __init parse_crash_elf64_headers(void)
{
/* 將PT_NOTE段資訊加入vmcore_list */
rc = merge_note_headers_elf64(elfcorebuf, &elfcorebuf_sz, &vmcore_list);
/* 將PT_LOAD段資訊加入vmcore_list */
rc = process_ptload_program_headers_elf64(elfcorebuf, elfcorebuf_sz,
&vmcore_list);
/*調整vmcore_list的每個成員的偏移*/
set_vmcore_list_offsets_elf64(elfcorebuf, &vmcore_list);
}可以看出,先根據宕機核心傳遞過來的elfcore地址,進行elf解析,將PT_NOTE和PT_LOAD
段的頭資訊,以struct vmcore的形式加入到vmcore_list連結串列。 而vmcore資訊代表了宕機核心的記憶體佈局,該結構有三個重要的成員,paddr,size,以及offset。因為使用者態想要達到的目標是,根據/proc/vmcore匯出的檔案,只要給出一個檔案內的offset,就可以得到該offset對應宕機核心的哪個實體地址paddr,size則說明,每個vmcore代表了一段宕機核心的記憶體區間。
再回到前面的parse_crash_elf64_headers函式,逐句分析。merge_note_headers_elf64:處理PT_NOTE段。嘗試把所有note段合併成一個段(每個cpu有一個note屬性的programmhead,這些programm head挨個存放,每個programm指向連續的多個note。其實連續的只有兩個note,第一個note是實際負載,由crash_save_cpu儲存的暫存器現場等,第二個note是空的,表示結束)。
static int __init merge_note_headers_elf64(char *elfptr, size_t *elfsz,
struct list_head *vc_list)
{
int i, nr_ptnote=0;
ehdr_ptr = (Elf64_Ehdr *)elfptr;
phdr_ptr = (Elf64_Phdr*)(elfptr + sizeof(Elf64_Ehdr));
//遍歷所有的programm header,找到PT_NOTE programe header
for (i = 0; i < ehdr_ptr->e_phnum; i++, phdr_ptr++) {
if (phdr_ptr->p_type != PT_NOTE)
continue;
//遍歷該programm header裡所有連續存放的note_load負載
//每個note_load段負載的組成為,一個Elf64_Nhdr,後面接實際note資料
//有多個連續的note_load組成一個programm header
for (j = 0; j < max_sz; j += sz) {
if (nhdr_ptr->n_namesz == 0)
break;
sz = sizeof(Elf64_Nhdr) +
((nhdr_ptr->n_namesz + 3) & ~3) +
((nhdr_ptr->n_descsz + 3) & ~3);
real_sz += sz;
nhdr_ptr = (Elf64_Nhdr*)((char*)nhdr_ptr + sz);
}
new->paddr = phdr_ptr->p_offset;
new->size = real_sz;
//每找到一個pt_note屬性的programme header,
//就把這個programm header指向的連續note_load段用一個vmcore表示,
//並新增到vmcore連結串列中
//size為該programe header裡所有note的大小
list_add_tail(&new->list, vc_list);
phdr_sz += real_sz;
}
//新建立一個PT_NOTE屬性的programm header,將所有的NOTE屬性programm header都歸一到此
phdr.p_type = PT_NOTE;
phdr.p_flags = 0;
//第一個核心最先傳遞過來的elf資訊,結構如下:
//[elf_header][programm_head_note_cpu0]...[programm_head_note_cpum]
//[programm_head_note_load0]..[programm_head_note_loadn]
//(可能還有其他段)[note_0_a]...[note_0_x](可能還有其他段)[note_m_a]...[note_m_x][load_0] ... [load_n]
//note段歸併後,只剩一個programm_head_note_all,即刪除了從programm_head_note_cpu0 //到programm_head_note_cpux
//因此第一個note段note_0_a的偏移要減少nr_ptnote-1個program head長度
note_off = sizeof(Elf64_Ehdr) +
(ehdr_ptr->e_phnum - nr_ptnote +1) * sizeof(Elf64_Phdr);
//原elf.p_offset段的值是實體地址,這裡改成了檔案內偏移
phdr.p_offset = note_off; //notice: 1
phdr.p_vaddr = phdr.p_paddr = 0;
//更新大小
phdr.p_filesz = phdr.p_memsz = phdr_sz;
phdr.p_align = 0;
//將第一個programm_head_note_cpu0替換為新note段的值
/* Add merged PT_NOTE program header*/
tmp = elfptr + sizeof(Elf64_Ehdr);
memcpy(tmp, &phdr, sizeof(phdr));
tmp += sizeof(phdr);
//整體前移nr_ptnote - 1個programm_head
/* Remove unwanted PT_NOTE program headers. */
i = (nr_ptnote - 1) * sizeof(Elf64_Phdr);
*elfsz = *elfsz - i;
//要往前挪動的長度是原長度減去一個elf head和一個note屬性的programm_head長度。
memmove(tmp, tmp+i, ((*elfsz)-sizeof(Elf64_Ehdr)-sizeof(Elf64_Phdr)));
/* Modify e_phnum to reflect merged headers. */
ehdr_ptr->e_phnum = ehdr_ptr->e_phnum - nr_ptnote + 1;
}結論:merge_note_headers_elf64執行完畢,elf段的note段被合併為一個,並且更新note head的p_offset欄位為合併後的note段檔案偏移。
為什麼要合併note段呢?因為之前新增的vmcore成員,offset都是挨著的,
也就是說,當read /proc/vmcore>dump之後,之前的note段在dump檔案裡都會挨著,
那麼就需要一個新的note段來指示,這就是新note段的來歷。
process_ptload_program_headers_elf64://LOAD段的起始偏移
vmcore_off = sizeof(Elf64_Ehdr) +
(ehdr_ptr->e_phnum) * sizeof(Elf64_Phdr) +
phdr_ptr->p_memsz; /* Note sections */
for (i = 0; i < ehdr_ptr->e_phnum; i++, phdr_ptr++) {
if (phdr_ptr->p_type != PT_LOAD)
continue;
new->paddr = phdr_ptr->p_offset;
new->size = phdr_ptr->p_memsz; //PT_LOAD
list_add_tail(&new->list, vc_list);
//最重要的是,這裡會把elf各段的p_offset欄位更新為檔案內偏移
/* Update the program header offset. */
phdr_ptr->p_offset = vmcore_off;
vmcore_off = vmcore_off + phdr_ptr->p_memsz;
}然後elf.p_offset被改成了檔案偏移。
set_vmcore_list_offsets_elf64:設定vmcore.offset的賦值,也就是各個段在檔案中的偏移。這個是人為來設定的值。根據每個段對應區間佔用的記憶體(注意,不是段頭大小)來算的:
/* Skip Elf header and program headers. */
vmcore_off = sizeof(Elf64_Ehdr) +
(ehdr_ptr->e_phnum) * sizeof(Elf64_Phdr);
list_for_each_entry(m, vc_list, list) {
m->offset = vmcore_off;
vmcore_off += m->size;
}從上面程式碼可以看出,誰先加入vmcore連結串列,誰的offset就在前面,我們可以從前幾步看出,先加的是每cpunote段,再是各個load段。
為便於理解,再補充一下宕機核心傳遞過來的elf資訊。elf資訊是vmcore_list的核心,正確的理解kdump elf格式是理解/proc/vmcore的關鍵。
網上有一篇文章對使用者態coredump的格式解析,寫的很好,coredump格式與kdump格式差不多,這裡將其部分分析摘抄如下,以備參考:
Core檔案的整體佈局如下圖所示,它與普通ELF檔案的差別是多了一個特定的PT_NOTE型別的段,用於存放執行緒資訊和暫存器資訊。
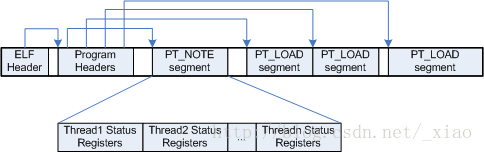
下圖是是一個在mips平臺上生成的Coredump檔案的頭部的十六進位制資料。

檔案開始是一個ELF Header,該頭的結構定義為:
typedef struct elf32_hdr{
unsigned char e_ident[EI_NIDENT]; // 16位元組標識
Elf32_Half e_type;
Elf32_Half e_machine;
Elf32_Word e_version;
Elf32_Addr e_entry;
Elf32_Off e_phoff; // Program Headers的檔案偏移地址
Elf32_Off e_shoff;
Elf32_Word e_flags;
Elf32_Half e_ehsize; // ELF Header頭結構的大小
Elf32_Half e_phentsize; // 每個Program Header資訊描述佔用的大小
Elf32_Half e_phnum; // Program Header的數量
Elf32_Half e_shentsize;
Elf32_Half e_shnum;
Elf32_Half e_shstrndx;
} Elf32_Ehdr;
e_type為0x04(ET_CORE),表示這是一個core檔案;e_phoff為0x0034,
表示Program Headers資訊從檔案的0x34地址開始;
e_ehsize為0x34,表示此ELF Header檔案頭佔用的位元組為0x34;
e_phentsize為0x20(32位元組),表示每個Program Header佔用的大小為32位元組;
e_phnum為0x23,表示這個core檔案共含有35個segment段;
根據e_phoff資訊,Program Headers從0x34位元組開始, 即緊跟在ELF Header之後開始。
再來分析Program Headers資訊,根據ELF Header,每個Program Header佔據的位元組數為32位元組,說明這是一個32位的Elf32_Phdr
(對應的還有64位的Elf64_Phdr,其size要大一些),Elf32_Phdr的定義如下:
typedef struct elf32_phdr{
Elf32_Word p_type; // segment的型別
Elf32_Off p_offset; // segment資料在檔案中的偏移
Elf32_Addr p_vaddr; // segment載入到記憶體中的虛擬地址
Elf32_Addr p_paddr;
Elf32_Word p_filesz; // segment資料在檔案中的資料大小
Elf32_Word p_memsz; // segment資料在記憶體中佔據的大小
Elf32_Word p_flags; // segment的屬性標誌
Elf32_Word p_align;
} Elf32_Phdr;
第1個Segment的p_type為0x04(PT_NOTE),表示這是一個描述note資訊的段;
p_offset為0x494,表示note資訊段從檔案的0x494位元組開始;
p_filesz為0x358,表示note資訊共有856位元組。
由於note資訊是輔助資訊段,在原程式中並不存在於記憶體中,所以其p_vaddr,p_memsz,p_flags等均為0。
緊接著的是第二個Program Header資訊(從地址0x34+0x20=0x54開始):

第2個Segment的p_type為0x01(PT_LOAD),這是一個可載入的段;
p_offset為0x1000,表示該段從檔案的0x1000位元組開始;p_vaddr為0x400000,
表示該段在原程式的記憶體中的虛擬地址為0x400000
(對mips而言,此地址是主程式的載入地址);
p_filesz為0,表示該段在檔案中的大小為0,
如前所述,由於該段是一個程式碼段,所以Core檔案並沒有儲存其內容,因此該段在Core檔案中的資料長度為0,
除錯時需要原程式的ELF檔載入到0x400000地址才能分析此程式;
p_memsz為0x10000,表示該段在原記憶體中佔據4096的大小(即該段佔據0x400000~0x40FFFF的地址空間);
p_flags為0x05,即PF_R | PF_X,表示該段是一個只讀可執行的程式碼段。
2.3 kdump的elf格式
首先我們要搞清楚一個問題,宕機核心傳遞給捕獲核心的elf頭是誰提供的?
起初,我懷疑是直接根據宕機核心vmlinux的elf頭資訊得到的。下面是一個vmlinux的elf資訊:
[[email protected] kernel_imx]# readelf -l vmlinux
Elf file type is EXEC (Executable file)
Entry point 0x1000000
There are 5 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
LOAD 0x0000000000200000 0xffffffff81000000 0x0000000001000000
0x00000000008a7000 0x00000000008a7000 R E 200000
LOAD 0x0000000000c00000 0xffffffff81a00000 0x0000000001a00000
0x0000000000130000 0x0000000000130000 RW 200000
LOAD 0x0000000000e00000 0x0000000000000000 0x0000000001b30000
0x0000000000013a40 0x0000000000013a40 RW 200000
LOAD 0x0000000000f44000 0xffffffff81b44000 0x0000000001b44000
0x00000000001ba000 0x000000000043b000 RWE 200000
NOTE 0x0000000000785758 0xffffffff81585758 0x0000000001585758
0x0000000000000024 0x0000000000000024 4其中offset的值,很明顯不是對應的記憶體實體地址。那這到底是怎麼回事?
很多核心映象都是被strip掉elf頭資訊後再載入的,所以捕獲核心得到的elf頭資訊,
一定還有其他別的什麼來歷。答案是kexec-tool使用者態工具生成的。這個是關鍵!
生成elf資訊的程式碼在kexec/crashdump-elf.c檔案的FUNC函式。
我們看看這個起著聯絡第一個核心和第二個核心紐帶的函式,是如何生成elf資訊的,將該函式裁剪如下:
nr_cpus = sysconf(_SC_NPROCESSORS_CONF);
sz = sizeof(EHDR) + (nr_cpus + has_vmcoreinfo) * sizeof(PHDR) +
ranges * sizeof(PHDR);
bufp = xmalloc(sz);
memset(bufp, 0, sz);
/* Setup ELF Header*/
elf = (EHDR *) bufp;
先來構造PT_NOTE段,一個cpu的資訊就是一個note段
/* PT_NOTE program headers. One per cpu */
for (i = 0; i < nr_cpus; i++) {
///sys/devices/system/cpu/cpu%d/crash_notes
get_note_info(i, ¬es_addr, ¬es_len);
phdr = (PHDR *) bufp;
bufp += sizeof(PHDR);
phdr->p_type = PT_NOTE;
phdr->p_offset = phdr->p_paddr = notes_addr;
phdr->p_filesz = phdr->p_memsz = notes_len;
}上面的程式碼裡詳細解釋了elf檔案的生成過程。可以看出,elf檔案主要由PT_NOTE和PT_LOAD段組成。
先來看PT_NOTE段的作用。捕獲核心如何獲取宕機核心宕機時的暫存器現場?答案是,在核心crash dump時,會把宕機資訊存放到PT_NOTE段裡。
這樣捕獲核心起來後,解析PT_NOTE段,就能根據實體地址找到宕機核心存放宕機現場的暫存器了。
kexec tool在上面的程式碼裡相當於預留了一個elf段,裡面填的是宕機核心存放現場資料crash_notes的地址
(用sys/devices/system/cpu/cpu%d/crash_notes來儲存),以及crash_notes的長度。
那麼宕機核心會往crash_data填寫什麼值呢?程式碼在crash_save_cpu:
void crash_save_cpu(struct pt_regs *regs, int cpu)
{
struct elf_prstatus prstatus;
u32 *buf;
buf = (u32*)per_cpu_ptr(crash_notes, cpu);
//*(struct pt_regs *)&prstatus.pr_reg= *regs;
elf_core_copy_kernel_regs(&prstatus.pr_reg, regs);
//memcpy(buf,&prstatus,sizeof(prstatus));,拷貝到crash_notes
//buf+=sizeof(prstatus);後移指標
buf = append_elf_note(buf, KEXEC_CORE_NOTE_NAME, NT_PRSTATUS,
&prstatus, sizeof(prstatus));
//新增一個空長度的note(name長度為0,n_descsz長度為0,n_type為0),作為結束標誌
final_note(buf);
}這一步執行完後,elf頭資訊裡就加了PT_NOTE段的內容。
再來看PT_LOAD段的生成。
程式碼資料段:
if (elf_info->kern_size && !xen_present()) {
phdr = (PHDR *) bufp;
bufp += sizeof(PHDR);
phdr->p_type = PT_LOAD;
phdr->p_flags = PF_R|PF_W|PF_X;
phdr->p_offset = phdr->p_paddr = elf_info->kern_paddr_start;
phdr->p_vaddr = elf_info->kern_vaddr_start;
phdr->p_filesz = phdr->p_memsz = elf_info->kern_size;
phdr->p_align = 0;
(elf->e_phnum)++;
}接下來就是重要的各個記憶體段了,這主要是靠kexec-tool解析/proc/iomem裡的System RAM:
for (i = 0; i < ranges; i++, range++) {
unsigned long long mstart, mend;
if (range->type != RANGE_RAM)
continue;
mstart = range->start;
mend = range->end;
if (!mstart && !mend)
continue;
phdr = (PHDR *) bufp;
bufp += sizeof(PHDR);
phdr->p_type = PT_LOAD;
phdr->p_offset = mstart;
phdr->p_paddr = mstart;
phdr->p_vaddr = phys_to_virt(elf_info, mstart);
if (mstart == info->backup_src_start
&& (mend - mstart + 1) == info->backup_src_size)
phdr->p_offset = info->backup_start;
、 phdr->p_filesz = phdr->p_memsz = mend - mstart + 1;
(elf->e_phnum)++;
}最後得到的elf的頭如下(注意,這是elf頭,還不包括真正的note段資料、load段資料。
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
NOTE 0x0000000000000190 0x0000000000000000 0x0000000000000000
0x0000000000000d14 0x0000000000000d14 0
LOAD 0x0000000000000ea4 0xffffffffc0100000 0x0000000000100000
0x000000000452b1ef 0x000000000452b1ef RWE 0
LOAD 0x000000000452c093 0xc000000000000000 0x0000000000000000
0x0000000000100000 0x0000000000100000 RWE 0
LOAD 0x000000000462c093 0xc000000000100000 0x0000000000100000
0x0000000007f00000 0x0000000007f00000 RWE 0
LOAD 0x000000000c52c093 0xc00000000c000000 0x000000000c000000
0x0000000003effe00 0x0000000003effe00 RWE 0
LOAD 0x000000001042be93 0xc000000020000000 0x0000000020000000
0x000000009ffffe00 0x000000009ffffe00 RWE 0總結:
1)宕機傳遞給捕獲核心的elf資訊,包含note段、load段,每個段是一個elf結構,其p_offset為實體地址,p_memsz為該段大小,p_paddr為實體地址;
2)在捕獲核心初始化執行vmcore_init->parse_crash_elf_headers之後,捕獲核心的記憶體裡,
儲存了一個vmcore_list連結串列,每個連結串列成員是vmcore。vmcore根據第1步的結果,儲存了偏移地址對應實體地址的關係。
也就是說,給出偏移,可以得到實體地址。並且,第一個核心傳遞給第二個核心的elf load屬性段,
其p_offset被改為了本段在檔案內的偏移,但p_paddr保持不變(note段沒有必要保留p_addr);
3)cat/proc/vmcore將資料匯出到一個二進位制檔案裡,包括第一個核心傳遞的elf頭資訊也被匯出;
4)crash解析二進位制檔案,根據elf資訊裡的偏移p_offset和實體地址p_paddr的關係,
根據核心虛擬地址得到實體地址,再得對應檔案偏移。
再根據偏移讀出檔案資料,也就是原宕機核心的實體記憶體資料。
2.4 crash關鍵流程分析
好,走到這裡,才算是真正進入crash原始碼分析了。讀者是不是已經沒耐心了?
請再堅持一會,現在開啟crash-7.0.7的原始碼工程。
本節,我們主要考察crash的兩個重要介面的實現,第一個是readmem函式,
第二個是bt回溯。
2.4.1 readmem
先來看readmem的原型:
int
readmem(ulonglong addr, int memtype, void *buffer, long size,
char *type, ulong error_handle)指定addr是虛擬地址還是實體地址。例如:
buf =(char*)malloc(1024);
readmem(C000000018000000,buf,1024,KVADDR,NULL)這個是如何做到的,在2.1節我們已經簡要介紹過。下面詳細分析。
這個讀取的流程,正好和vmcore檔案被匯出的過程互逆。
現在我們只有一個vmcore的匯出檔案,已知的是使用者給的核心態虛擬地址,需要看這個核心虛擬地址,對應vmcore裡的哪個位置的內容。
首先,核心態虛擬地址,可以通過kvtop得到其在第一個核心裡的實體地址;接著,實體地址
和檔案的偏移,可以在vmcore_list裡找到對應關係。 由於vmcore_list是核心裡才能訪問的,那麼
crash這個使用者態工具,有沒有儲存一份vmcore_list的拷貝呢?
crash裡對應的這個結構,叫做vmcore_data。我們來看看這個vmcore_data是如何生成的。
首先,cat /proc/vmcore的時候,呼叫的是read_vmcore,該函式的最開頭,如果發現要讀的檔案偏移,
小於一個elf頭的長度,則會把頭一個核心提供的elf資訊,copy_to_user返回給使用者。程式碼註釋寫的很清楚:
/* Read ELF core header */
if (*fpos < elfcorebuf_sz) {
tsz = elfcorebuf_sz - *fpos;
if (buflen < tsz)
tsz = buflen;
if (copy_to_user(buffer, elfcorebuf + *fpos, tsz))
return -EFAULT;
buflen -= tsz;
*fpos += tsz;
buffer += tsz;
acc += tsz;
}這個和核心裡生成vmcore_list的過程基本一致。
vmcore_data初始化好後,crash就可以根據vmcore_data讀一個核心態虛擬地址內容。
函式流程簡述如下:
readmem(sp->value, KVADDR, local,
size, symbol, FAULT_ON_ERROR);
kvtop(CURRENT_CONTEXT(), addr, &paddr, 0);
READMEM(fd, bufptr, cnt,
(memtype == PHYSADDR) || (memtype == XENMACHADDR) ? 0 : addr, paddr)
#define READMEM pc->readmem
read_kdump->read_netdump:
for (i = offset = 0; i < nd->num_pt_load_segments; i++) {
pls = &nd->pt_load_segments[i];
if ((paddr >= pls->phys_start) &&
(paddr < pls->phys_end)) {
offset = (off_t)(paddr - pls->phys_start) +
pls->file_offset;
break;
}
}
lseek(nd->ndfd, offset, SEEK_SET)
read(nd->ndfd, bufptr, cnt);phys_start對應關係,把實體地址轉換為檔案偏移。
那vmcore_data是如何生成的呢?我們在程式碼裡搜尋vmcore_data,找到其生成的地方,is_netdump函式。
is_netdump就是將dump檔案的elf資訊歸納為vmcore_data的函式:
/*
* Determine whether a file is a netdump/diskdump/kdump creation,
* and if TRUE, initialize the vmcore_data structure.
*/
int
is_netdump(char *file, ulong source_query)
{
fd = open(file, O_RDWR);
size = MIN_NETDUMP_ELF_HEADER_SIZE;
read(fd, eheader, size) ; //讀取elf頭
elf64 = (Elf64_Ehdr *)&eheader[0];//64位的elf頭
size = (size_t)load64->p_offset;
tmp_elf_header = (char *)malloc(size)) ;
lseek(fd, 0, SEEK_SET) ;
read(fd, tmp_elf_header, size);
nd->ndfd = fd;
nd->elf_header = tmp_elf_header;
nd->flags = tmp_flags;
nd->flags |= source_query;
nd->header_size = load64->p_offset;
nd->elf64 = (Elf64_Ehdr *)&nd->elf_header[0];
nd->num_pt_load_segments = nd->elf64->e_phnum - 1;
//關鍵的段資訊,包含offset與physical address的對映關係
nd->pt_load_segments = (struct pt_load_segment *)
malloc(sizeof(struct pt_load_segment) *
nd->num_pt_load_segments)) ;
////越過elf頭,就是note head段
nd->notes64 = (Elf64_Phdr *)
&nd->elf_header[sizeof(Elf64_Ehdr)];
//越過elf頭,越過note head段(經第二個核心啟動時歸併,只剩一個),跳到load head段,
//load64指標型別: Elf64_Phdr *load64;
nd->load64 = (Elf64_Phdr *)
&nd->elf_header[sizeof(Elf64_Ehdr)+sizeof(Elf64_Phdr)];
nd->page_size = (uint)nd->load64->p_align;
dump_Elf64_Ehdr(nd->elf64);
dump_Elf64_Phdr(nd->notes64, ELFREAD);
for (i = 0; i < nd->num_pt_load_segments; i++)
//解析每個段的資訊
dump_Elf64_Phdr(nd->load64 + i, ELFSTORE+i);
offset64 = nd->notes64->p_offset;//在kexec裡這個值曾經是 crash_note的實體地址,
//經第二個核心一折騰,就改成了dump檔案的偏移
for (tot = 0; tot < nd->notes64->p_filesz; tot += len) {
//直接跳到note段,依次解析之後每個欄位nhdr的內容
if (!(len = dump_Elf64_Nhdr(offset64, ELFSTORE)))
break;
offset64 += len;
}
}static void
dump_Elf64_Phdr(Elf64_Phdr *prog, int store_pt_load_data)
{
pls = &nd->pt_load_segments[store_pt_load_data-1];
pls->file_offset = prog->p_offset;
pls->phys_start = prog->p_paddr;
}
static size_t
dump_Elf64_Nhdr(Elf64_Off offset, int store)
{
note = (Elf64_Nhdr *)((char *)nd->elf64 + offset);
switch (note->n_type)
{
case NT_PRSTATUS:
netdump_print("(NT_PRSTATUS)\n");
if (store) {
if (!nd->nt_prstatus)
nd->nt_prstatus = (void *)note;
for (i = 0; i < NR_CPUS; i++) {
if (!nd->nt_prstatus_percpu[i]) {
nd->nt_prstatus_percpu[i] = (void *)note;
nd->num_prstatus_notes++;
break;
}
}
}
//將本次解析到的note段長度返回(包含一個nhdr頭和開頭的名字長度加實際資料負載即elf_prstatus長度)
len = sizeof(Elf64_Nhdr);
len = roundup(len + note->n_namesz, 4);
len = roundup(len + note->n_descsz, 4);
return len;
}2.4.2 bt回溯
在crash介面敲bt的時候,發生了什麼。void
cmd_bt(void)
{
//執行bt不帶任何引數,就走藍字部分
if (!args[optind]) {
if (CURRENT_PID() && (bt->flags & BT_THREAD_GROUP)) {
tgid = task_tgid(CURRENT_TASK());
DO_THREAD_GROUP_BACKTRACE();
} else {
tc = CURRENT_CONTEXT(); //根據tt->current獲取程序描述符
DO_TASK_BACKTRACE();
}
return;
}
}
#define CURRENT_CONTEXT() (tt->current)
#define DO_TASK_BACKTRACE() \
{ \
BT_SETUP(tc); \
if (!BT_REFERENCE_CHECK(bt)) \
print_task_header(fp, tc, subsequent++); \
back_trace(bt); \
}
#define BT_SETUP(TC) \
clone_bt_info(&bt_setup, bt, (TC));
void
clone_bt_info(struct bt_info *orig, struct bt_info *new,
struct task_context *tc)
{
BCOPY(orig, new, sizeof(*new));
new->stackbuf = NULL;
new->tc = tc;
new->task = tc->task;
new->stackbase = GET_STACKBASE(tc->task);
new->stacktop = GET_STACKTOP(tc->task);
}
上面的clone_bt_info準備好待回溯的棧資訊後,就呼叫back_trace準備回溯了。
在分析crash的回溯演算法之前,先看回溯的堆疊現場是如何準備出來的。
首先,back_trace,需要根據宕機核心發生異常時的那個程序,來獲取當時的核心棧指標。
核心異常程序,就是由巨集CURRENT_CONTEXT來指示,即,tt->current決定了是在哪個cpu回溯,那麼這個tt是哪裡賦值的呢?
答案是在crash初始化的task_init函式。tt是一個task 連結串列, 由task_init初始化。struct task_table task_table = { 0 };
struct task_table *tt = &task_table;
void
task_init(void)
{
please_wait("determining panic task");
set_context(get_panic_context(), NO_PID);
}
//在get_panic_context中獲取宕機的那個執行緒
//接著以此執行緒地址為key,搜尋tc(程序連結串列),
//找到對應的tc,並返回。
//所以重點在怎麼找到宕機的執行緒get_panic_context()
int
set_context(ulong task, ulong pid)
{
int i;
struct task_context *tc;
int found;
tc = FIRST_CONTEXT();
for (i = 0, found = FALSE; i < RUNNING_TASKS(); i++, tc++) {
if (task && (tc->task == task)) {
found = TRUE;
break;
} else if (pid == tc->pid) {
found = TRUE;
break;
}
}
if (found) {
CURRENT_CONTEXT() = tc;
return TRUE;
} else {
return FALSE;
}
static ulong
get_panic_context(void)
{
//首先非R狀態的不關心,因為非R狀態的肯定不是發生非法地址訪問的程序
//對所有的當前執行程序檢查一下,如果是執行狀態,但又不在hash_pid,則告警。
for (i = 0; i < NR_CPUS; i++) {
if (!(task = tt->active_set[i]))
continue;
if (!task_exists(task)) {
error(WARNING);
}
if ((tc = panic_search())) {
tt->panic_processor = tc->processor;
return(tt->panic_task = tc->task);
}
}我們先來想一下,如果是你來寫這個函式,找出上個核心發生宕機的
那個程序,你會怎麼寫?
一種方案是,首先根據dump檔案的特殊性,來查詢crash cpu,
再根據crash cpu獲取執行的程序tt->active_set[crash cpu];
還有就是,找到crash cpu後,取得nhdr結構,得到宕機時的sp,這個sp
就是核心棧,核心棧與thread_info是重合的,因此可以得到thread_info結構,
再得到task struct結構。
ulong
get_netdump_panic_task(void)
{
int crashing_cpu=-1;
if (kernel_symbol_exists("crashing_cpu")) {
get_symbol_data("crashing_cpu", sizeof(int), &i);
crashing_cpu = i;
}
note64 = (Elf64_Nhdr *)
nd->nt_prstatus_percpu[crashing_cpu];
//ppc64走方案2
if (nd->elf64->e_machine == EM_PPC64) {
esp = *(ulong *)((char *)user_regs + 8);
if (IS_KVADDR(esp)) {
task = stkptr_to_task(esp);
for (i = 0; task && (i < NR_CPUS); i++) {
if (task == tt->active_set[i])
return task;
}
}
//x86走方案1
if (nd->elf64->e_machine == EM_X86_64) {
if ((crashing_cpu != -1) && (crashing_cpu <= kt->cpus))
return (tt->active_set[crashing_cpu]);
}
//mips64走方案1
if (nd->elf64->e_machine == EM_MIPS) {
if ((crashing_cpu != -1) && (crashing_cpu <= kt->cpus))
return (tt->active_set[crashing_cpu]);
}
}得到異常程序的棧後,回溯的核心是unwind_stack,這個是從核心的對應函式抄過來的。
不過,由於核心的unwind_stack可以直接訪問核心虛擬地址,crash還需要對unwind_stack做少許修改,
用readmem來訪問核心虛擬地址。對應mips的實現是mips64_unwind_stack。具體的函式這裡就不貼了,
僅僅簡要說明一下mips的堆疊回溯原理。mips的回溯,核心思想就是一層一層的找呼叫函式的ra,
葉子函式的ra就是當前暫存器,非葉子函式的ra儲存在函式棧裡,下面用這個簡單例子來作為本文的結尾:
func3()
{
}
func2()
{
func3();
}
func1()
{
func2();
}
main()
{
func3();
} </pre><pre code_snippet_id="486572" snippet_file_name="blog_20141017_52_3660158" name="code" class="cpp">func3: //葉子函式,所以ra一直沒有變化過,返回時可以jr ra來返回
addi sp,sp,-24 //於是可以通過暫存器裡的ra值得到上一級pc
xxx
jr ra
func2:
addi sp,sp,-52 //非葉子函式,如果要找到ra,就需要根據sp裡的值來確認
sw ra,48(sp) //根據當前sp的值,加上52是棧幀,接著減去(52-48),就得到ra儲存的位置,實際上就是sp+48,取出ra得到func1裡的某句地址
jal func3 //即上一層pc,jal會把pc的下一條指令放到ra裡,再進行跳轉,相對於jr直接跳轉
nop
func1: //同上
addi sp,sp,-48
sw ra,44(sp)
jal func2
nop