
京東大資料平臺產品體系揭祕
阿新 • • 發佈:2019-01-06
對於剛剛成長起來的京東大資料平臺來說,資料產品並不是一個新鮮事物,2011年自建資料倉庫上線的同時,第一款資料產品排程平臺也一同上線並正式投入使用。在Tiger的指導下,排程平臺無論是UI、功能還是使用者體驗各方面都獲得一致的好評。
排程平臺
訂單交易,倉儲物流等眾多京東系統都會產生資料,僅日誌內容每天的大小約為100TB,大量的資料如何統一彙總到資料倉庫來呢?這就需要排程產品來實現資料生產。京東排程平臺發展至今已經是3.0版本,每一次的更新迭代都凝聚著阿敏等幾位開發工程師的許許多多個日夜的心血,也是我們技術突破與功能升級的具體體現。
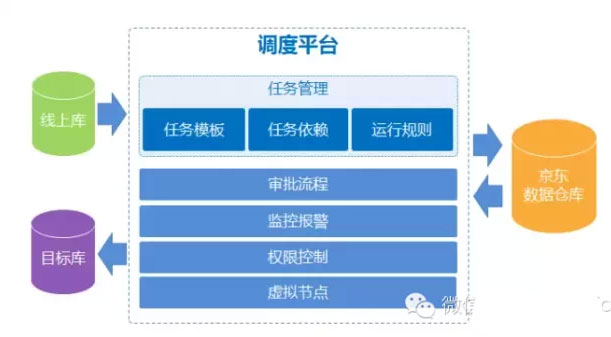 排程平臺1.0版本架構
1.0版本於2011年8月上線,一臺伺服器作為中心節點指揮排程,另外3臺伺服器負責相關資料作業,任務之間通過後置變數的方式設定前後依賴關係,排程機制便執行起來了。資料倉庫建立之初的任務並不太多,資料量沒有太過龐大,資料ETL過程所需計算資源也都完全應付得來。但隨著倉庫收納資料的增加,資料生產任務越來越多,任務之間的依賴關係也變得越來越複雜。每個BI工程師需要根據自己的生產任務設定後置變數的值以建立任務依賴關係,任務多了之後不但設定起來耗時費力且不易管理,當一個人的任務需要重跑時後置變數的修改可能會影響到別人的任務。
2.0版本上線了新的排程引擎,徹底解決了這個問題。新任務上線只需要選擇依賴的父任務即可建立關係,且流程獨立,不會因同一個任務被多個依賴而造成干擾。除此之外,任務視覺化配置與瀏覽功能也在這個版本上線,任務執行狀態監控預警功能也投入使用。這之後的功能升級也一直在進行,較大的功能改進莫過於虛擬節點了。資料生產過程中,儘管機率很低,但仍然還是會出現一些物理節點掛掉的情況,而這種情況一旦出現,影響將會很嚴重。於是,虛擬節點的功能應運而生,原理就是在原來的物理機叢集上做一層虛擬化,如果遇到生產節點故障的情況自動切換到另一個節點。同時,根據不同節點的負荷,將新的任務自動分配到負荷較小的節點,做到負載均衡。這一系列功能的上線使得平臺的穩定性大大提高。
3.0版本從功能上更加豐富,並且實現了資料生產的半自動化執行機制。所謂的半自動化是指資料任務可在配置目標資料庫、表之後自動生成ETL模板並完成資料清洗,之後是人工建立排程任務完成資料生產。另外,自主研發的抽數模組Plumber也在這個版本中上線,Plumber技術實現了異構資料庫之間的快速資料交換,且具有較高的穩定性,資料匯入匯出的維護成本也大大降低。還有伺服器執行狀態的監控系統Phenix也整合到了排程監控中,實時採集伺服器執行狀態資料並對伺服器心跳、儲存空間使用、CPU資源消耗等進行預警。對於上游系統故障造成的歷史資料補充問題,之前的版本中需要人工查詢相關依賴任務,然後一個一個配置引數後點擊重跑,而在新的版本中BI工程師們期待已久的一鍵重跑功能上線了,並且支援批量操作。一千多個重跑任務,BI工程師加班到半夜一個一個點滑鼠的日子永遠成為了過去。
作為大資料平臺的核心繫統,排程平臺不僅承擔著資料生產的重要使命,同時也負責集市資料推送,模型資料加工等任務,部門有超過三分之一的人都在圍著它轉,重要性可想而知。今後的功能升級迭代將在增強生產能力的同時更加註重自動化服務及開放運營等平臺產品的特性,為大資料管理及挖掘大資料價值提供可靠保障。
資料整合開發平臺
資料整合開發平臺是京東大資料發展的一個里程碑產品,它的出現結束了資料分析師和業務部門資料需求人員通過客戶端工具手工提取資料的痛苦經歷,並對後來的資料知識管理平臺等產品的出現產生直接影響。當前平臺使用者接近3000人,資料訂閱任務總量逾8萬個。
早期版本的資料整合開發平臺就是命名為提數工具,提數也是當時寄予這款產品的最重要的期望。相信每一家公司對於資料的需求都是“剛需”,快速發展的京東,流動並且快速流動的資料更是像一個人身體裡的血液一樣不可或缺。毫無疑問,資料提取的任務由資料部來承擔,無論是拆分狀態時還是合併一體時的資料部,資料分析師總是最繁忙的,每到月初需要支援財務經營分析的人員提取資料時,還要拉上不少工程師共同參與這場提數大戰。前後臺數據部拆分狀態時的最後幾個月裡,財務經營分析的資料提取任務幾乎被平均的分到了這兩個部門,每到月初,提數情況便成了兩個部門最直接的競爭內容,完成的不錯的話業務方可能會發個感謝信,當然,就算不提出批評,完成的不好的部門也會覺得很沒面子。前後臺數據部合併後最瘋狂日子裡,資料部實行“全員提數”,業務方通過公司的服務管理平臺發起資料提取需求,部門內幾名負責人會將需求分配給不同的人來處理。一段時間內,資料提取的數量和難易度甚至與績效考核掛鉤,提數,成了大家工作中非常重要的一部分。
正是在這樣的背景下,資料整合開發平臺的1.0版本誕生了。這是一款查詢資料並且支援週期性資料訂閱的產品,同時打通了京東私有云服務Jbox,可以供已授權人員安全、便捷的查詢和提取資料,尤其對於需要定期提取大量資料做分析的人員(如財務經營分析同事)有很大幫助。功能上來講,通過Web端線上資料查詢和資料訂閱是兩大主要功能,同時,SQL編寫介面還支援元資料資訊的檢視,並且可以線上儲存編輯中的程式碼,這給提數人員帶來很大便利。底層接入的資料庫包括當時存在的SQL Server、MySQL和Hive,SQL語法上根據不同的資料庫型別選擇不同的語法即可,其它執行邏輯都是一樣的。產品開發主要由彥偉團隊負責,從初期版本上線到後期功能升級,Tiger也給出了很多極具參考價值的意見,不斷完善的產品吸引了大量使用者的註冊使用。
同樣採用Extjs的前端頁面偶爾存在一些滾動條失靈的小Bug,這給使用者體驗上帶來一定影響。另外,雖然Extjs強大的表單功能成就了整合開發平臺這樣的富客戶端應用,但是其UI風格的侷限性也是非常明顯的。隨著後期產品線的豐富,新推出的產品已經棄用Extjs,轉而採用Bootstrap前端,於是在2014年7月份,採用新的前端技術,資料整合開發平臺與後期推出的資料知識管理及資料質量監控產品融合後統一在一個系統上線。
資料知識管理平臺
資料知識管理平臺產品的出現是個水到渠成的結果,在資料倉庫模型規範確定之後,元資料資訊也有了標準的分類體系。按照標準的分類體系將元資料資訊分門別類管理起來,同時提供內容搜尋、類Wiki的編輯維護以及諮詢評論功能,資料知識管理平臺就呈現在大家面前了。後期版本升級過程中又提供了維度表的維護功能,給模型開發維護的同事帶來很大便利。
京東分析師
Apricot(杏子)、Blueberry(藍莓)、Cloudberry(雲莓),水果連連看?不,這是報表展現平臺三個版本命名的代號,也是產品域名的首段字串,首字母分別是ABC也代表了產品演進的過程。當前版本代號為Cloudberry,產品正式名稱為京東分析師,毫無疑問,我們賦予這款產品的除了基本的資料視覺化能力,還有資料分析的能力。體驗過Tableau的使用者都會被其靈活的控制檯和美妙絕倫的圖表展現所征服。我們所做的就是在Web系統中儘可能的實現Tableau桌面系統所能達到的效果,並且在產品服務能力上更加強調自助服務的智慧軟體分析平臺。
技術架構上,京東分析師前端自主開發可自定義的展現佈局,封裝了豐富的圖表展現元件,後端報表配置系統支援MySQL、SQL Server、Oracle、API及Hive等作為資料來源,並支援線上接入。互動方面,報表收藏、基於圖表的條件過濾、資料排序、深度鑽取是其基本功能,自定義報表頁面還提供郵件推送報表的功能,當某個報表資料比較重要,系統可通過郵件的形式定期傳送報表供查閱。對於自己許可權範圍內可瀏覽的表,系統還可根據瀏覽記錄將經常檢視的表排在靠前的位置以提升體驗。
資料探勘平臺
大資料的資料探勘與傳統意義上的處理方法存在很大區別,京東資料探勘平臺產品定位於構建一站式的資料探勘演算法平臺;在基礎的機器學習演算法之上,可根據具體實際業務開發訂製演算法,滿足演算法應用場景。這一產品主要利用分散式計算,採取適用於機器學習演算法的計算模型進行迭代,以解決大資料量的演算法處理問題。
排程平臺1.0版本架構
1.0版本於2011年8月上線,一臺伺服器作為中心節點指揮排程,另外3臺伺服器負責相關資料作業,任務之間通過後置變數的方式設定前後依賴關係,排程機制便執行起來了。資料倉庫建立之初的任務並不太多,資料量沒有太過龐大,資料ETL過程所需計算資源也都完全應付得來。但隨著倉庫收納資料的增加,資料生產任務越來越多,任務之間的依賴關係也變得越來越複雜。每個BI工程師需要根據自己的生產任務設定後置變數的值以建立任務依賴關係,任務多了之後不但設定起來耗時費力且不易管理,當一個人的任務需要重跑時後置變數的修改可能會影響到別人的任務。
2.0版本上線了新的排程引擎,徹底解決了這個問題。新任務上線只需要選擇依賴的父任務即可建立關係,且流程獨立,不會因同一個任務被多個依賴而造成干擾。除此之外,任務視覺化配置與瀏覽功能也在這個版本上線,任務執行狀態監控預警功能也投入使用。這之後的功能升級也一直在進行,較大的功能改進莫過於虛擬節點了。資料生產過程中,儘管機率很低,但仍然還是會出現一些物理節點掛掉的情況,而這種情況一旦出現,影響將會很嚴重。於是,虛擬節點的功能應運而生,原理就是在原來的物理機叢集上做一層虛擬化,如果遇到生產節點故障的情況自動切換到另一個節點。同時,根據不同節點的負荷,將新的任務自動分配到負荷較小的節點,做到負載均衡。這一系列功能的上線使得平臺的穩定性大大提高。
3.0版本從功能上更加豐富,並且實現了資料生產的半自動化執行機制。所謂的半自動化是指資料任務可在配置目標資料庫、表之後自動生成ETL模板並完成資料清洗,之後是人工建立排程任務完成資料生產。另外,自主研發的抽數模組Plumber也在這個版本中上線,Plumber技術實現了異構資料庫之間的快速資料交換,且具有較高的穩定性,資料匯入匯出的維護成本也大大降低。還有伺服器執行狀態的監控系統Phenix也整合到了排程監控中,實時採集伺服器執行狀態資料並對伺服器心跳、儲存空間使用、CPU資源消耗等進行預警。對於上游系統故障造成的歷史資料補充問題,之前的版本中需要人工查詢相關依賴任務,然後一個一個配置引數後點擊重跑,而在新的版本中BI工程師們期待已久的一鍵重跑功能上線了,並且支援批量操作。一千多個重跑任務,BI工程師加班到半夜一個一個點滑鼠的日子永遠成為了過去。
作為大資料平臺的核心繫統,排程平臺不僅承擔著資料生產的重要使命,同時也負責集市資料推送,模型資料加工等任務,部門有超過三分之一的人都在圍著它轉,重要性可想而知。今後的功能升級迭代將在增強生產能力的同時更加註重自動化服務及開放運營等平臺產品的特性,為大資料管理及挖掘大資料價值提供可靠保障。
資料整合開發平臺
資料整合開發平臺是京東大資料發展的一個里程碑產品,它的出現結束了資料分析師和業務部門資料需求人員通過客戶端工具手工提取資料的痛苦經歷,並對後來的資料知識管理平臺等產品的出現產生直接影響。當前平臺使用者接近3000人,資料訂閱任務總量逾8萬個。
早期版本的資料整合開發平臺就是命名為提數工具,提數也是當時寄予這款產品的最重要的期望。相信每一家公司對於資料的需求都是“剛需”,快速發展的京東,流動並且快速流動的資料更是像一個人身體裡的血液一樣不可或缺。毫無疑問,資料提取的任務由資料部來承擔,無論是拆分狀態時還是合併一體時的資料部,資料分析師總是最繁忙的,每到月初需要支援財務經營分析的人員提取資料時,還要拉上不少工程師共同參與這場提數大戰。前後臺數據部拆分狀態時的最後幾個月裡,財務經營分析的資料提取任務幾乎被平均的分到了這兩個部門,每到月初,提數情況便成了兩個部門最直接的競爭內容,完成的不錯的話業務方可能會發個感謝信,當然,就算不提出批評,完成的不好的部門也會覺得很沒面子。前後臺數據部合併後最瘋狂日子裡,資料部實行“全員提數”,業務方通過公司的服務管理平臺發起資料提取需求,部門內幾名負責人會將需求分配給不同的人來處理。一段時間內,資料提取的數量和難易度甚至與績效考核掛鉤,提數,成了大家工作中非常重要的一部分。
正是在這樣的背景下,資料整合開發平臺的1.0版本誕生了。這是一款查詢資料並且支援週期性資料訂閱的產品,同時打通了京東私有云服務Jbox,可以供已授權人員安全、便捷的查詢和提取資料,尤其對於需要定期提取大量資料做分析的人員(如財務經營分析同事)有很大幫助。功能上來講,通過Web端線上資料查詢和資料訂閱是兩大主要功能,同時,SQL編寫介面還支援元資料資訊的檢視,並且可以線上儲存編輯中的程式碼,這給提數人員帶來很大便利。底層接入的資料庫包括當時存在的SQL Server、MySQL和Hive,SQL語法上根據不同的資料庫型別選擇不同的語法即可,其它執行邏輯都是一樣的。產品開發主要由彥偉團隊負責,從初期版本上線到後期功能升級,Tiger也給出了很多極具參考價值的意見,不斷完善的產品吸引了大量使用者的註冊使用。
同樣採用Extjs的前端頁面偶爾存在一些滾動條失靈的小Bug,這給使用者體驗上帶來一定影響。另外,雖然Extjs強大的表單功能成就了整合開發平臺這樣的富客戶端應用,但是其UI風格的侷限性也是非常明顯的。隨著後期產品線的豐富,新推出的產品已經棄用Extjs,轉而採用Bootstrap前端,於是在2014年7月份,採用新的前端技術,資料整合開發平臺與後期推出的資料知識管理及資料質量監控產品融合後統一在一個系統上線。
資料知識管理平臺
資料知識管理平臺產品的出現是個水到渠成的結果,在資料倉庫模型規範確定之後,元資料資訊也有了標準的分類體系。按照標準的分類體系將元資料資訊分門別類管理起來,同時提供內容搜尋、類Wiki的編輯維護以及諮詢評論功能,資料知識管理平臺就呈現在大家面前了。後期版本升級過程中又提供了維度表的維護功能,給模型開發維護的同事帶來很大便利。
京東分析師
Apricot(杏子)、Blueberry(藍莓)、Cloudberry(雲莓),水果連連看?不,這是報表展現平臺三個版本命名的代號,也是產品域名的首段字串,首字母分別是ABC也代表了產品演進的過程。當前版本代號為Cloudberry,產品正式名稱為京東分析師,毫無疑問,我們賦予這款產品的除了基本的資料視覺化能力,還有資料分析的能力。體驗過Tableau的使用者都會被其靈活的控制檯和美妙絕倫的圖表展現所征服。我們所做的就是在Web系統中儘可能的實現Tableau桌面系統所能達到的效果,並且在產品服務能力上更加強調自助服務的智慧軟體分析平臺。
技術架構上,京東分析師前端自主開發可自定義的展現佈局,封裝了豐富的圖表展現元件,後端報表配置系統支援MySQL、SQL Server、Oracle、API及Hive等作為資料來源,並支援線上接入。互動方面,報表收藏、基於圖表的條件過濾、資料排序、深度鑽取是其基本功能,自定義報表頁面還提供郵件推送報表的功能,當某個報表資料比較重要,系統可通過郵件的形式定期傳送報表供查閱。對於自己許可權範圍內可瀏覽的表,系統還可根據瀏覽記錄將經常檢視的表排在靠前的位置以提升體驗。
資料探勘平臺
大資料的資料探勘與傳統意義上的處理方法存在很大區別,京東資料探勘平臺產品定位於構建一站式的資料探勘演算法平臺;在基礎的機器學習演算法之上,可根據具體實際業務開發訂製演算法,滿足演算法應用場景。這一產品主要利用分散式計算,採取適用於機器學習演算法的計算模型進行迭代,以解決大資料量的演算法處理問題。
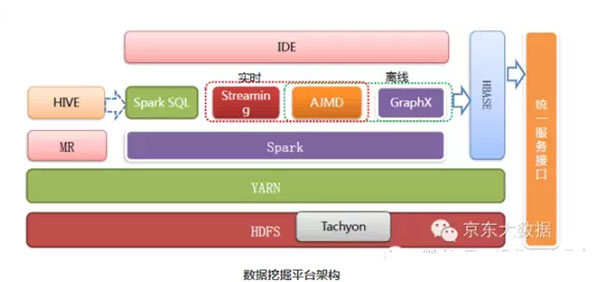
排程平臺1.0版本架構
1.0版本於2011年8月上線,一臺伺服器作為中心節點指揮排程,另外3臺伺服器負責相關資料作業,任務之間通過後置變數的方式設定前後依賴關係,排程機制便執行起來了。資料倉庫建立之初的任務並不太多,資料量沒有太過龐大,資料ETL過程所需計算資源也都完全應付得來。但隨著倉庫收納資料的增加,資料生產任務越來越多,任務之間的依賴關係也變得越來越複雜。每個BI工程師需要根據自己的生產任務設定後置變數的值以建立任務依賴關係,任務多了之後不但設定起來耗時費力且不易管理,當一個人的任務需要重跑時後置變數的修改可能會影響到別人的任務。
2.0版本上線了新的排程引擎,徹底解決了這個問題。新任務上線只需要選擇依賴的父任務即可建立關係,且流程獨立,不會因同一個任務被多個依賴而造成干擾。除此之外,任務視覺化配置與瀏覽功能也在這個版本上線,任務執行狀態監控預警功能也投入使用。這之後的功能升級也一直在進行,較大的功能改進莫過於虛擬節點了。資料生產過程中,儘管機率很低,但仍然還是會出現一些物理節點掛掉的情況,而這種情況一旦出現,影響將會很嚴重。於是,虛擬節點的功能應運而生,原理就是在原來的物理機叢集上做一層虛擬化,如果遇到生產節點故障的情況自動切換到另一個節點。同時,根據不同節點的負荷,將新的任務自動分配到負荷較小的節點,做到負載均衡。這一系列功能的上線使得平臺的穩定性大大提高。
3.0版本從功能上更加豐富,並且實現了資料生產的半自動化執行機制。所謂的半自動化是指資料任務可在配置目標資料庫、表之後自動生成ETL模板並完成資料清洗,之後是人工建立排程任務完成資料生產。另外,自主研發的抽數模組Plumber也在這個版本中上線,Plumber技術實現了異構資料庫之間的快速資料交換,且具有較高的穩定性,資料匯入匯出的維護成本也大大降低。還有伺服器執行狀態的監控系統Phenix也整合到了排程監控中,實時採集伺服器執行狀態資料並對伺服器心跳、儲存空間使用、CPU資源消耗等進行預警。對於上游系統故障造成的歷史資料補充問題,之前的版本中需要人工查詢相關依賴任務,然後一個一個配置引數後點擊重跑,而在新的版本中BI工程師們期待已久的一鍵重跑功能上線了,並且支援批量操作。一千多個重跑任務,BI工程師加班到半夜一個一個點滑鼠的日子永遠成為了過去。
作為大資料平臺的核心繫統,排程平臺不僅承擔著資料生產的重要使命,同時也負責集市資料推送,模型資料加工等任務,部門有超過三分之一的人都在圍著它轉,重要性可想而知。今後的功能升級迭代將在增強生產能力的同時更加註重自動化服務及開放運營等平臺產品的特性,為大資料管理及挖掘大資料價值提供可靠保障。
資料整合開發平臺
資料整合開發平臺是京東大資料發展的一個里程碑產品,它的出現結束了資料分析師和業務部門資料需求人員通過客戶端工具手工提取資料的痛苦經歷,並對後來的資料知識管理平臺等產品的出現產生直接影響。當前平臺使用者接近3000人,資料訂閱任務總量逾8萬個。
早期版本的資料整合開發平臺就是命名為提數工具,提數也是當時寄予這款產品的最重要的期望。相信每一家公司對於資料的需求都是“剛需”,快速發展的京東,流動並且快速流動的資料更是像一個人身體裡的血液一樣不可或缺。毫無疑問,資料提取的任務由資料部來承擔,無論是拆分狀態時還是合併一體時的資料部,資料分析師總是最繁忙的,每到月初需要支援財務經營分析的人員提取資料時,還要拉上不少工程師共同參與這場提數大戰。前後臺數據部拆分狀態時的最後幾個月裡,財務經營分析的資料提取任務幾乎被平均的分到了這兩個部門,每到月初,提數情況便成了兩個部門最直接的競爭內容,完成的不錯的話業務方可能會發個感謝信,當然,就算不提出批評,完成的不好的部門也會覺得很沒面子。前後臺數據部合併後最瘋狂日子裡,資料部實行“全員提數”,業務方通過公司的服務管理平臺發起資料提取需求,部門內幾名負責人會將需求分配給不同的人來處理。一段時間內,資料提取的數量和難易度甚至與績效考核掛鉤,提數,成了大家工作中非常重要的一部分。
正是在這樣的背景下,資料整合開發平臺的1.0版本誕生了。這是一款查詢資料並且支援週期性資料訂閱的產品,同時打通了京東私有云服務Jbox,可以供已授權人員安全、便捷的查詢和提取資料,尤其對於需要定期提取大量資料做分析的人員(如財務經營分析同事)有很大幫助。功能上來講,通過Web端線上資料查詢和資料訂閱是兩大主要功能,同時,SQL編寫介面還支援元資料資訊的檢視,並且可以線上儲存編輯中的程式碼,這給提數人員帶來很大便利。底層接入的資料庫包括當時存在的SQL Server、MySQL和Hive,SQL語法上根據不同的資料庫型別選擇不同的語法即可,其它執行邏輯都是一樣的。產品開發主要由彥偉團隊負責,從初期版本上線到後期功能升級,Tiger也給出了很多極具參考價值的意見,不斷完善的產品吸引了大量使用者的註冊使用。
同樣採用Extjs的前端頁面偶爾存在一些滾動條失靈的小Bug,這給使用者體驗上帶來一定影響。另外,雖然Extjs強大的表單功能成就了整合開發平臺這樣的富客戶端應用,但是其UI風格的侷限性也是非常明顯的。隨著後期產品線的豐富,新推出的產品已經棄用Extjs,轉而採用Bootstrap前端,於是在2014年7月份,採用新的前端技術,資料整合開發平臺與後期推出的資料知識管理及資料質量監控產品融合後統一在一個系統上線。
資料知識管理平臺
資料知識管理平臺產品的出現是個水到渠成的結果,在資料倉庫模型規範確定之後,元資料資訊也有了標準的分類體系。按照標準的分類體系將元資料資訊分門別類管理起來,同時提供內容搜尋、類Wiki的編輯維護以及諮詢評論功能,資料知識管理平臺就呈現在大家面前了。後期版本升級過程中又提供了維度表的維護功能,給模型開發維護的同事帶來很大便利。
京東分析師
Apricot(杏子)、Blueberry(藍莓)、Cloudberry(雲莓),水果連連看?不,這是報表展現平臺三個版本命名的代號,也是產品域名的首段字串,首字母分別是ABC也代表了產品演進的過程。當前版本代號為Cloudberry,產品正式名稱為京東分析師,毫無疑問,我們賦予這款產品的除了基本的資料視覺化能力,還有資料分析的能力。體驗過Tableau的使用者都會被其靈活的控制檯和美妙絕倫的圖表展現所征服。我們所做的就是在Web系統中儘可能的實現Tableau桌面系統所能達到的效果,並且在產品服務能力上更加強調自助服務的智慧軟體分析平臺。
技術架構上,京東分析師前端自主開發可自定義的展現佈局,封裝了豐富的圖表展現元件,後端報表配置系統支援MySQL、SQL Server、Oracle、API及Hive等作為資料來源,並支援線上接入。互動方面,報表收藏、基於圖表的條件過濾、資料排序、深度鑽取是其基本功能,自定義報表頁面還提供郵件推送報表的功能,當某個報表資料比較重要,系統可通過郵件的形式定期傳送報表供查閱。對於自己許可權範圍內可瀏覽的表,系統還可根據瀏覽記錄將經常檢視的表排在靠前的位置以提升體驗。
資料探勘平臺
大資料的資料探勘與傳統意義上的處理方法存在很大區別,京東資料探勘平臺產品定位於構建一站式的資料探勘演算法平臺;在基礎的機器學習演算法之上,可根據具體實際業務開發訂製演算法,滿足演算法應用場景。這一產品主要利用分散式計算,採取適用於機器學習演算法的計算模型進行迭代,以解決大資料量的演算法處理問題。