
MySQL索引優化 & 聚簇索引 & 欄位選擇性 & 範圍查詢 & 組合索引的欄位順序
索引B-Tree:
一般來說, MySQL 中的 B-Tree 索引的物理檔案大多都是以 B+tree的結構來儲存的,也就是所有實際需要的資料都存放於 Tree 的 Leaf Node,而且到任何一個 Leaf Node 的最短路徑的長度都是完全相同的,可能各種資料庫(或 MySQL 的各種儲存引擎)在存放自己的 B-Tree 索引的時候會對儲存結構稍作改造。如 Innodb 儲存引擎的 B-Tree 索引實際使用的儲存結構實際上是 B+Tree ,也就是在 B-Tree 資料結構的基礎上做了很小的改造,在每一個Leaf Node 上面出了存放索引鍵值和主鍵的相關資訊之外,B+Tree還儲存了指向與該 Leaf Node 相鄰的後一個 LeafNode 的指標資訊,這主要是為了加快檢索多個相鄰 Leaf Node 的效率考慮。
B-Tree對索引列是順序組織儲存的,所以很適合查詢範圍資料,例如,在一個基於文字域的索引樹上,按字母順序傳遞連續的值進行查詢是非常合適的,所以像 “找出所有以 A 到 K 開頭的名字” 這樣的查詢效率會非常高。
因為索引樹中的節點是有序的,所以除了按值查詢之外,索引還可以用於查詢中的ORDER BY(按順序查詢),GROUP BY(按分組查詢)操作。一般來說,如果 B-Tree 可以按照某種方式查詢到值,那麼也可以按照這種方式用於排序。所以,索引對 ORDER BY 子句也可以滿足對應的排序需求。
在innodb引擎中,btree索引分為兩種,1,聚簇索引(主鍵索引),或者說叫聚集索引,因為資料的邏輯順序與物理順序都是緊湊的。2.二級索引(非聚簇索引),或者說叫輔助索引。InnoDB中的主鍵索引是聚集索引,表資料檔案本身就是按B+Tree組織的一個索引結構,這棵樹的葉節點data域儲存了完整的資料記錄(整行資料)。這個索引的key是資料表的主鍵,因此InnoDB表資料檔案本身就是主鍵索引。但是innodb的二級索引,儲存的是索引列值以及指向主鍵的指標,所以我們使用覆蓋索引的做優化處理就是針對mysql的innodb的索引而言的。
下面兩張圖顯示mysql中innodb和myisam引擎的索引實現的原理
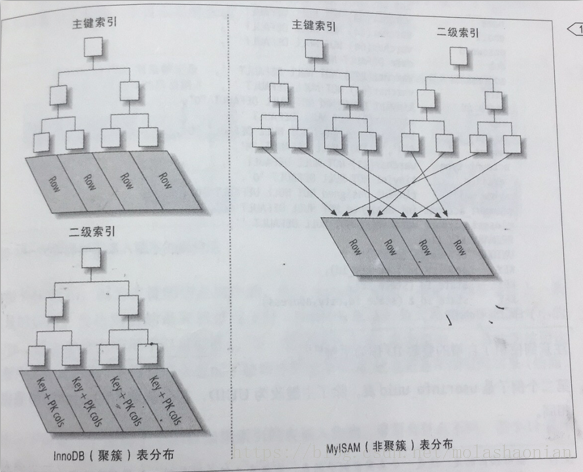
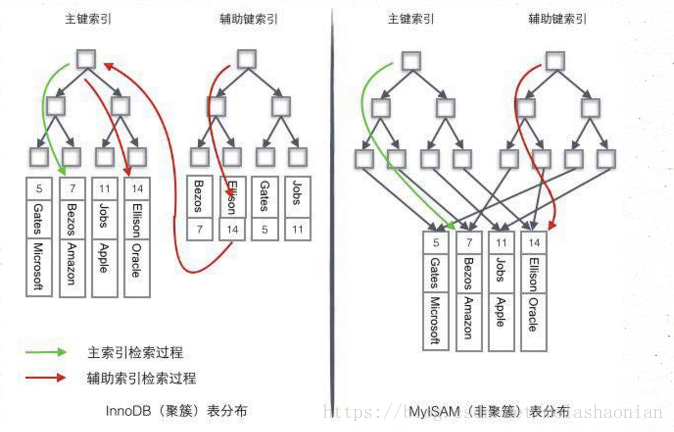
看上去聚簇索引的效率明顯要低於非聚簇索引,因為每次使用輔助索引檢索都要經過兩次B+樹查詢,這不是多此一舉嗎?聚簇索引的優勢在哪?
- 由於行資料和葉子節點儲存在一起,這樣主鍵和行資料是一起被載入記憶體的,找到葉子節點就可以立刻將行資料返回了,如果按照主鍵Id來組織資料,獲得資料更快。
- 輔助索引使用主鍵作為"指標" 而不是使用行地址值作為指標的好處是,減少了當出現行移動或者資料頁分裂時輔助索引的維護工作,使用主鍵值當作指標會讓輔助索引佔用更多的空間,換來的好處是InnoDB在移動行時無須更新輔助索引中的這個"指標",使用聚簇索引可以保證不管這個主鍵B+樹的節點如何變化,輔助索引樹都不受影響。
關於 InnoDB,索引和鎖有一些很少有人知道的細節:InnoDB 在二級索引上使用共享(讀)鎖,但訪問主鍵索引需要排他(寫)鎖。這消除了使用覆蓋索引的可能性,並且使得 SELECT FOR UPDATE 比 LOCK IN SHARE MODE 或非鎖定查詢要慢很多。
啊哈哈,概念扯多了。
你需要知道的:
- 不要求每個人一定理解 聯表查詢(join/left join/inner join等)時的mysql運算過程,但對於欄位選擇性差意味著什麼,組合索引欄位順序意味著什麼,要求每個人必須瞭解;
- 把mysql客戶端(如SQLyog,如HeidiSQL)放在桌面上,時不時拿出來 explain 一把,這是一種美德!
- 確保親手查過SQL的執行計劃,一定要注意看執行計劃裡的 possible_keys、key和rows這三個值,讓影響行數儘量少,保證使用到正確的索引,減少不必要的Using temporary/Using filesort;
- 不要在選擇性非常差的欄位上建索引,原因參見優化策略A;
- 查詢條件裡出現範圍查詢(如A>7,A in (2,3))時,要警惕,不要建了組合索引卻完全用不上,原因參見優化策略B;
——欄位選擇性的基礎知識——
引子:什麼欄位都可以建索引嗎?
如下表所示,sort 欄位的選擇性非常差,你可以執行 show index from ads 命令可以看到 sort 的 Cardinality(雜湊程度)只有 9,這種欄位上本不應該建索引:
| Table |
Non_unique |
Key_name |
Seq_in_index |
Column_name |
Collation |
Cardinality |
Sub_part |
Packed |
Null |
Index_type |
Comment |
| ads |
1 |
sort |
1 |
sort |
A |
9 |
\N |
\N |
|
BTREE |
|
優化策略A:欄位選擇性
- 選擇性較低索引 可能帶來的效能問題
- 索引選擇性=索引列唯一值/表記錄數;
- 選擇性越高索引檢索價值越高,消耗系統資源越少;選擇性越低索引檢索價值越低,消耗系統資源越多;
- 查詢條件含有多個欄位時,不要在選擇性很低欄位上建立索引
- 可通過建立組合索引來增強低欄位選擇性和避免選擇性很低欄位建立索引帶來副作用;
- 儘量減少possible_keys,正確索引會提高sql查詢速度,過多索引會增加優化器選擇索引的代價,不要濫用索引;
——組合索引欄位順序與範圍查詢之間的關係——
引子:範圍查詢 city_id in (0,8,10) 能用組合索引 (ads_id,city_id) 嗎?
舉例,
ac 表有一個組合索引(ads_id,city_id)。
那麼如下 ac.city_id IN (0, 8005) 查詢條件能用到 ac表的組合索引(ads_id,city_id) 嗎?
EXPLAIN
SELECT ac.ads_id
FROM ads, ac
WHERE
ads.id = ac.ads_id
AND ac.city_id IN (0, 8005)
AND ads.status = 'online'
AND ac.start_time<UNIX_TIMESTAMP()
AND ac.end_time>UNIX_TIMESTAMP()
優化策略B:
由於 mysql 索引是基於 B-Tree 的,所以組合索引有“欄位順序”概念。
所以,查詢條件中有 ac.city_id IN (0, 8005),而組合索引是 (ads_id,city_id),則該查詢無法使用到這個組合索引。
DBA總結道:
組合索引查詢的各種場景
茲有 Index (A,B,C) ——組合索引多欄位是有序的,並且是個完整的BTree 索引。
- 下面條件可以用上該組合索引查詢:
- A>5
- A=5 AND B>6
- A=5 AND B=6 AND C=7
- A=5 AND B IN (2,3) AND C>5
- 下面條件將不能用上組合索引查詢:
- B>5 ——查詢條件不包含組合索引首列欄位
- B=6 AND C=7 ——查詢條件不包含組合索引首列欄位
- 下面條件將能用上部分組合索引查詢:
- A>5 AND B=2 ——當範圍查詢使用第一列,查詢條件僅僅能使用第一列
- A=5 AND B>6 AND C=2 ——範圍查詢使用第二列,查詢條件僅僅能使用前二列
組合索引排序的各種場景
茲有組合索引 Index(A,B)。
- 下面條件可以用上組合索引排序:
- ORDER BY A——首列排序
- A=5 ORDER BY B——第一列過濾後第二列排序
- ORDER BY A DESC, B DESC——注意,此時兩列以相同順序排序
- A>5 ORDER BY A——資料檢索和排序都在第一列
- 下面條件不能用上組合索引排序:
- ORDER BY B ——排序在索引的第二列
- A>5 ORDER BY B ——範圍查詢在第一列,排序在第二列
- A IN(1,2) ORDER BY B ——理由同上
- ORDER BY A ASC, B DESC ——注意,此時兩列以不同順序排序
順著組合索引怎麼建繼續往下延伸,請各位注意“索引合併”概念:
- MySQL 5,0以下版本,SQL查詢時,一張表只能用一個索引(use at most only one index for each referenced table),
- 從 MySQL 5.0開始,引入了 index merge 概念,包括 Index Merge Union Access Algorithm(多個索引並集訪問),包括Index Merge Intersection Access Algorithm(多個索引交集訪問),可以在一個SQL查詢裡用到一張表裡的多個索引。
- MySQL 在5.6.7之前,使用 index merge 有一個重要的前提條件:沒有 range 可以使用。
索引合併的簡單說明:
- MySQL 索引合併能使用多個索引
- SELECT * FROM TB WHERE A=5 AND B=6
- 能分別使用索引(A) 和 (B) 或 索引合併;
- 建立組合索引(A,B) 更好;
- SELECT * FROM TB WHERE A=5 OR B=6
- 能分別使用索引(A) 和 (B) 或 索引合併;
- 組合索引(A,B)不能用於此查詢,分別建立索引(A) 和 (B)會更好;
- 或者使用 UNION ALL,SELECT * FROM TB WHERE A=5 UNION ALL SELECT * FROM TB WHERE A=6
- SELECT * FROM TB WHERE A=5 AND B=6
優化 LIMIT 分頁:
- 優化大偏移量的效能,儘可能地使用索引覆蓋掃描,而不是查詢所有的列,然後根據需要做一次關聯操作再返回所需的列
- 如“延遲關聯”:SELECT * FROM TB INNER JOIN (SELECT id FROM TB ORDER BY id LIMIT 50,5) AS TB1 USING(id)
- 有時候也可以將 LIMIT 查詢轉換為已知位置的查詢,讓 MySQL 通過範圍掃描獲得對應的結果
- LIMIT 和 OFFSET 的問題,其實是 OFFSET 的問題,它會導致 MySQL 掃描大量不需要的行然後再拋棄掉。所以我們應該儘可能地避免這種大量掃描行的行為來優化分頁查詢
最後的總結:
仍然是強調再強調:
記住,explain 後再提測是一種美德!
關注公眾號,分享乾貨,討論技術
