
python3 三種字串(無字首,字首u,字首b)與encode()
假設讀者已經瞭解了什麼叫字符集,什麼叫編碼,什麼叫解碼。
首先要明確,雖然有三種字首(無字首,字首u,字首b),但是字串的型別只有兩種(str,bytes),實驗如下:

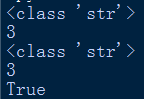

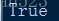
根據程式以及以上執行結果,發現無字首,和字首u,構造出來的字串常量,是一樣的。
型別一樣是str,長度一樣是3,==判斷也是返回true。is判斷也是返回true。
其實,這裡是因為,python3中,字串的儲存方式都是以Unicode字元來儲存的,所以字首帶不帶u,其實都一樣。
結論:字串常量,字首帶不帶u,都是一樣的。
不管是utf-8,還是gbk,都可以理解為一種對應關係(若干個十六進位制數<——>某個字元):
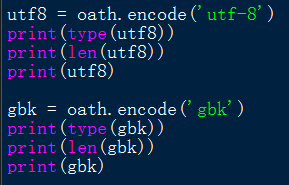
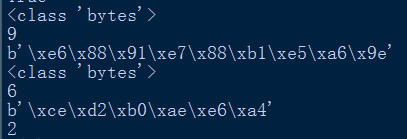
所以可以發現任何str型別的字串,在經過encode('utf-8')後,就是通過utf-8這種編碼解碼方式(兩種方向),將Unicode字元轉換為對應的以位元組方式儲存的若干十六進位制數。
根據如上程式以及結果,可以發現,utf-8用三個十六進位制來表示一箇中文字元,而gbk用二個十六進位制來表示一箇中文字元。
結論:encode()函式根據括號內的編碼方式,把str型別的字串轉換為bytes字串,字元對應的若干十六進位制數,根據編碼方式決定。
既然知道了,str實際儲存的是Unicode字元,那麼也可以Unicode編碼來儲存str,形如\u1234:
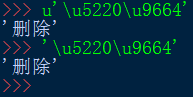
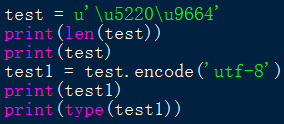
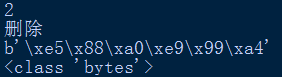
結論:str型別的字串,每個字元用字元本身或者\u1234,來表示都可以,後者則是直接是Unicode編碼。但列印時都是列印字元本身。
bytes字串的組成形式,必須是十六進位制數,或者ASCII字元:

提示錯誤:bytes只能包含ASCII字元。
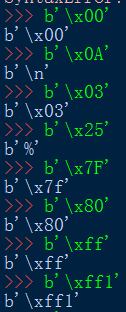

還可以對bytes取索引,所以這裡bytes也可以用for迴圈來迭代了,因為也是可迭代物件。
取索引,將所在元素的數,轉換為十進位制數。
程式碼:
oath = '我愛妞' print(type(oath)) print(len(oath)) oath1 = u'我愛妞' print(type(oath1)) print(len(oath1)) print(oath==oath1) utf8 = oath.encode('utf-8') print(type(utf8)) print(len(utf8)) print(utf8) gbk = oath.encode('gbk') print(type(gbk)) print(len(gbk)) print(gbk) out = open('test.txt','w',encoding = 'utf-8') test = u'\u5220\u9664' print(len(test)) print(test) test1 = test.encode('utf-8') print(test1) print(type(test1)) out.write(test) out.close()