
10+倍效能提升全過程--優酷賬號繫結淘寶賬號的TPS從500到5400的優化歷程
10+倍效能提升全過程--優酷賬號繫結淘寶賬號的TPS從500到5400的優化歷程
摘要: # 10+倍效能提升全過程--優酷賬號繫結淘寶賬號的TPS從500到5400的優化歷程 ## 背景說明 > 2016年的雙11在淘寶上買買買的時候,天貓和優酷土豆一起做了聯合促銷,在天貓雙11當天購物滿XXX元就贈送優酷會員,這個過程需要使用者在優酷側繫結淘寶賬號(登入優酷、提供淘寶賬號,優酷呼叫淘寶API實現兩個賬號繫結)和贈送會員並讓會員權益生效(看收費影片、免廣告等等) >
10+倍效能提升全過程--優酷賬號繫結淘寶賬號的TPS從500到5400的優化歷程
背景說明
2016年的雙11在淘寶上買買買的時候,天貓和優酷土豆一起做了聯合促銷,在天貓雙11當天購物滿XXX元就贈送優酷會員,這個過程需要使用者在優酷側繫結淘寶賬號(登入優酷、提供淘寶賬號,優酷呼叫淘寶API實現兩個賬號繫結)和贈送會員並讓會員權益生效(看收費影片、免廣告等等)
這裡涉及到優酷的兩個部門:Passport(在上海,負責登入、繫結賬號,下文中的優化過程主要是Passport部分);會員(在北京,負責贈送會員,保證權益生效)
在雙11活動之前,Passport的繫結賬號功能一直在執行,只是沒有碰到過大促銷帶來的挑戰
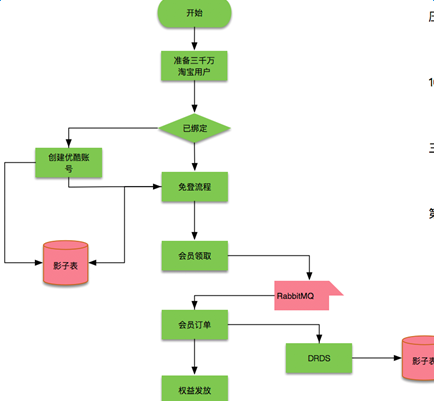
會員部分的架構改造
- 接入中介軟體DRDS,讓優酷的資料庫支援拆分,分解MySQL壓力
- 接入中介軟體vipserver來支援負載均衡
- 接入集團DRC來保障資料的高可用
- 對業務進行改造支援Amazon的全鏈路壓測
主要的壓測過程
上圖是壓測過程中主要的階段中問題和改進,主要的問題和優化過程如下:
- docker bridge網路效能問題和網路中斷si不均衡 (優化後:500->1000TPS)
- 短連線導致的local port不夠 (優化後:1000-3000TPS)
- 生產環境snat單核導致的網路延時增大 (優化後能達到測試環境的3000TPS)
- Spring MVC Path帶來的過高的CPU消耗 (優化後:3000->4200TPS)
- 其他業務程式碼的優化(比如異常、agent等) (優化後:4200->5400TPS)
優化過程中碰到的比如淘寶api呼叫次數限流等一些業務問題就不列出來了
Passport部分的壓力
由於使用者進來後先要登入並且繫結賬號,實際壓力先到Passport部分,在這個過程中最開始單機TPS只能到500,經過N輪優化後基本能達到5400 TPS,下面主要是闡述這個優化過程
Passport 核心服務分兩個:
- Login 主要處理登入請求
- userservice 處理登入後的業務邏輯,比如將優酷賬號和淘寶賬號繫結
為了更好地利用資源每臺物理加上部署三個docker 容器,跑在不同的埠上(8081、8082、8083),通過bridge網路來互相通訊
Passport機器大致結構

說明:這裡的500 TPS到5400 TPS是指登入和將優酷賬號和淘寶賬號繫結的TPS,也是促銷活動主要的瓶頸
userservice服務網路相關的各種問題
太多SocketConnect異常(如上圖)
在userservice機器上通過netstat也能看到大量的SYN_SENT狀態,如下圖:
因為docker bridge通過nat來實現,嘗試去掉docker,讓tomcat直接跑在物理機上
這時SocketConnect異常不再出現
從新梳理一下網路流程
docker(bridge)----短連線--->訪問淘寶API(淘寶open api只能短連線訪問),效能差,cpu都花在si上;
如果 docker(bridge)----長連線到宿主機的某個代理上(比如haproxy)-----短連線--->訪問淘寶API, 效能就能好一點。問題可能是短連線放大了Docker bridge網路的效能損耗
當時看到的cpu si非常高,截圖如下:

去掉Docker後,效能有所提升,繼續通過perf top看到核心態尋找可用的Local Port消耗了比較多的CPU,gif動態截圖如下(可以點選看高清大圖):
注意圖中ipv6_rcv_saddr_equal和inet_csk_get_port 總共佔了30%的CPU
一般來說一臺機器可用Local Port 3萬多個,如果是短連線的話,一個連線釋放後預設需要60秒回收,30000/60 =500 這是大概的理論TPS值
同時觀察這個時候CPU的主要花在sy上,最理想肯定是希望CPU主要用在us上,截圖如下:
sy佔用了30-50%的CPU,這太不科學了,同時通過 netstat 分析連線狀態,確實看到很多TIME_WAIT:
於是讓PE修改了tcp相關引數:降低 tcp_max_tw_buckets和開啟tcp_tw_reuse,這個時候TPS能從1000提升到3000
優化到3000 TPS後上線繼續壓測
居然效能又回到了500,太沮喪了,其實最開始賬號繫結慢,Passport這邊就懷疑taobao api是不是在大壓力下不穩定,程式設計師一般都是認為自己沒問題,有問題的一定是對方 :) ,taobao api那邊給出呼叫資料都是1ms以內就返回了(alimonitor監控圖表)。
於是懷疑從優酷的機器到淘寶的機器中間鏈路上有瓶頸,但是需要設計方案來證明這個問題在鏈路上,要不各個環節都會認為自己沒有問題的,當時Passport的開發也只能拿到Login和Userservice這兩組機器的許可權,中間的負載均衡、交換機都沒有許可權接觸到。
在嘗試過tcpdump抓包、ping等各種手段分析後,設計了場景證明問題在中間鏈路上。
設計如下三個場景證明問題在中間鏈路上:
- 壓測的時候在userservice ping 淘寶的機器;
- 將一臺userservice機器從負載均衡上拿下來(沒有壓力),ping 淘寶的機器;
- 從公網上非優酷的機器 ping 淘寶的機器;
這個時候奇怪的事情發現了,壓力一上來場景1、2的兩臺機器ping淘寶的rt都從30ms上升到100-150ms,場景1 的rt上升可以理解,但是場景2的rt上升不應該,同時場景3中ping淘寶在壓力測試的情況下rt一直很穩定(說明壓力下淘寶的機器沒有問題),到此確認問題在優酷到淘寶機房的鏈路上有瓶頸,而且問題在優酷機房出口扛不住這麼大的壓力。於是從上海Passport的團隊找到北京Passport的PE團隊,確認在優酷呼叫taobao api的出口上使用了snat,PE到snat機器上看到snat只能使用單核,而且對應的核早就100%的CPU了,因為之前一直沒有這麼大的壓力所以這個問題一直存在只是沒有被發現。
於是PE去掉snat,再壓的話 TPS穩定在3000左右
到這裡結束了嗎? 從3000到5400TPS
優化到3000TPS的整個過程沒有修改業務程式碼,只是通過修改系統配置、結構非常有效地把TPS提升了6倍,對於優化來說這個過程是最輕鬆,價效比也是非常高的。實際到這個時候也臨近雙11封網了,最終通過計算(機器數量*單機TPS)完全可以抗住雙11的壓力,所以最終雙11執行的版本就是這樣的。 但是有工匠精神的工程師是不會輕易放過這麼好的優化場景和環境的(基線、機器、程式碼、工具都具備配套好了)
優化完環境問題後,3000TPS能把CPU US跑上去,於是再對業務程式碼進行優化也是可行的了。
進一步挖掘程式碼中的優化空間
雙11前的這段封網其實是比較無聊的,於是和Passport的開發同學們一起挖掘程式碼中的可以優化的部分。這個過程中使用到的主要工具是這三個:火焰圖、perf、perf-map-java。相關連結:http://www.brendangregg.com/perf.html ; https://github.com/jrudolph/perf-map-agent
通過Perf發現的一個SpringMVC 的效能問題
這個問題具體參考我之前發表的優化文章http://www.atatech.org/articles/65232 。 主要是通過火焰圖發現spring mapping path消耗了過多CPU的效能問題,CPU熱點都在methodMapping相關部分,於是修改程式碼去掉spring中的methodMapping解析後效能提升了40%,TPS能從3000提升到4200.
著名的fillInStackTrace導致的效能問題
程式碼中的第二個問題是我們程式中很多異常(fillInStackTrace),實際業務上沒有這麼多錯誤,應該是一些不重要的異常,不會影響結果,但是異常頻率很高,對這種我們可以找到觸發的地方,catch住,然後不要丟擲去(也就是別觸發fillInStackTrace),列印一行error日誌就行,這塊也能省出10%的CPU,對應到TPS也有幾百的提升。
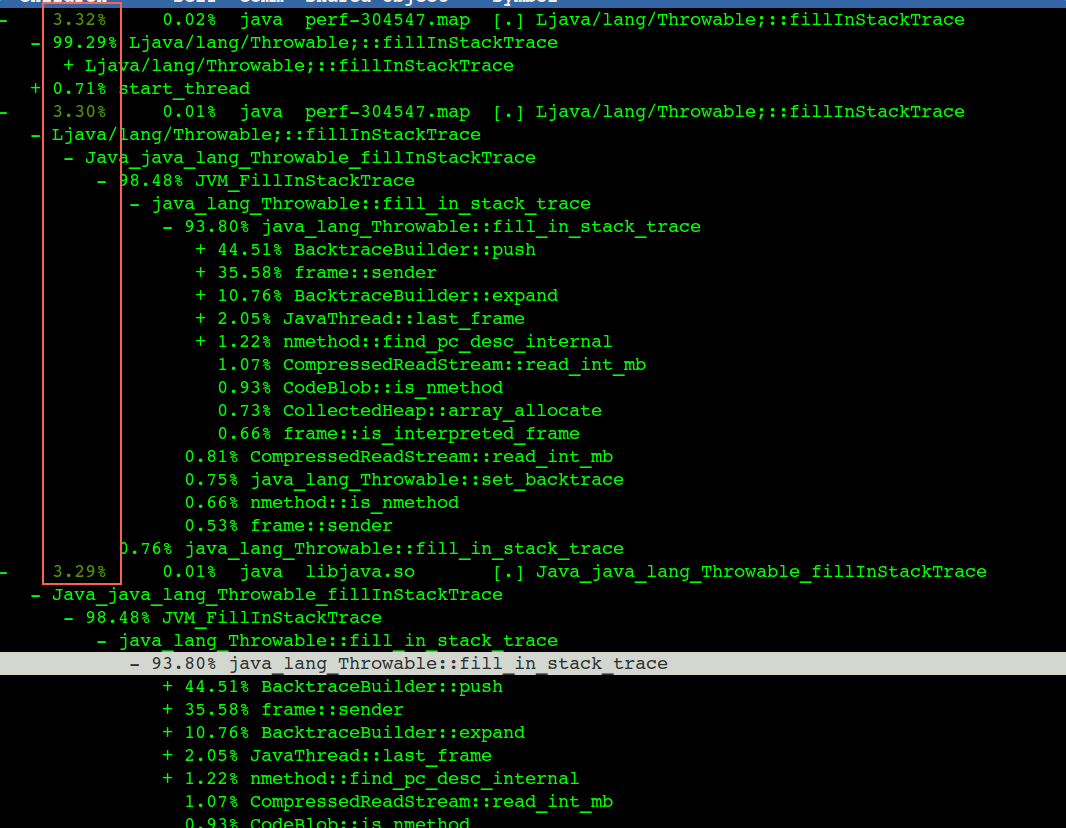
部分觸發fillInStackTrace的場景和具體程式碼行(點選看高清大圖):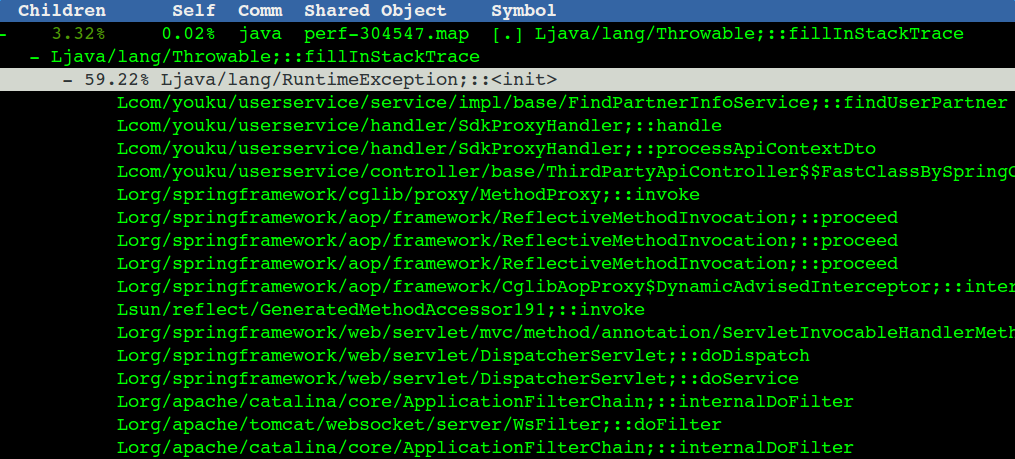
對應的火焰圖(點選看高清大圖):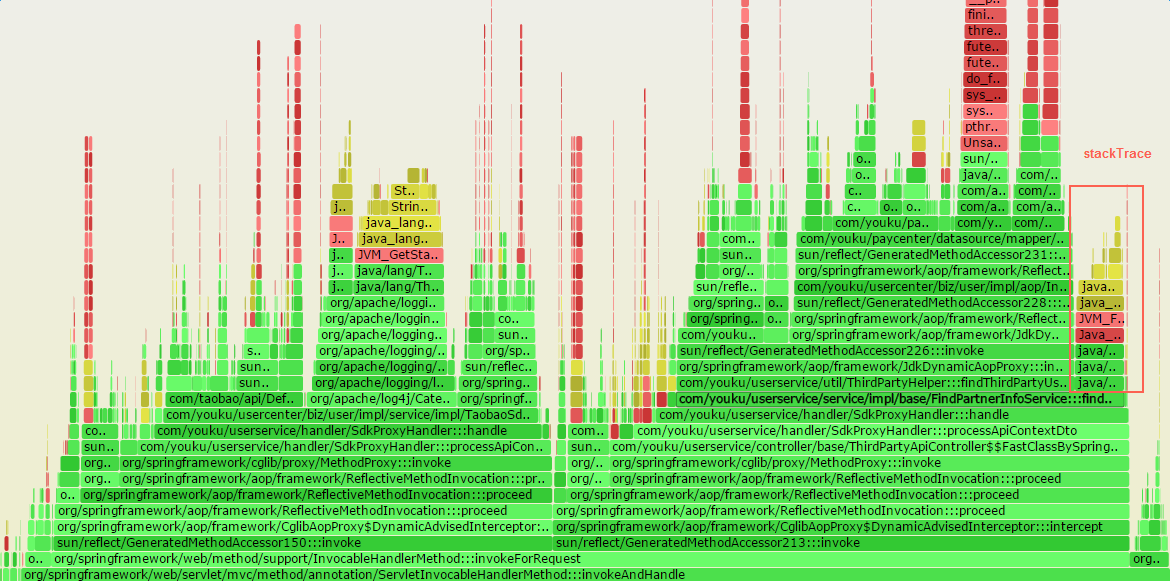

解析useragent 程式碼部分的效能問題
整個useragent呼叫堆疊和cpu佔用情況,做了個彙總(useragent不啟用TPS能從4700提升到5400)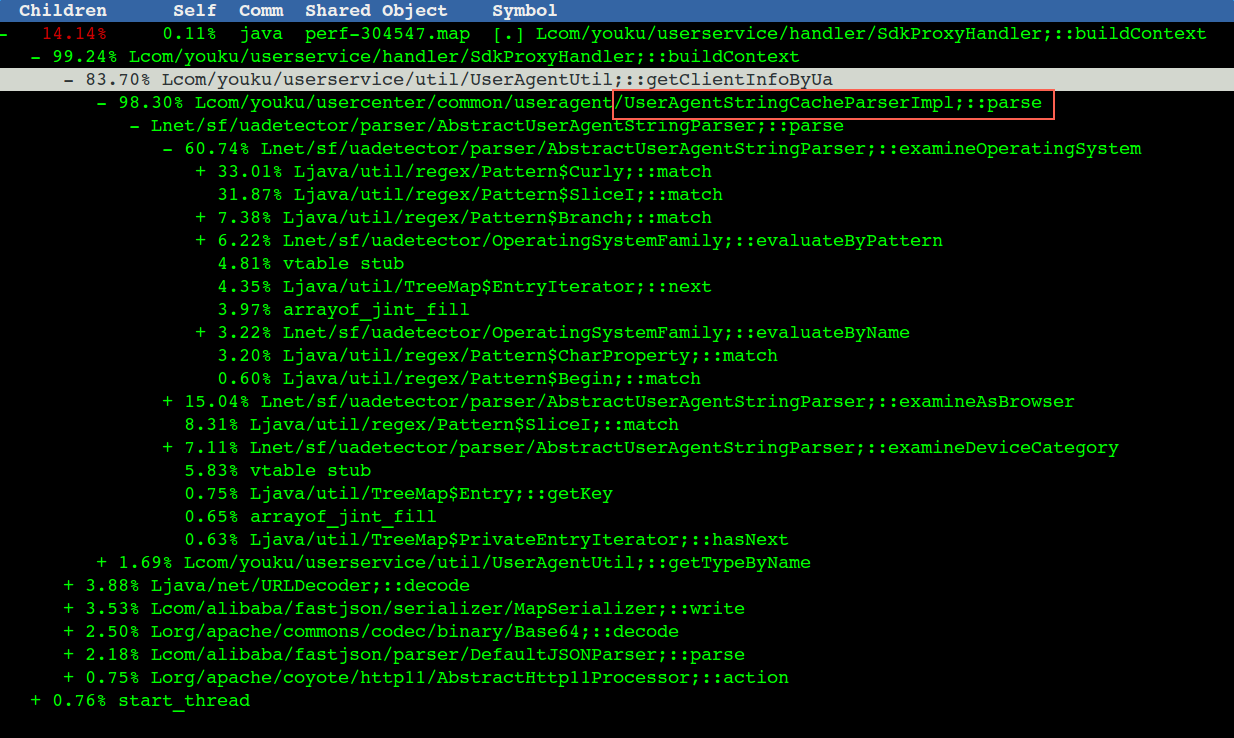
實際火焰圖中比較分散: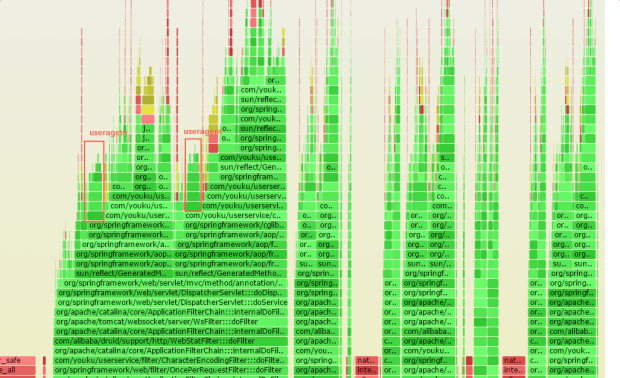
最終通過對程式碼的優化勉勉強強將TPS從3000提升到了5400(太不容易了,改程式碼過程太辛苦,不如改配置來錢快)
優化程式碼後壓測tps可以跑到5400,截圖:

最後再次總結整個壓測過程的問題和優化歷程
- docker bridge網路效能問題和網路中斷si不均衡 (優化後:500->1000TPS)
- 短連線導致的local port不夠 (優化後:1000-3000TPS)
- 生產環境snat單核導致的網路延時增大 (優化後能達到測試環境的3000TPS)
- Spring MVC Path帶來的過高的CPU消耗 (優化後:3000->4200TPS)
- 其他業務程式碼的優化(比如異常、agent等) (優化後:4200->5400TPS)
整個過程得到了淘寶API、優酷會員、優酷Passport、網路、螞蟻等眾多同學的幫助,本來是計劃去上海跟Passport的同學一起復盤然後再寫這篇文章的,結果一直未能成行,請原諒我拖延到現在才把大家一起辛苦工作的結果整理出來,可能過程中的資料會有一些記憶上的小錯誤。