
排名演算法
Delicious 演算法
最直覺、最簡單的演算法,莫過於按照單位時間內使用者的投票數進行排名。得票最多的專案,自然就排在第一位。
例如,舊版的 Delicious,有一個"熱門書籤排行榜",就是這樣統計出來的。它按照"過去 60 分鐘內被收藏的次數"進行排名。每過 60 分鐘,就統計一次。
- 優點
簡單、容易部署、內容更新相當快; - 缺點
排名變化不夠平滑,前一個小時還排在前列的內容,往往第二個小時就一落千丈。
Hacker News 演算法
Hacker News是一個網路社群,可以張貼連結,或者討論某個主題。
每個帖子前面有一個向上的三角形,如果你覺得這個內容很好,就點選一下,投上一票。根據得票數,系統自動統計出熱門文章排行榜。但是,並非得票最多的文章排在第一位,還要考慮時間因素,新文章應該比舊文章更容易得到好的排名。
帖子的分計算公式:
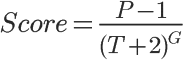
其中,
P表示帖子的得票數,減去1是為了忽略發帖人的投票。
T表示距離發帖的時間(單位為小時),加上2是為了防止最新的帖子導致分母過小(之所以選擇2,可能是因為從原始文章出現在其他網站,到轉貼至Hacker News,平均需要兩個小時)。
G表示"重力因子"(gravityth power),即將帖子排名往下拉的力量,預設值為1.8,後文會詳細討論這個值。
從這個公式來看,決定帖子排名有三個因素:
第一個因素是得票數P。
在其他條件不變的情況下,得票越多,排名越高。
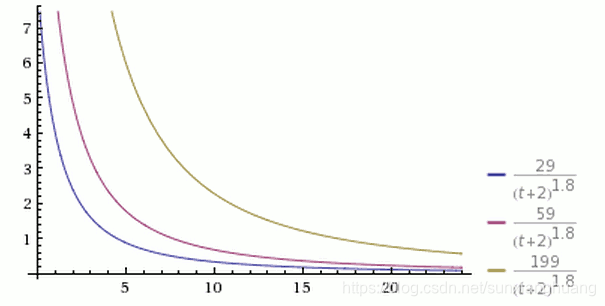
從上圖可以看到,有三個同時發表的帖子,得票分別為200票、60票和30票(減1後為199、59和29),分別以黃色、紫色和藍色表示。在任一個時間點上,都是黃色曲線在最上方,藍色曲線在最下方。
如果你不想讓"高票帖子"與"低票帖子"的差距過大,可以在得票數上加一個小於1的指數,比如(P-1)^0.8。
第二個因素是距離發帖的時間T。
在其他條件不變的情況下,越是新發表的帖子,排名越高。或者說,一個帖子的排名,會隨著時間不斷下降。
從前一張圖可以看到,經過24小時之後,所有帖子的得分基本上都小於1,這意味著它們都將跌到排行榜的末尾,保證了排名前列的都將是較新的內容。
第三個因素是重力因子G。
它的數值大小決定了排名隨時間下降的速度。
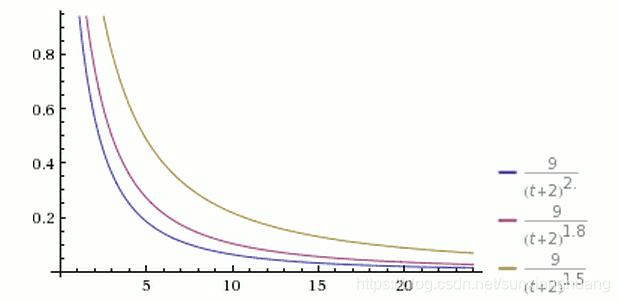
從上圖可以看到,三根曲線的其他引數都一樣,G的值分別為1.5、1.8和2.0。G值越大,曲線越陡峭,排名下降得越快,意味著排行榜的更新速度越快。
知道了演算法的構成,就可以調整引數的值,以適用你自己的應用程式。
參考:https://blog.csdn.net/zhuhengv/article/details/50475685
Reddit 演算法
Python版原始碼排序如下:
#Rewritten code from /r2/r2/lib/db/_sorts.pyx
from datetime import datetime, timedelta
from math import log
epoch = datetime(1970, 1, 1)
def epoch_seconds(date):
"""Returns the number of seconds from the epoch to date."""
td = date - epoch
return td.days * 86400 + td.seconds + (float(td.microseconds) / 1000000)
def score(ups, downs):
return ups - downs
def hot(ups, downs, date):
"""The hot formula. Should match the equivalent function in postgres."""
s = score(ups, downs)
order = log(max(abs(s), 1), 10)
sign = 1 if s > 0 else -1 if s < 0 else 0
seconds = epoch_seconds(date) - 1134028003
return round(order + sign * seconds / 45000, 7)
話題排序演算法的數學描述如下圖:

線性時間收縮&多數投票增長

“踩”的影響
Reddit是少有的有“踩”的網站之一。你可以在程式碼中看到score被定義為:“頂”的票數-“踩”的票數。
“踩”的票數對於得到了很多“頂”和“踩”的話題的得分有著很大的影響。它們的得分比較低僅僅是因為得到了反對票。這可以解釋為什麼Kittens(和其他非爭議性的話題)的排名為何如此之高。:)
信心排序演算法(評論排名)
#Rewritten code from /r2/r2/lib/db/_sorts.pyx
from math import sqrt
def _confidence(ups, downs):
n = ups + downs
if n == 0:
return 0
z = 1.0 #1.0 = 85%, 1.6 = 95%
phat = float(ups) / n
return sqrt(phat+z*z/(2*n)-z*((phat*(1-phat)+z*z/(4*n))/n))/(1+z*z/n)
def confidence(ups, downs):
if ups + downs == 0:
return 0
else:
return _confidence(ups, downs)
信心排序使用了Wilson評分割槽間,數學描述如下:
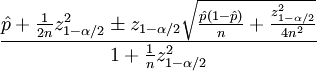
上述公式中的引數定義如下:
- p指的是好評數
- n指的是投票總數
- zα/2 是(1-α/ 2)標準正態分佈分量
總結一下就是:
- 信心排序將投票看作是大家表決的統計抽樣計票
- 信心排序用85%的置信度來確定評論的排名
投票越多,85%置信度下的評論的信心分數越接近真實分數
威爾遜區間對於小樣本或者極端情況也具有良好作用
Randall 在他部落格文章《信心排序是如何進行評論排序的》中舉了一個很好的例子:
如果一個評論有1票“頂”,0票“踩”,那麼它的“頂”就為100%,由於樣本資料太少,系統將會將它排在底部。
但是如果它有10個“頂”而只有1個“踩”的話,系統就可以有足夠的信心判定它應該排在那些有40個“頂”但是也有20個“踩”的評論(如果這個時候它得到了40個“頂”,那麼幾乎可以肯定它得到的“踩”小於20個)的前面。更好的是如果判斷錯誤(15%的概率),它很快會得到更多的資料,因此,資料少的評論出現在了頂部。
提交時間對評論排序沒有影響
提交時間對於信心排序演算法來說是無關緊要的(這一點和熱排序演算法還有Hacker 新聞排序演算法不同)。 評論排名靠的是信心分數和資料取樣——也就是說的到的票數越多,信心分數也就越精確。
觀察
我們用Randall的例子來觀察一下信心排序是如何對評論進行排序的:

從上圖你可以看到信心排序根本就不關心一個評論得到了多少票數,它關心的是“頂”的票數和總票數的比值。
內容源自:
https://www.oschina.net/translate/how-reddit-ranking-algorithms-work?print
http://amix.dk/blog/post/19588#How-Reddit-ranking-algorithms-work