
初識Tensorflow,基本概念及簡單示例
一、前言
目前,深度學習已經廣泛應用於各個領域,比如影象識別,圖形定位與檢測,語音識別,機器翻譯等等,對於這個神奇的領域,很多童鞋想要一探究竟,這裡拋磚引玉的簡單介紹下最火的深度學習開源框架 tensorflow。本教程不是 cookbook,所以不會將所有的東西都事無鉅細的講到,所有的示例都將使用 Python。
那麼本篇教程會講到什麼?首先是一些基礎概念,包括計算圖,graph
與 session,基礎資料結構,Variable,placeholder 與 feed_dict 以及使用它們時需要注意的點。最後給出了在 tensorflow 中建立一個機器學習模型步驟,並用一個手寫數字識別的例子進行演示。
1、 tensorflow是什麼?
tensorflow 是 google 開源的機器學習工具,在2015年11月其實現正式開源,開源協議Apache 2.0。
下圖是 query 詞頻時序圖,從中可以看出 tensorflow 的火爆程度。
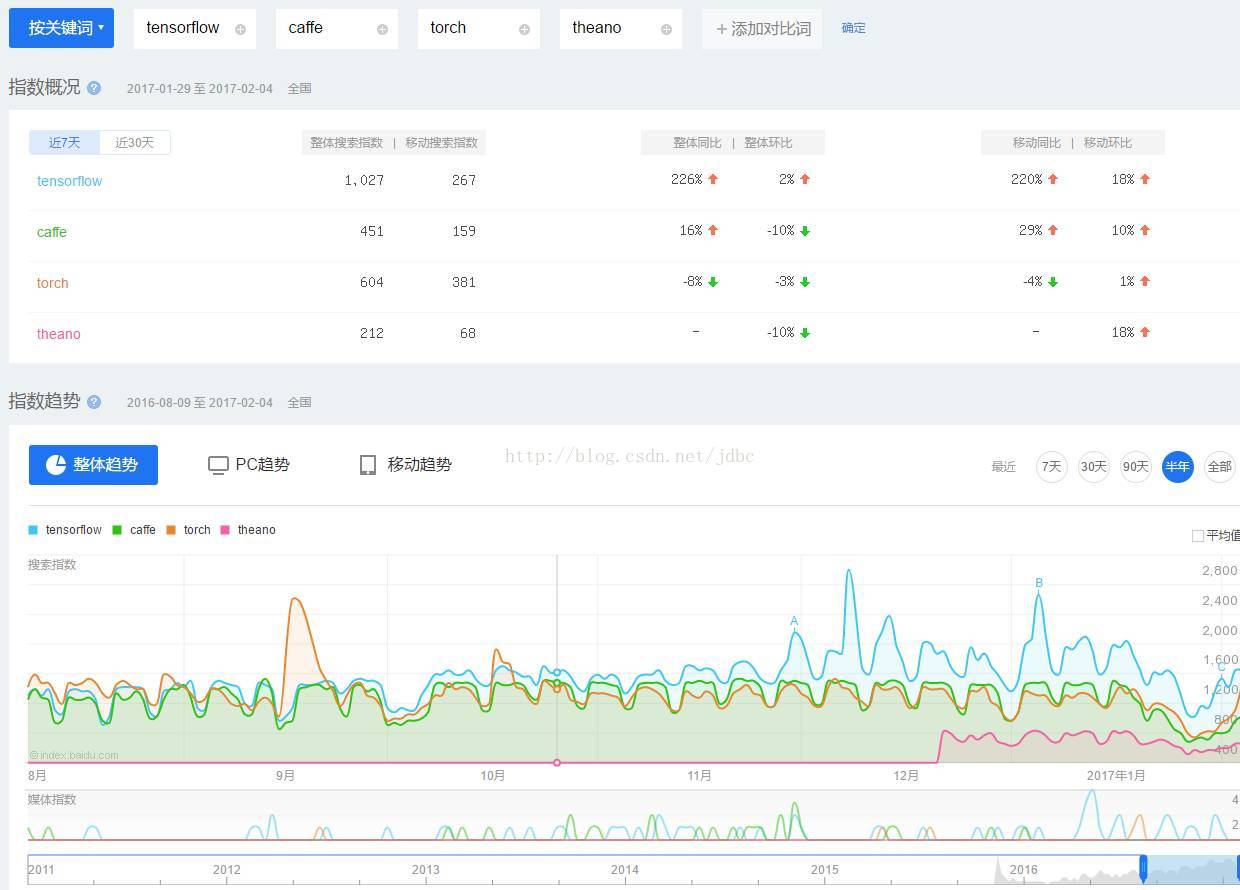
2、 why tensorflow?
Tensorflow
擁有易用的 python 介面,而且可以部署在一臺或多臺 cpu , gpu 上,相容多個平臺,包括但不限於 安卓/windows/linux 等等平臺上,而且擁有 tensorboard這種視覺化工具,可以使用 checkpoint 進行實驗管理,得益於圖計算,它可以進行自動微分計算,擁有龐大的社群,而且很多優秀的專案已經使用 tensorflow 進行開發了。
3、 易用的tensorflow工具
如果不想去研究 tensorflow 繁雜的API,僅想快速的實現些什麼,可以使用其他高層工具。比如 tf.contrib.learn,tf.contrib.slim,Keras 等,它們都提供了高層封裝。這裡是 tflearn 的github樣例集。
4、 tensorflow安裝
目前 tensorflow 的安裝已經十分方便,有興趣可以參考官方文件。
二、 tensorflow基礎
實際上編寫tensorflow可以總結為兩步.
(1)組裝一個graph;
(2)使用session去執行graph中的operation。
因此我們從 graph 與 session 說起。
1、 graph與session
(1)計算圖
Tensorflow 是基於計算圖的框架,因此理解 graph 與 session 顯得尤為重要。不過在講解 graph 與 session 之前首先介紹下什麼是計算圖。假設我們有這樣一個需要計算的表示式。該表示式包括了兩個加法與一個乘法,為了更好講述引入中間變數c與d。由此該表示式可以表示為:
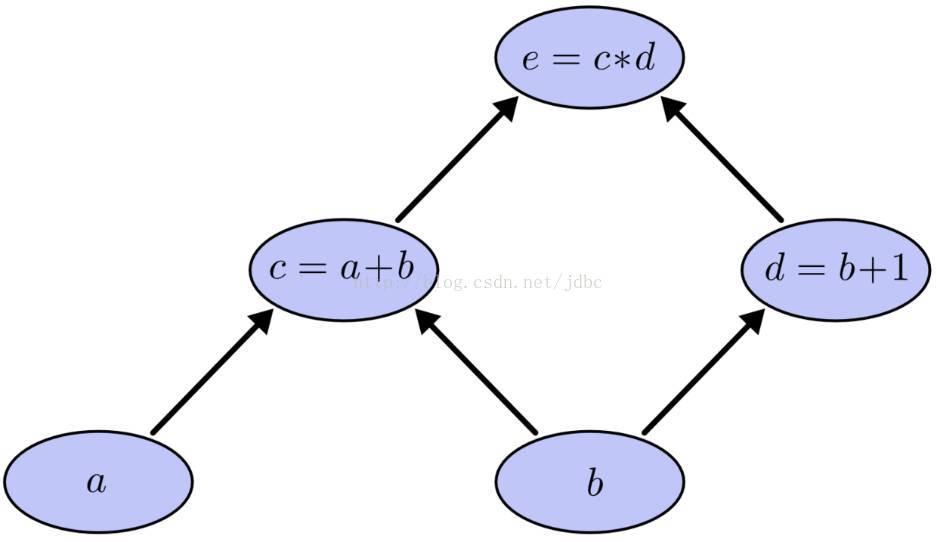
當需要計算e時就需要計算c與d,而計算c就需要計算a與b,計算d需要計算b。這樣就形成了依賴關係。這種有向無環圖就叫做計算圖,因為對於圖中的每一個節點其微分都很容易得出,因此應用鏈式法則求得一個複雜的表示式的導數就成為可能,所以它會應用在類似tensorflow這種需要應用反向傳播演算法的框架中。
(2)概念說明
下面是 graph , session , operation , tensor 四個概念的簡介。
Tensor:型別化的多維陣列,圖的邊;
Operation:執行計算的單元,圖的節點;
Graph:一張有邊與點的圖,其表示了需要進行計算的任務;
Session:稱之為會話的上下文,用於執行圖。
Graph僅僅定義了所有 operation 與 tensor 流向,沒有進行任何計算。而session根據 graph 的定義分配資源,計算 operation,得出結果。既然是圖就會有點與邊,在圖計算中 operation 就是點而 tensor 就是邊。Operation 可以是加減乘除等數學運算,也可以是各種各樣的優化演算法。每個 operation 都會有零個或多個輸入,零個或多個輸出。 tensor 就是其輸入與輸出,其可以表示一維二維多維向量或者常量。而且除了Variables指向的 tensor 外所有的 tensor 在流入下一個節點後都不再儲存。
(3)舉例
下面首先定義一個圖(其實沒有必要,tensorflow會預設定義一個),並做一些計算。
[python] view plain copy print?- import tensorflow as tf
- graph = tf.Graph()
- with graph.as_default():
- foo = tf.Variable(3,name=‘foo’)
- bar = tf.Variable(2,name=‘bar’)
- result = foo + bar
- initialize = tf.global_variables_initializer()
- print(result) #Tensor(“add:0”, shape=(), dtype=int32)
import tensorflow as tf
graph = tf.Graph()
with graph.as_default():
foo = tf.Variable(3,name='foo')
bar = tf.Variable(2,name='bar')
result = foo + bar
initialize = tf.global_variables_initializer()
print(result) #Tensor("add:0", shape=(), dtype=int32)這段程式碼,首先會載入tensorflow,定義一個graph類,並在這張圖上定義了foo與bar的兩個變數,最後對這個值求和,並初始化所有變數。其中,Variable是定義變數並賦予初值。讓我們看下result(最後1行程式碼)。後面是輸出,可以看到並沒有輸出實際的結果,由此可見在定義圖的時候其實沒有進行任何實際的計算。
[python] view plain copy print?- print(result) #Tensor(“add:0”, shape=(), dtype=int32)
print(result) #Tensor("add:0", shape=(), dtype=int32)- with tf.Session(graph=graph) as sess:
- sess.run(initialize)
- res = sess.run(result)
- print(res) # 5
with tf.Session(graph=graph) as sess:
sess.run(initialize)
res = sess.run(result)
print(res) # 5
這段程式碼中,定義了session,並在session中執行了真正的初始化,並且求得result的值並打印出來。可以看到,在session中產生了真正的計算,得出值為5。
下圖是該graph在tensorboard中的顯示。這張圖整體是一個graph,其中foo,bar,add這些節點都是operation,而foo和bar與add連線邊的就是tensor。當session執行result時,實際就是求得add這個operation流出的tensor值,那麼add的所有上游節點都會進行計算,如果圖中有非add上游節點(本例中沒有)那麼該節點將不會進行計算,這也是圖計算的優勢之一。

2、資料結構
Tensorflow的資料結構有著rank,shape,data types的概念,下面來分別講解。
(1)rank
Rank一般是指資料的維度,其與線性代數中的rank不是一個概念。其常用rank舉例如下。

(2)shape
Shape指tensor每個維度資料的個數,可以用python的list/tuple表示。下圖表示了rank,shape的關係。

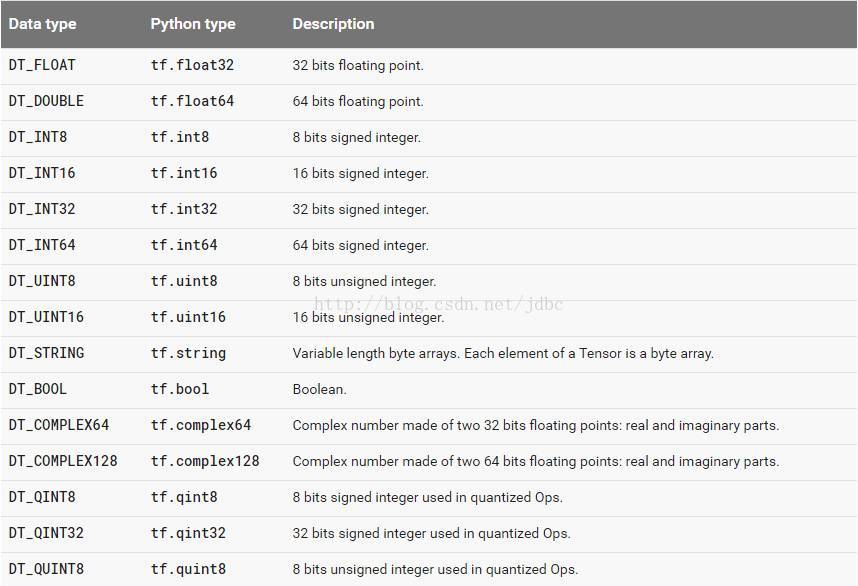
(3)data type
Data type,是指單個數據的型別。常用DT_FLOAT,也就是32位的浮點數。下圖表示了所有的types。
3、 Variables
(1)介紹
當訓練模型時,需要使用Variables儲存與更新引數。Variables會儲存在記憶體當中,所有tensor一旦擁有Variables的指向就不會在session中丟失。其必須明確的初始化而且可以通過Saver儲存到磁碟上。Variables可以通過Variables初始化。
[python] view plain copy print?- weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),name=“weights”)
- biases = tf.Variable(tf.zeros([200]), name=“biases”)
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),name="weights")
biases = tf.Variable(tf.zeros([200]), name="biases")其中,tf.random_normal是隨機生成一個正態分佈的tensor,其shape是第一個引數,stddev是其標準差。tf.zeros是生成一個全零的tensor。之後將這個tensor的值賦值給Variable。
(2)初始化
實際在其初始化過程中做了很多的操作,比如初始化空間,賦初值(等價於tf.assign),並把Variable新增到graph中等操作。注意在計算前需要初始化所有的Variable。一般會在定義graph時定義global_variables_initializer,其會在session運算時初始化所有變數。
直接呼叫global_variables_initializer會初始化所有的Variable,如果僅想初始化部分Variable可以呼叫tf.variables_initializer。
[python] view plain copy print?- Init_ab = tf.variables_initializer([a,b],name=”init_ab”)
Init_ab = tf.variables_initializer([a,b],name=”init_ab”)(3)Variables與constant的區別
值得注意的是Variables與constant的區別。Constant一般是常量,可以被賦值給Variables,constant儲存在graph中,如果graph重複載入那麼constant也會重複載入,其非常浪費資源,如非必要儘量不使用其儲存大量資料。而Variables在每個session中都是單獨儲存的,甚至可以單獨存在一個引數伺服器上。可以通過程式碼觀察到constant實際是儲存在graph中,具體如下。
[python] view plain copy print?- const = tf.constant(1.0,name=“constant”)
- print(tf.get_default_graph().as_graph_def())
const = tf.constant(1.0,name="constant")
print(tf.get_default_graph().as_graph_def())- node {
- name: ”constant”
- op: ”Const”
- attr {
- key: ”dtype”
- value {
- type: DT_FLOAT
- }
- }
- attr {
- key: ”value”
- value {
- tensor {
- dtype: DT_FLOAT
- tensor_shape {
- }
- float_val: 1.0
- }
- }
- }
- }
- versions {
- producer: 17
- }
node {
name: "constant"
op: "Const"
attr {
key: "dtype"
value {
type: DT_FLOAT
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_FLOAT
tensor_shape {
}
float_val: 1.0
}
}
}
}
versions {
producer: 17
}(4)命名
另外一個值得注意的地方是儘量每一個變數都明確的命名,這樣易於管理命令空間,而且在匯入模型的時候不會造成不同模型之間的命名衝突,這樣就可以在一張graph中容納很多個模型。
4、 placeholders與feed_dict
當我們定義一張graph時,有時候並不知道需要計算的值,比如模型的輸入資料,其只有在訓練與預測時才會有值。這時就需要placeholder與feed_dict的幫助。
定義一個placeholder,可以使用tf.placeholder(dtype,shape=None,name=None)函式。
[python] view plain copy print?- foo = tf.placeholder(tf.int32,shape=[1],name=‘foo’)
- bar = tf.constant(2,name=‘bar’)
- result = foo + bar
- with tf.Session() as sess:
- print(sess.run(result))
foo = tf.placeholder(tf.int32,shape=[1],name='foo')
bar = tf.constant(2,name='bar')
result = foo + bar
with tf.Session() as sess:
print(sess.run(result)) - print(sess.run(result,{foo:[3]}))
print(sess.run(result,{foo:[3]}))三、mnist識別例項
介紹了一些tensorflow基礎後,我們用一個完整的例子將這些串起來。
首先,需要下載資料集,mnist資料可以在Yann LeCun’s website下載到,也可以通過如下兩行程式碼得到。
[python] view plain copy print?- from tensorflow.examples.tutorials.mnist import input_data
- mnist = input_data.read_data_sets(”MNIST_data/”, one_hot=True)
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
整體的X可以表示為:
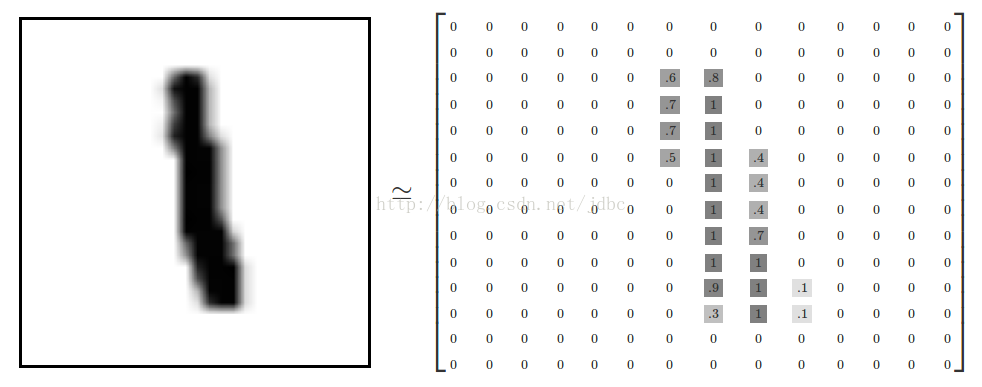
y為X真實的類別,其資料可以看做如下圖的形式。因此,問題可以看成一個10分類的問題:


而本次演示所使用的模型為邏輯迴歸,其可以表示為:

用圖形可以表示為下圖,具體原理這裡不再闡述,更多細節參考該連結。
那麼 let’s coding!
當使用tensorflow進行graph構建時,大體可以分為五部分:
1、為輸入X與輸出y定義placeholder;
2、定義權重W;
3、定義模型結構;
4、定義損失函式;
5、定義優化演算法。
首先匯入需要的包,定義X與y的placeholder以及 W,b 的 Variables。其中None表示任意維度,一般是min-batch的 batch size。而 W 定義是 shape 為784,10,rank為2的Variable,b是shape為10,rank為1的Variable。
[python] view plain copy print?- import tensorflow as tf
- x = tf.placeholder(tf.float32, [None, 784])
- y_ = tf.placeholder(tf.float32, [None, 10])
- W = tf.Variable(tf.zeros([784, 10]))
- b = tf.Variable(tf.zeros([10]))
import tensorflow as tf
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
之後是定義模型。x與W矩陣乘法後與b求和,經過softmax得到y。
[python] view plain copy print?- y = tf.nn.softmax(tf.matmul(x, W) + b)
y = tf.nn.softmax(tf.matmul(x, W) + b)求邏輯迴歸的損失函式,這裡使用了cross entropy,其公式可以表示為:
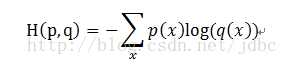
這裡的 cross entropy 取了均值。定義了學習步長為0.5,使用了梯度下降演算法(GradientDescentOptimizer)最小化損失函式。不要忘記初始化 Variables。
[python] view plain copy print?- cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y),reduction_indices=[1]))
- train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
- init = tf.global_variables_initializer()
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y),reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
init = tf.global_variables_initializer()- with tf.Session() as sess:
- sess.run(init)
- for i in range(1000):
- batch_xs, batch_ys = mnist.train.next_batch(100)
- sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
with tf.Session() as sess:
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})- correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
- accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
- print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))至此,我們開發了一個簡單的手寫數字識別模型。
總結全文,我們首先介紹了 graph 與 session,並解釋了基礎資料結構,講解了一些Variable需要注意的地方並介紹了 placeholders 與 feed_dict 。最終以一個手寫數字識別的例項將這些點串起來,希望可以給想要入門的你一丟丟的幫助。
引用自:Qunar技術沙