
Mahout系列之推薦演算法-基於物品協同過濾實踐
上文已經說明了使用者的協同過濾,這篇也來談談基於物品的協同過濾。
2.基於物品的協同過濾
類似的,也很容易做出一個簡單的基於物品的過濾方法。
1. 單機基本演算法實踐
public static void ItemBased() {
try {
//DataModel model = new FileDataModel(new File("data/dataset.csv"));
DataModel model = new FileDataModel(new File("D:/tmp/recommandtestdata.csv"));
ItemSimilarity similarity = new PearsonCorrelationSimilarity(model);
ItemBasedRecommender recommender = new GenericItemBasedRecommender(model, similarity);
List<RecommendedItem> recommendations = recommender.recommend(2, 3);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
} catch (Exception e) {
e.printStackTrace();
}
}
一樣可以採用上篇的資料,單機可以達到幾百M,執行結果類似這樣:
INFO - Creating FileDataModel for file D:\tmp\recommandtestdata.csv
INFO - Reading file info...
INFO - Processed 1000000 lines
。。。。。。(此處省略)
INFO - Processed 5000000 lines
INFO - Read lines: 5990001
INFO - Reading file info...
INFO - Processed 1000000 lines
INFO - Processed 2000000 lines
。。。。。。(此處省略)
INFO - Processed 999999 users
DEBUG - Recommending items for user ID '2'
DEBUG - Recommendations are: [RecommendedItem[item:7, value:4.0], RecommendedItem[item:5, value:4.0], RecommendedItem[item:3, value:4.0]]
RecommendedItem[item:7, value:4.0]
RecommendedItem[item:5, value:4.0]
RecommendedItem[item:3, value:4.0]
2. 分散式基於物品協同過濾實踐
如果是到Hadoop上會怎麼樣呢?我們可以搞些百萬級別的資料來試試。
用上面的方法生成資料,上傳到HDFS。我上傳到目錄/user/hadoop/recommend。注意配置MAHOUT_CONF_DIR和HADOOP_CONF_DIR
export MAHOUT_HOME=/home/hadoop/mahout-0.11.0
export MAHOUT_CONF_DIR=$MAHOUT_HOME/conf
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
PATH=$PATH:$HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HBASE_HOME/bin:$SQOOP_HOME/bin:$SPARK_HOME/bin:$MAHOUT_HOME/bin
export PATH
下面就直接運行了。
$ mahout recommenditembased -s SIMILARITY_LOGLIKELIHOOD -i /user/hadoop/recommend/recommandtestdata.csv -o /user/hadoop/recommend/result --numRecommendations 25
通過-i -o指定輸入輸出
一般會遇到下面的錯誤:
1 , Error: Java heap space
可以修改hadoop-2.7.1/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx1024M</value>
</property>
我做的時候scp到其他的所有節點
然後執行 hadoop dfsadmin -refreshNodes 通知節點配置更改,這樣就不用重啟叢集。
2,再次執行會報這樣的錯誤:
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory temp/preparePreferenceMatrix/itemIDIndex already exists
很簡單,執行 hadoop fs -rm -r temp 刪除這些目錄,這個temp是當前使用者的目錄
列印的結果類似這樣:
MAHOUT_LOCAL is not set; adding HADOOP_CONF_DIR to classpath.
Running on hadoop, using /home/hadoop/hadoop-2.7.1/bin/hadoop and HADOOP_CONF_DIR=/home/hadoop/hadoop-2.7.1/etc/hadoop
MAHOUT-JOB: /home/hadoop/mahout-0.11.0/mahout-examples-0.11.0-job.jar
。。。。。。
File Input Format Counters
Bytes Read=42435633
File Output Format Counters
Bytes Written=293110942
16/02/02 11:34:26 INFO MahoutDriver: Program took 2043686 ms (Minutes: 34.06143333333333)
最後執行的時間為34分鐘,呵呵,我是3個虛擬機器節點上執行的,user-item資料為600萬,100萬用戶ID,1000物品ID,檔案大小約為75M。
執行之後生成的結果檔案類似這樣:
[[email protected] ~]$ hadoop fs -tail /user/hadoop/recommend/result/part-r-00000
[944:3.5948825,665:3.503863,865:3.503816,489:3.5037806,645:3.503364,650:3.5012658,852:3.5012386,726:3.5012195,492:3.5012083,587:3.501197,800:3.5011563,153:3.5011272,526:3.5003066,863:3.4079022,884:3.4075432,465:3.3355443,100:3.3355238,89:3.2901146,655:3.1999612,530:3.1868088,938:3.1864436,26:3.1838968,631:3.170042,179:3.1388438,227:3.0067925]
999998 [935:2.0,242:2.0,686:2.0,606:2.0,931:2.0,620:2.0,135:2.0,253:2.0,285:2.0,612:2.0,397:2.0,260:2.0,243:2.0,179:2.0,328:2.0,569:1.7594754,67:1.7054411,852:1.6788439,563:1.6779507,570:1.6773306,792:1.6763401,594:1.6762494,87:1.6685698,800:1.6669749,158:1.6668898]
999999 [519:4.0,422:4.0,297:4.0,586:4.0,193:4.0,15:4.0,650:4.0,179:4.0,431:4.0,576:4.0,312:3.1151164,236:2.9857903,811:2.9856594,489:2.9852173,367:2.9850829,820:2.7635565,944:2.7610388,648:2.7313619,423:2.4961493,425:2.495597,716:2.4862907,50:2.4861178,901:2.4855912,362:2.4855912,983:2.4853737]
檔案的格式是這樣的:
UserID [ItemID1:score1,ItemID2:score2......] 這個userID是按順序的,score也是按照從高到低排序的。
成功執行完了,還沒有完事,我們可以去看看mapreduce執行的過程。
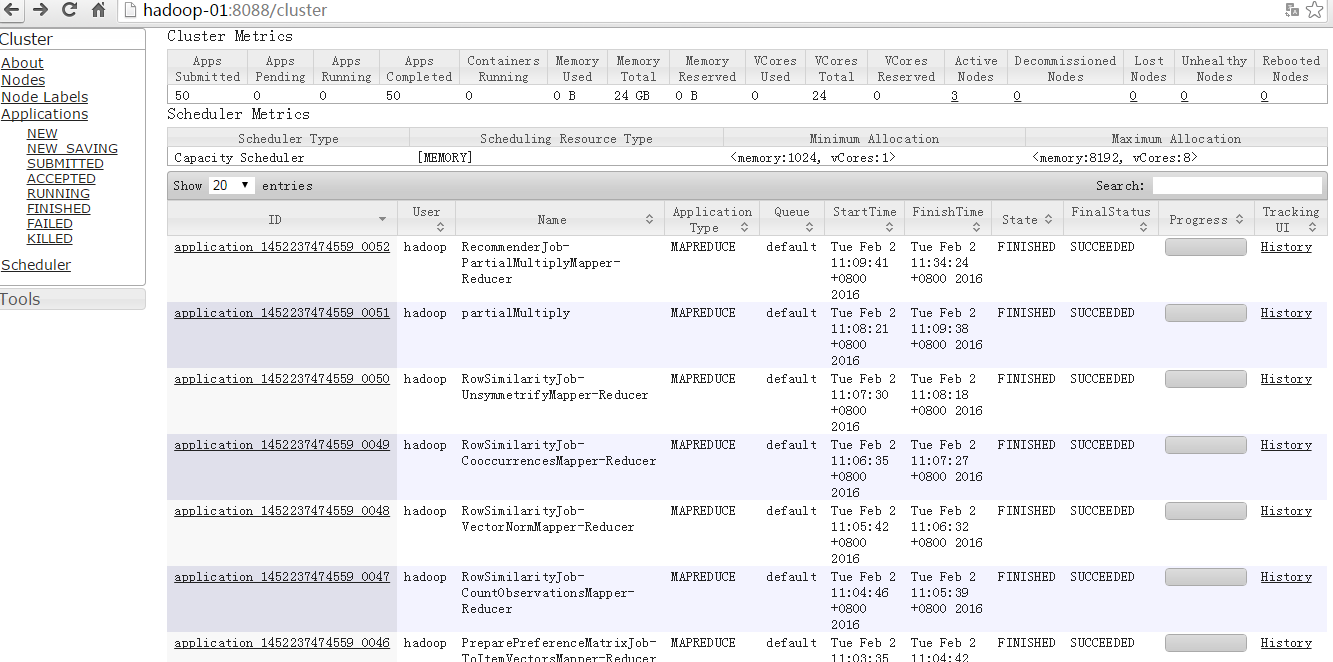
還是有不少的mapreduce過程,有時間在具體分析下里面的過程。