
爬蟲出現403錯誤解決辦法
阿新 • • 發佈:2019-01-06
轉載自https://blog.csdn.net/jsqfengbao/article/details/44594985
在python寫爬蟲的時候,html.getcode()會遇到403禁止訪問的問題,這是網站對自動化爬蟲的禁止,要解決這個問題,需要用到python的模組urllib2模組
urllib2模組是屬於一個進階的爬蟲抓取模組,有非常多的方法
比方說連線url=http://blog.csdn.net/qysh123
對於這個連線就有可能出現403禁止訪問的問題
解決這個問題,需要以下幾步驟:
- <span style="font-size:18px;">req = urllib2.Request(url)
- req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36")
- req.add_header("GET",url)
- req.add_header("Host","blog.csdn.net")
- req.add_header("Referer","http://blog.csdn.net/")</span>
其中User-Agent是瀏覽器特有的屬性,通過瀏覽器檢視原始碼就可以檢視到
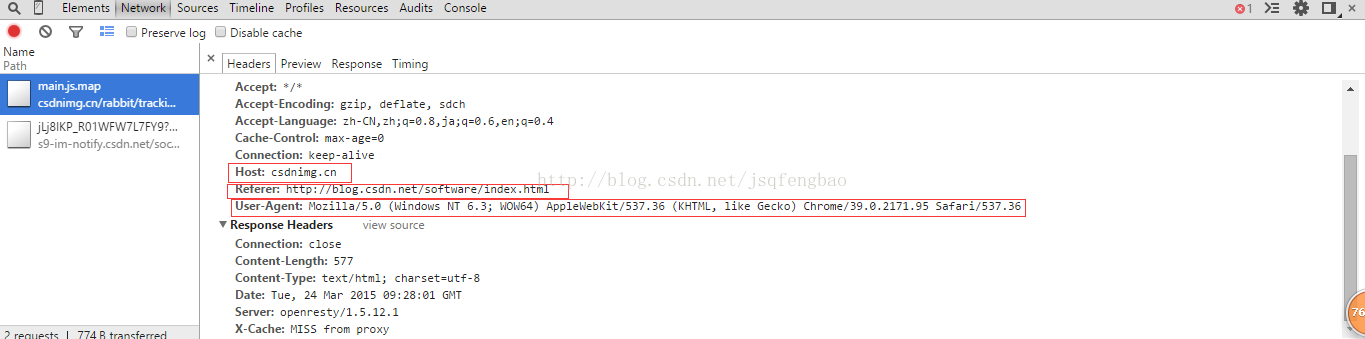
然後html=urllib2.urlopen(req)
print html.read()
就可以把網頁程式碼全部下載下來,而沒有了403禁止訪問的問題。
對於以上問題,可以封裝成函式,供以後呼叫方便使用,具體程式碼:
- #-*-coding:utf-8-*-
- import urllib2
- import random
- url="http://blog.csdn.net/qysh123/article/details/44564943"
- my_headers=["Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
- "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
- "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0"
- "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
- "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)"
- ]
- def get_content(url,headers):
- '''''
- @獲取403禁止訪問的網頁
- '''
- randdom_header=random.choice(headers)
- req=urllib2.Request(url)
- req.add_header("User-Agent",randdom_header)
- req.add_header("Host","blog.csdn.net")
- req.add_header("Referer","http://blog.csdn.net/")
- req.add_header("GET",url)
- content=urllib2.urlopen(req).read()
- return content
- print get_content(url,my_headers)
其中用到了random隨機函式,自動獲取已經寫好的瀏覽器型別的User-Agent資訊,在自定義函式中需要寫出自己的Host,Referer,GET資訊等,解決這幾個問題,就可以順利訪問了,不再出現403訪問的資訊。
當然如果訪問頻率過快的話,有些網站還是會過濾的,解決這個需要用到代理IP的方法。。。具體的自己解決