
Caffe學習筆記(七):使用訓練好的model做預測(mnist)
一、前言
在之前的筆記中,已經生成了訓練好的mnist.cafffemodel,接下來我們就可以利用這個model做預測了。在這之前,我們還需要一個檔案:deploy.prototxt。那麼,就讓我們從deploy.prototxt開始說起。
二、deploy.prototxt
deploy.prototxt檔案和train.prototxt相似,區別在於第一層的輸入資料層被刪除,然後新增一個數據維度的描述。同時,移除了最後的”loss”和”accurary”層,加入”prob”層,也就是一個Softmax概率層。
1.第一層資料維度描述如下:
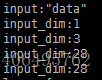
input:”data” 對輸入資料維度進行描述;
input_dim:1 表示對待識別樣本進行資料增廣的數量,該值的大小可自行定義。但一般會進行5次crop,將整幅影象分為多個flip。該值為10則表示會將待識別的樣本分為10部分輸入到網路進行識別。如果相對整幅影象進行識別而不進行影象資料增廣,則可將該值設定為1;
input_dim:3 該值表示處理的影象的通道數,若影象為RGB影象則通道數為3,設定該值為3;若影象為灰度圖,通道數為1則設定該值為1;
input_dim:28 影象的長度,可以通過網路配置檔案中的資料層中的crop_size來獲取;
input_dim:28 影象的寬度,可以通過網路配置檔案中的資料層中的crop_size來獲取。
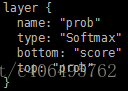
2.最後一層”prob”層:
3.編寫程式碼:
# -*- coding: UTF-8 -*-
import caffe
def creat_deploy():
net = caffe.NetSpec()
net.conv1 = caffe.layers.Convolution(bottom = 'data', kernel_size = 5, num_output = 20,
weight_filler = dict(type = 'xavier'))
net.pool1 = caffe.layers.Pooling(net.conv1, kernel_size = 2 4.deploy.prototxt生成的內容如下:
input:"data"
input_dim:1
input_dim:3
input_dim:28
input_dim:28
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 20
kernel_size: 5
weight_filler {
type: "xavier"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
convolution_param {
num_output: 50
kernel_size: 5
weight_filler {
type: "xavier"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fc1"
type: "InnerProduct"
bottom: "pool2"
top: "fc1"
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "fc1"
top: "fc1"
}
layer {
name: "score"
type: "InnerProduct"
bottom: "fc1"
top: "score"
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "score"
top: "prob"
}
三、預測
執行上述程式碼,就可在my-caffe-project/mnist目錄下生成deploy.prototxt檔案,生成的deploy.prototxt檔案即可用於使用訓練好的模型做預測,如下圖所示:

上個筆記中訓練生成的模型在my-caffe-project目錄下,如下圖所示:
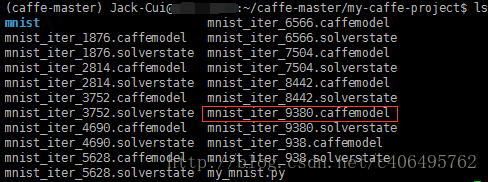
現在就可以使用deploy.prototxt和mnist_iter_9380.caffemodel做預測了,編寫程式碼如下:
# -*- coding: UTF-8 -*-
import caffe
import numpy as np
def test(my_project_root, deploy_proto):
caffe_model = my_project_root + 'mnist_iter_9380.caffemodel' #caffe_model檔案的位置
img = my_project_root + 'mnist/test/6/09269.png' #隨機找的一張待測圖片
labels_filename = my_project_root + 'mnist/test/labels.txt' #類別名稱檔案,將數字標籤轉換回類別名稱
net = caffe.Net(deploy_proto, caffe_model, caffe.TEST) #載入model和deploy
#圖片預處理設定
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape}) #設定圖片的shape格式(1,3,28,28)
transformer.set_transpose('data', (2,0,1)) #改變維度的順序,由原始圖片(28,28,3)變為(3,28,28)
transformer.set_raw_scale('data', 255) # 縮放到【0,255】之間
transformer.set_channel_swap('data', (2,1,0)) #交換通道,將圖片由RGB變為BGR
im = caffe.io.load_image(img) #載入圖片
net.blobs['data'].data[...] = transformer.preprocess('data',im) #執行上面設定的圖片預處理操作,並將圖片載入到blob中
out = net.forward() #執行測試
labels = np.loadtxt(labels_filename, str, delimiter='\t') #讀取類別名稱檔案
prob = net.blobs['prob'].data[0].flatten() #取出最後一層(Softmax)屬於某個類別的概率值
order = prob.argsort()[-1] #將概率值排序,取出最大值所在的序號
print '圖片數字為:',labels[order] #將該序號轉換成對應的類別名稱,並列印
if __name__ == '__main__':
my_project_root = "/home/Jack-Cui/caffe-master/my-caffe-project/" #my-caffe-project目錄
deploy_proto = my_project_root + "mnist/deploy.prototxt" #儲存deploy.prototxt檔案的位置
test(my_project_root, deploy_proto)
執行結果如下:
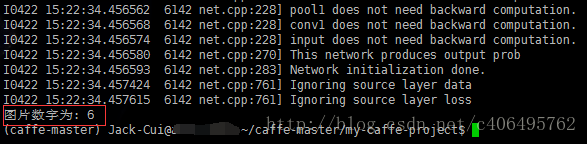
可以看到結果正確無誤,我隨機選取的待測圖片就是數字6(mnist/test/6/09269.png)。