
常用優化方法總結
本篇博文總結一些常用的優化演算法。
梯度下降法
最常見的優化方法是
從泰勒公式的角度來看,梯度下降法將
1. 當學習率太小,到達最優點會很慢。
2. 當學習率太高,可能會跳過最優點,出現震盪的現象。
3. 可能會陷入區域性最優。
3. 如果輸入樣本的不同特徵的大小差別很大,

牛頓法
牛頓法用於方程求解(也稱切線法)
對
此時,將非線性方程
若
在多元函式中,
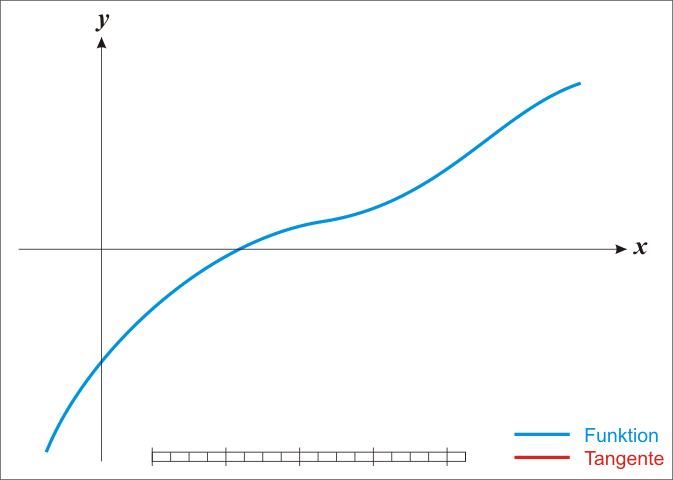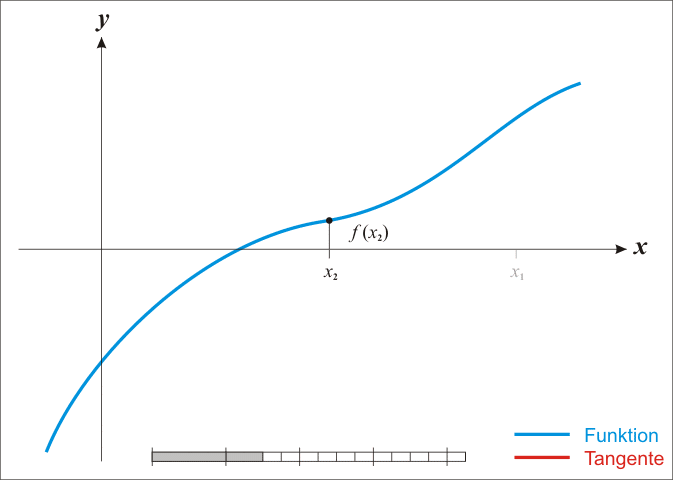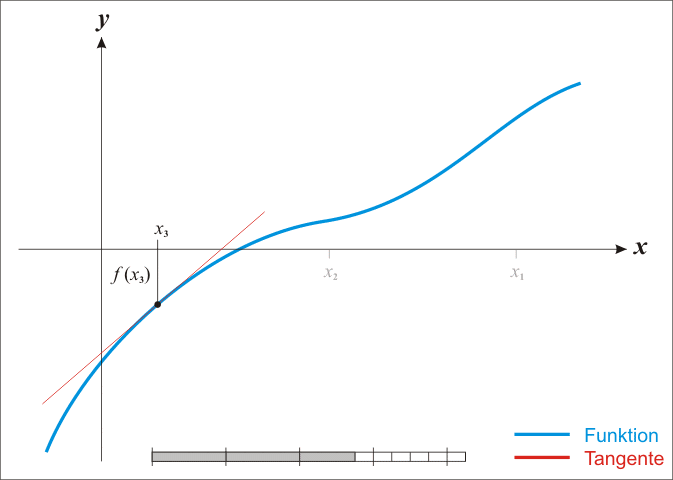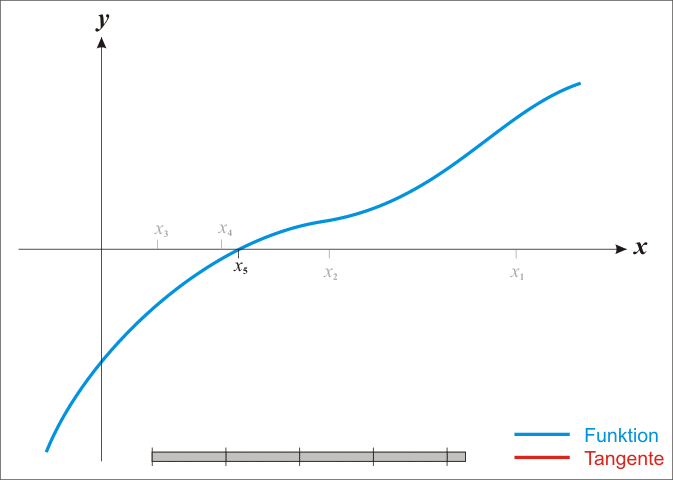
故牛頓迭代又稱切線法。
牛頓法用於函式最優化求解
將
我們希望
相關推薦
常用優化方法總結
本篇博文總結一些常用的優化演算法。 梯度下降法 最常見的優化方法是SGDSGD ,基礎的原理不詳細講了,講下其缺陷。 從泰勒公式的角度來看,梯度下降法將f(x)f(x) 展開到了一階。 θ=θ−η∗▽θJ(θ)θ=θ−η∗▽θJ(θ) 1. 當學
Unity+NGUI性能優化方法總結
自己 開關 知識 hierarchy .com 最終 需要 監控 com 1 資源分離打包與加載 遊戲中會有很多地方使用同一份資源。比如,有些界面會共用同一份字體、同一張圖集,有些場景會共用同一張貼圖,有些會怪物使用同一個Animator,等等。可以在制作遊戲安裝包
MySQL查詢優化方法總結
系統表 所有 全文檢索 更新 系統 and 插入 upd 一個 1.應盡量避免在 where 子句中使用!=或<>操作符,否則將引擎放棄使用索引而進行全表掃描。 2.對查詢進行優化,應盡量避免全表掃描,首先應考慮在 where 及 order by 涉及頻繁的
HBase性能優化方法總結(一)
rec inter next memstore 不支持 lena cred 追加 查詢效率 一 表的設計 1.1 Pre-Creating Regions 默認情況下,在創建HBase表的時候會自動創建一個region分區,當導入數據的時候,所有的HBase客戶端都向這
Jquery常用的方法總結
多個 clone for ons 背景顏色 type 實現 一段 兩種方法 1、關於頁面元素的引用通過jquery的$()引用元素包括通過id、class、元素名以及元素的層級關系及dom或者xpath條件等方法,且返回的對象為jquery對象(集合對象),不能直接調用do
HBase性能優化方法總結
設計 implement 性能優化 multiply 技術 long 重要 execution 範圍 1. 表的設計 1.1 Pre-Creating Regions 默認情況下,在創建HBase表的時候會自動創建一個region分區,當導入數據的時候,所有的HBase客戶
Java IO流常用操作方法總結
一、簡介 在實際工作中,基本上每個專案難免都會有檔案相關的操作,比如檔案上傳、檔案下載等,這些操作都是使用IO流進行操作的,本文將通過簡單的示例對常用的一些IO流進行總結。 二、使用詳解 【a】FileInputStream與FileOutputStream 首先通過檢視jdk文件,
【原創】Windows上應用程式報錯常用分析方法總結
在日常使用Windows的過程中,經常會遇到應用程式不能正常啟動、關閉等使用問題。對於Windows來說,解決這些問題的方法比較多,大多時候我們可以通過百度或谷歌搜尋來解決。但更多的時候,我們需要找出背後的原因,也要掌握分析問題和解決問題的方法。 分析應用程式異常的問題,一般的出發點有兩個,第一從應用程式本
PHP的效能優化方法總結
什麼情況之下,會遇到PHP效能問題? 1:PHP語法使用不恰當。 2:使用PHP語言做了它不擅長的事情。 3:使用PHP語言連線的服務不給力。 4:PHP自身的短板(PHP自身做不了的事情)。 5:我們也不知道的問題?(去探索、分析找到解決辦法,提升開發境界)。 對線上站點做壓力測試的時候
SQL優化方法總結
1.對查詢進行優化,要儘量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引。 2.應儘量避免在 where 子句中對欄位進行 null 值判斷,否則將導致引擎放棄使用索引而進行全表掃描,如: select id from t&nb
Spark常用優化方法
一、前言 1.為什麼要優化? 因為你的資源有限、更快速的跑完任務、防止不穩定因素導致的任務失敗。 2.怎樣做優化? 通常檢視spark的web UI,或者檢視執行中的logs 3.做哪方面的優化? spark 應用程式 80% 的優化,都是集中在三個地方:記憶體,磁碟
深度學習最全優化方法總結比較(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
前言 本文僅對一些常見的優化方法進行直觀介紹和簡單的比較,各種優化方法的詳細內容及公式只好去認真啃論文了,在此我就不贅述了。 SGD 此處的SGD指mini-batch gradient descent,關於batch gradient descent, stochastic gradient de
深度學習中的優化方法總結
梯度下降沿著整個訓練集的梯度方向下降。可以使用隨機梯度下降很大程度地加速,沿著隨機挑選的小批量資料的梯度下降。 批量演算法和小批量演算法 使用小批量的原因 n個樣本均值的標準差是σn√σn,其中σσ是樣本值真實的標準差。分母n−−√n表明使用更多的樣本來估計梯度的方
JS常用的方法總結
/** * 將引數格式化為物件 * @param urlParams type string * @example * let urlParams = 'name="xiaoliu"&age=20&sex="男"' * getUrlObject(urlParams) * @returns *
優化方法總結:SGD,Momentum,AdaGrad,RMSProp,Adam
1.SGD Batch Gradient Descent 在每一輪的訓練過程中,Batch Gradient Descent演算法用整個訓練集的資料計算cost fuction的梯度,並用該梯度對模型引數進行更新: Θ=Θ−α⋅▽ΘJ(Θ)Θ=Θ−α⋅▽ΘJ(
移動端IM開發者必讀(二):史上最全移動弱網路優化方法總結
1、前言 本文接上篇《移動端IM開發者必讀(一):通俗易懂,理解行動網路的“弱”和“慢”》,關於行動網路的主要特性,在上篇中已進行過詳細地闡述,本文將針對上篇中提到的特性,結合我們的實踐經驗,總結了四個方法來追求極致的“爽快”:快鏈路、輕往復、強監控、多非同步,從理論講到實
c#的webbrowser常用屬性方法總結
//載入一個空白頁面 webBrowser1.Navigate("about:blank");//設定webbrowser可編輯,需要webbrowser提前Navigate一個頁面 //方法一 mshtml.IHTMLDocument2 doc =webBrowser1.
前端效能優化方法總結
1、基礎: 高層協議有:檔案傳輸協議FTP、電子郵件傳輸協議SMTP、域名系統服務DNS、網路新聞傳輸協議NNTP和HTTP協議等 中介由三種:代理(Proxy)、閘道器(Gateway)和通道(Tunnel),一個代理根據URI的絕對格式來接受請求,重寫全部或部分訊息,通過 URI的標識
跨域問題極其常用解決方法總結
當提到跨域問題時,很多人會問,什麼是跨域問題呢?這裡的域指的到底是哪個域呢? 首先,什麼是跨域問題? 簡單地理解就是因為JavaScript同源策略的限制,a.com 域名下的js無法操作b.com或
深度學習中優化方法總結
最近在看Google的Deep Learning一書,看到優化方法那一部分,正巧之前用tensorflow也是對那些優化方法一知半解的,所以看完後就整理了下放上來,主要是一階的梯度法,包括SGD, Momentum, Nesterov Momentum, AdaGrad, RMSProp, Adam。