
記flume部署過程中遇到的問題以及解決方法(持續更新)
專案需求是將線上伺服器生成的日誌資訊實時匯入kafka,採用agent和collector分層傳輸,app的資料通過thrift傳給agent,agent通過avro sink將資料發給collector,collector將資料彙集後,傳送給kafka,拓撲結構如下:
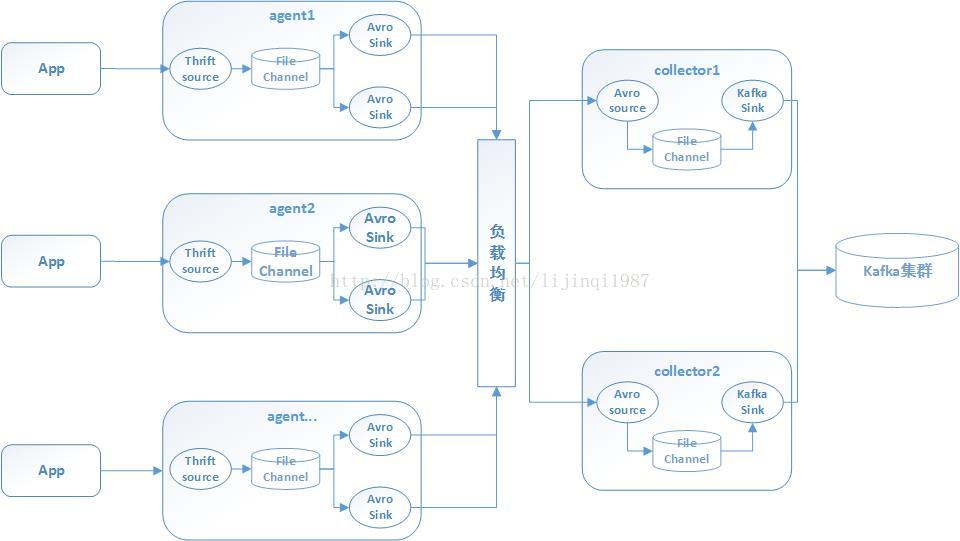
現將除錯過程中遇到的問題以及解決方法記錄如下:
1、[ERROR - org.apache.thrift.server.AbstractNonblockingServer$FrameBuffer.invoke(AbstractNonblockingServer.java:484)] Unexpected throwable while invoking!
java.lang.OutOfMemoryError: Java heap space
原因:flume啟動時的預設最大的堆記憶體大小是20M,實際環境中資料量較大時,很容易出現OOM問題,在flume的基礎配置檔案conf下的flume-env.sh中新增
export JAVA_OPTS="-Xms2048m -Xmx2048m -Xss256k -Xmn1g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:-UseGCOverheadLimit"
並且在flume啟動指令碼flume-ng中,修改JAVA_OPTS="-Xmx20m"為JAVA_OPTS="-Xmx2048m"
此處我們將堆記憶體的閾值跳轉到了2G,實際生產環境中可以根據具體的硬體情況作出調整
2、 [ERROR - org.apache.thrift.server.TThreadedSelectorServer$SelectorThread.run(TThreadedSelectorServer.java:544)] run() exiting due to uncaught error
java.lang.OutOfMemoryError: unable to create new native thread
原因:如果App給flume的thrift source傳送資料時,採用短連線,會無限地建立執行緒,使用命令 pstree 時發現java的執行緒數隨著傳送資料量的增長在不停增長,最終達到了65500多個,超過了linux系統對執行緒的限制,解決方法是在thrift source配置項中增加一個執行緒數的限制。
agent.sources.r1.threads = 50
重新啟動agent發現java的執行緒數達到70多就不再增長了
3、 Caused by: org.apache.flume.ChannelException: Put queue for MemoryTransaction of capacity 100 full, consider committing more frequently, increasing capacity or increasing thread count
原因:這是memory channel被佔滿導致的錯誤,memory channel預設最多隻快取100條資料,在生產環境中明顯不夠,需要將capacity引數加大
4、warn:"Thrift source %s could not append events to the channel."。
原因:檢視flume的配置文件可以發現,各種型別的sink(thrift、avro、kafka等)的預設batch-size都是100,file channel、memory channel的transactioncapacity預設也都是100,如果修改了sink的batch-size,需要將batch-size設定為小於等於channel的transactioncapacity的值,否則就會出現上面的warn導致資料無法正常傳送
5、agent處報
(SinkRunner-PollingRunner-DefaultSinkProcessor) [ERROR - org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:160)] Unable to deliver event. Exception follows.
org.apache.flume.EventDeliveryException: Failed to send events
at org.apache.flume.sink.AbstractRpcSink.process(AbstractRpcSink.java:392)
at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:68)
at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:147)
at java.lang.Thread.run(Thread.java:744)
Caused by: org.apache.flume.EventDeliveryException: NettyAvroRpcClient { host: 10.200.197.82, port: 5150 }: Failed to send batch
at org.apache.flume.api.NettyAvroRpcClient.appendBatch(NettyAvroRpcClient.java:315)
at org.apache.flume.sink.AbstractRpcSink.process(AbstractRpcSink.java:376)
... 3 more
Caused by: org.apache.flume.EventDeliveryException: NettyAvroRpcClient { host: 10.200.197.82, port: 5150 }: Exception thrown from remote handler
at org.apache.flume.api.NettyAvroRpcClient.waitForStatusOK(NettyAvroRpcClient.java:397)
at org.apache.flume.api.NettyAvroRpcClient.appendBatch(NettyAvroRpcClient.java:374)
at org.apache.flume.api.NettyAvroRpcClient.appendBatch(NettyAvroRpcClient.java:303)
... 4 more
Caused by: java.util.concurrent.ExecutionException: java.io.IOException: Connection reset by peer
at org.apache.avro.ipc.CallFuture.get(CallFuture.java:128)
at org.apache.flume.api.NettyAvroRpcClient.waitForStatusOK(NettyAvroRpcClient.java:389)
... 6 more
Caused by: java.io.IOException: Connection reset by peer
at sun.nio.ch.FileDispatcherImpl.read0(Native Method)
at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39)
at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223)
at sun.nio.ch.IOUtil.read(IOUtil.java:192)
at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:379)
at org.jboss.netty.channel.socket.nio.NioWorker.read(NioWorker.java:59)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.processSelectedKeys(AbstractNioWorker.java:471)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.run(AbstractNioWorker.java:332)
at org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:35)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
... 1 more
collector報
2017-08-21 16:36:43,010 (New I/O worker #12) [WARN - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.exceptionCaught(NettyServer.java:201)] Unexpected exception from downstream.
org.apache.avro.AvroRuntimeException: Excessively large list allocation request detected: 349070535 items! Connection closed.
at org.apache.avro.ipc.NettyTransportCodec$NettyFrameDecoder.decodePackHeader(NettyTransportCodec.java:167)
at org.apache.avro.ipc.NettyTransportCodec$NettyFrameDecoder.decode(NettyTransportCodec.java:139)
at org.jboss.netty.handler.codec.frame.FrameDecoder.callDecode(FrameDecoder.java:422)
at org.jboss.netty.handler.codec.frame.FrameDecoder.cleanup(FrameDecoder.java:478)
at org.jboss.netty.handler.codec.frame.FrameDecoder.channelDisconnected(FrameDecoder.java:366)
at org.jboss.netty.channel.Channels.fireChannelDisconnected(Channels.java:399)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.close(AbstractNioWorker.java:721)
at org.jboss.netty.channel.socket.nio.NioServerSocketPipelineSink.handleAcceptedSocket(NioServerSocketPipelineSink.java:111)
at org.jboss.netty.channel.socket.nio.NioServerSocketPipelineSink.eventSunk(NioServerSocketPipelineSink.java:66)
at org.jboss.netty.handler.codec.oneone.OneToOneEncoder.handleDownstream(OneToOneEncoder.java:54)
at org.jboss.netty.channel.Channels.close(Channels.java:820)
at org.jboss.netty.channel.AbstractChannel.close(AbstractChannel.java:197)
at org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.exceptionCaught(NettyServer.java:202)
at org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:173)
at org.jboss.netty.handler.codec.frame.FrameDecoder.exceptionCaught(FrameDecoder.java:378)
at org.jboss.netty.channel.Channels.fireExceptionCaught(Channels.java:533)
at org.jboss.netty.channel.AbstractChannelSink.exceptionCaught(AbstractChannelSink.java:48)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:268)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:255)
at org.jboss.netty.channel.socket.nio.NioWorker.read(NioWorker.java:84)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.processSelectedKeys(AbstractNioWorker.java:471)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.run(AbstractNioWorker.java:332)
at org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:35)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
原因:當agent到collector的資料在agent的avro sink處進行壓縮時,在collector的avro source處必須解壓,否則資料無法傳送
6、org.apache.kafka.common.errors.RecordTooLargeException: There are some messages at [Partition=Offset]: {ssp_package-0=388595} whose size is larger than the fetch size 1048576 and hence cannot be ever returned. Increase the fetch size, or decrease the maximum message size the broker will allow.
2017-10-11 01:30:10,000 (PollableSourceRunner-KafkaSource-r1) [ERROR - org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:314)] KafkaSource EXCEPTION, {}
原因:配置kafka source時,flume作為kafka的consumer,在consumer消費kafka資料時,預設最大檔案大小是1m,如果檔案大小超過1m,需要手動在配置裡面調整引數,
但是在flume官網的配置說明-kakka source中,並沒有找到配置fetch size的地方,但是在配置的最後一行有一個
Other Kafka Consumer Properties--These properties are used to configure the Kafka Consumer. Any consumer property supported by Kafka can be used. The only requirement is to prepend the property name with the prefix kafka.consumer. For example: kafka.consumer.auto.offset.reset
此處配置用的是kafka的配置方法,在kafka官網的配置文件-consumer configs-max.partition.fetch.bytes有相關說明
agent.sources.r1.kafka.consumer.max.partition.fetch.bytes = 10240000
此處將consumer的fetch.byte加到10m
7、2017-10-13 01:19:47,991 (SinkRunner-PollingRunner-DefaultSinkProcessor) [ERROR - org.apache.flume.sink.kafka.KafkaSink.process(KafkaSink.java:240)] Failed to publish events
java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.RecordTooLargeException: The message is 2606058 bytes when serialized which is larger than the maximum request size you have configured with the max.request.size configuration.
at org.apache.kafka.clients.producer.KafkaProducer$FutureFailure.<init>(KafkaProducer.java:686)
at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:449)
at org.apache.flume.sink.kafka.KafkaSink.process(KafkaSink.java:212)
at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67)
at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145)
at java.lang.Thread.run(Thread.java:745)
Caused by: org.apache.kafka.common.errors.RecordTooLargeException: The message is 2606058 bytes when serialized which is larger than the maximum request size you have configured with the max.request.size configuration.
原因:與上一點類似,此處是kafka sink時,flume作為producer,也要設定檔案的fetch大小,同樣是參考kafka官網的配置
agent.sinks.k1.kafka.producer.max.request.size = 10240000
8、java.io.IOException: Too many open files
at sun.nio.ch.ServerSocketChannelImpl.accept0(Native Method)
at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:250)
at org.mortbay.jetty.nio.SelectChannelConnector$1.acceptChannel(SelectChannelConnector.java:75)
at org.mortbay.io.nio.SelectorManager$SelectSet.doSelect(SelectorManager.java:686)
at org.mortbay.io.nio.SelectorManager.doSelect(SelectorManager.java:192)
at org.mortbay.jetty.nio.SelectChannelConnector.accept(SelectChannelConnector.java:124)
at org.mortbay.jetty.AbstractConnector$Acceptor.run(AbstractConnector.java:708)
at org.mortbay.thread.QueuedThreadPool$PoolThread.run(QueuedThreadPool.java:582)
原因:檔案控制代碼佔用太多,首先檢視flume佔用控制代碼個數
lsof -p pid | wc -l
pid是flume程序號,
vim /etc/security/limits.conf
在最後加入
* soft nofile 4096
* hard nofile 4096
最前的 * 表示所有使用者,改完後重啟下flume服務
9、(kafka-producer-network-thread | producer-1) [ERROR - org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:130)] Uncaught
error in kafka producer I/O thread:
org.apache.kafka.common.protocol.types.SchemaException: Error reading field 'throttle_time_ms': java.nio.BufferUnderflowException
at org.apache.kafka.common.protocol.types.Schema.read(Schema.java:71)
at org.apache.kafka.clients.NetworkClient.handleCompletedReceives(NetworkClient.java:439)
at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:265)
at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:216)
at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:128)
at java.lang.Thread.run(Thread.java:744)
原因:kafka叢集版本較老,flume版本較新,此處kafka使用的版本是較老的0.8.2, flume使用1.7則會報上述錯誤,只能將flume降為1.6版本
9、sink到kafka上的資料沒有均勻的分佈在各個partition上,而是全部放在了同一個partition上
原因:這是老版本flume遺留下的一個bug,需要在event中構造一個包含key為 key 的header 鍵值對就能達到目的
a1.sources.flume0.interceptors.i1.type = org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
a1.sources.flume0.interceptors.i1.headerName = key