
celery使用的小記錄
一篇還不錯的入門說明: http://www.bjhee.com/celery.html,
官方文件: http://docs.jinkan.org/docs/celery/getting-started/brokers/redis.html
這裡不多說重複內容,只講一下結構上的理解:
celery不僅是佇列,它是一個並行分散式框架。
你不需要考慮怎麼分散式,怎麼寫daemon程序,只需要關注你的單個任務要怎麼處理。當你把單個任務處理的程式碼放入celery框架之後,它就自帶了並行、分散式、後臺持續執行的特點。
celery使用redis,rabbitMQ等作為broker,它的兩個角色:任務傳送方(生產者)把任務放入佇列,worker(消費者)從佇列中取出任務進行處理。這兩個角色並不要求在同一臺機器上,且可以有多臺機器上的多個生產者,也可以有多臺機器上的多個worker。
celery的生產者和消費者怎麼知道該使用哪個函式執行任務呢?這其實是使用了反射機制,以官方文件getting started例子來說,即:
當生產者使用
from my_tasks import add
ret = add.delay(3, 4)把這個任務放入佇列的時候,同時放入了my_tasks.add這個函式名,消費者取出任務的同時會取出這個my_tasks.add並呼叫自己的已經匯入的這個函式進行處理。
所以在生產者、消費者的匯入上需要注意,否則消費者會報找不到函式的。
(注意:在資料夾folder中使用from .my_tasks import add匯入的add將會被當成folder.my_tasks.add
Python系列之反射、面向物件 https://www.cnblogs.com/yyyg/p/5554111.html
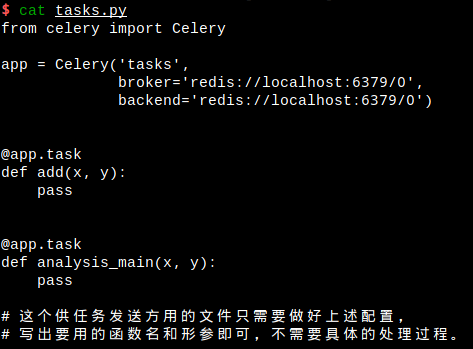
生產者和消費者都需要匯入一個定義了任務的同名檔案(如:my_tasks.py),注意是同名檔案,而不必是同一檔案。(當生產者和消費者不在同一臺機器上,自然無法是同一檔案...)
消費者所匯入的my_tasks檔案中,當然需要包含詳細的處理過程,但是生產者所匯入的my_tasks檔案,作用卻和C/C++中的標頭檔案差不多。
重新構造AsyncResult物件
上面呼叫ret = add.delay(3, 4)時,返回的 ret 是一個AsyncResult物件,可以使用 ret.ready() 檢視任務是否執行完畢,使用ret.get(timeout=xx)獲取執行結果。(需要配置backend)
當任務很多的時候,我是不是可以把這些任務的id寫入文字檔案或者資料庫,等過一段時間再來查詢某個任務的狀態呢?
當然可以,ret這個AsyncResult物件可以使用ret.id這個字串重新構造:
ret
<AsyncResult: b733c852-4161-449e-930a-a395702b1203>
ret.id
'b733c852-4161-449e-930a-a395702b1203'# 構造:
import tasks # 為了匯入backend配置,不必重複匯入
from celery.result import AsyncResult
r=AsyncResult('b733c852-4161-449e-930a-a395702b1203')
r
<AsyncResult: b733c852-4161-449e-930a-a395702b1203>
r.ready()
True # 任務已執行完畢
r.get(timeout=3)
。。。。