
Spark SQL 1.3.0 DataFrame介紹、使用及提供了些完整的資料寫入
阿新 • • 發佈:2019-01-06
問題導讀
1.DataFrame是什麼?
2.如何建立DataFrame?
3.如何將普通RDD轉變為DataFrame?
4.如何使用DataFrame?
5.在1.3.0中,提供了哪些完整的資料寫入支援API?

自2013年3月面世以來,Spark SQL已經成為除Spark Core以外最大的Spark元件。除了接過Shark的接力棒,繼續為Spark使用者提供高效能的SQL on Hadoop解決方案之外,它還為Spark帶來了通用、高效、多元一體的結構化資料處理能力。在剛剛釋出的1.3.0版中,Spark SQL的兩大升級被詮釋得淋漓盡致。 DataFrame 就易用性而言,對比傳統的MapReduce API,說Spark的RDD API有了數量級的飛躍並不為過。然而,對於沒有MapReduce和函數語言程式設計經驗的新手來說,RDD API仍然存在著一定的門檻。另一方面,資料科學家們所熟悉的R、Pandas等傳統資料框架雖然提供了直觀的API,卻侷限於單機處理,無法勝任大資料場景。為了解決這一矛盾,Spark SQL 1.3.0在原有SchemaRDD的基礎上提供了與R和Pandas風格類似的DataFrame API。新的DataFrame API不僅可以大幅度降低普通開發者的學習門檻,同時還支援Scala、Java與Python三種語言。更重要的是,由於脫胎自SchemaRDD,DataFrame天然適用於分散式大資料場景。 DataFrame是什麼? 
建立DataFrame 在Spark SQL中,開發者可以非常便捷地將各種內、外部的單機、分散式資料轉換為DataFrame。以下Python示例程式碼充分體現了Spark SQL 1.3.0中DataFrame資料來源的豐富多樣和簡單易用:
可見,從Hive表,到外部資料來源API支援的各種資料來源(JSON、Parquet、JDBC),再到RDD乃至各種本地資料集,都可以被方便快捷地載入、轉換為DataFrame。這些功能也同樣存在於Spark SQL的Scala API和Java API中。 使用DataFrame 和R、Pandas類似,Spark DataFrame也提供了一整套用於操縱資料的DSL。這些DSL在語義上與SQL關係查詢非常相近(這也是Spark SQL能夠為DataFrame提供無縫支援的重要原因之一)。以下是一組使用者資料分析示例:
除DSL以外,我們當然也可以像以往一樣,用SQL來處理DataFrame:
幕後英雄:Spark SQL查詢優化器與程式碼生成 正如RDD的各種變換實際上只是在構造RDD DAG,DataFrame的各種變換同樣也是lazy的。它們並不直接求出計算結果,而是將各種變換組裝成與RDD DAG類似的邏輯查詢計劃。如前所述,由於DataFrame帶有schema元資訊,Spark SQL的查詢優化器得以洞察資料和計算的精細結構,從而施行具有很強針對性的優化。隨後,經過優化的邏輯執行計劃被翻譯為物理執行計劃,並最終落實為RDD DAG。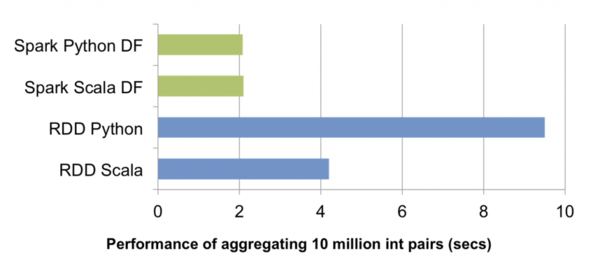
這樣做的好處體現在幾個方面: 1. 使用者可以用更少的申明式程式碼闡明計算邏輯,物理執行路徑則交由Spark SQL自行挑選。一方面降低了開發成本,一方面也降低了使用門檻——很多情況下,即便新手寫出了較為低效的查詢,Spark SQL也可以通過過濾條件下推、列剪枝等策略予以有效優化。這是RDD API所不具備的。 2. Spark SQL可以動態地為物理執行計劃中的表示式生成JVM位元組碼,進一步實現歸避虛擬函式呼叫開銷、削減物件分配次數等底層優化,使得最終的查詢執行效能可以與手寫程式碼的效能相媲美。 3. 對於PySpark而言,採用DataFrame程式設計時只需要構造體積小巧的邏輯執行計劃,物理執行全部由JVM端負責,Python直譯器和JVM間大量不必要的跨程序通訊得以免除。如上圖所示,一組簡單的對一千萬整數對做聚合的測試中,PySpark中DataFrame API的效能輕鬆勝出RDD API近五倍。此外,今後Spark SQL在Scala端對查詢優化器的所有效能改進,PySpark都可以免費獲益。 外部資料來源API增強
從前文中我們已經看到,Spark 1.3.0為DataFrame提供了豐富多樣的資料來源支援。其中的重頭戲,便是自Spark 1.2.0引入的外部資料來源API。在1.3.0中,我們對這套API做了進一步的增強。 資料寫入支援 在Spark 1.2.0中,外部資料來源API只能將外部資料來源中的資料讀入Spark,而無法將計算結果寫回資料來源;同時,通過資料來源引入並註冊的表只能是臨時表,相關元資訊無法持久化。在1.3.0中,我們提供了完整的資料寫入支援,從而補全了多資料來源互操作的最後一塊重要拼圖。前文示例中Hive、Parquet、JSON、Pandas等多種資料來源間的任意轉換,正是這一增強的直接成果。 站在Spark SQL外部資料來源開發者的角度,資料寫入支援的API主要包括: 1. 資料來源表元資料持久化 1.3.0引入了新的外部資料來源DDL語法(SQL程式碼片段)
由此,註冊自外部資料的SQL表既可以是臨時表,也可以被持久化至Hive metastore。需要持久化支援的外部資料來源,除了需要繼承原有的RelationProvider以外,還需繼承CreatableRelationProvider。 2. InsertableRelation 支援資料寫入的外部資料來源的relation類,還需繼承trait InsertableRelation,並在insert方法中實現資料插入邏輯。 Spark 1.3.0中內建的JSON和Parquet資料來源都已實現上述API,可以作為開發外部資料來源的參考示例。 統一的load/save API 在Spark 1.2.0中,要想將SchemaRDD中的結果儲存下來,便捷的選擇並不多。常用的一些包括:
可見,不同的資料輸出方式,採用的API也不盡相同。更令人頭疼的是,我們缺乏一個靈活擴充套件新的資料寫入格式的方式。 針對這一問題,1.3.0統一了load/save API,讓使用者按需自由選擇外部資料來源。這套API包括: 1.SQLContext.table 從SQL表中載入DataFrame。 2.SQLContext.load 從指定的外部資料來源載入DataFrame。 3.SQLContext.createExternalTable 將指定位置的資料儲存為外部SQL表,元資訊存入Hive metastore,並返回包含相應資料的DataFrame。 4.DataFrame.save 將DataFrame寫入指定的外部資料來源。 5.DataFrame.saveAsTable 將DataFrame儲存為SQL表,元資訊存入Hive metastore,同時將資料寫入指定位置。 Parquet資料來源增強 Spark SQL從一開始便內建支援Parquet這一高效的列式儲存格式。在開放外部資料來源API之後,原有的Parquet支援也正在逐漸轉向外部資料來源。1.3.0中,Parquet外部資料來源的能力得到了顯著增強。主要包括schema合併和自動分割槽處理。 1.Schema合併 與ProtocolBuffer和Thrift類似,Parquet也允許使用者在定義好schema之後隨時間推移逐漸新增新的列,只要不修改原有列的元資訊,新舊schema仍然可以相容。這一特性使得使用者可以隨時按需新增新的資料列,而無需操心資料遷移。 2.分割槽資訊發現 按目錄對同一張表中的資料分割槽儲存,是Hive等系統採用的一種常見的資料儲存方式。新的Parquet資料來源可以自動根據目錄結構發現和推演分割槽資訊。 3.分割槽剪枝 分割槽實際上提供了一種粗粒度的索引。當查詢條件中僅涉及部分分割槽時,通過分割槽剪枝跳過不必要掃描的分割槽目錄,可以大幅提升查詢效能。 以下Scala程式碼示例統一展示了1.3.0中Parquet資料來源的這幾個能力(Scala程式碼片段):
1.DataFrame是什麼?
2.如何建立DataFrame?
3.如何將普通RDD轉變為DataFrame?
4.如何使用DataFrame?
5.在1.3.0中,提供了哪些完整的資料寫入支援API?
自2013年3月面世以來,Spark SQL已經成為除Spark Core以外最大的Spark元件。除了接過Shark的接力棒,繼續為Spark使用者提供高效能的SQL on Hadoop解決方案之外,它還為Spark帶來了通用、高效、多元一體的結構化資料處理能力。在剛剛釋出的1.3.0版中,Spark SQL的兩大升級被詮釋得淋漓盡致。 DataFrame 就易用性而言,對比傳統的MapReduce API,說Spark的RDD API有了數量級的飛躍並不為過。然而,對於沒有MapReduce和函數語言程式設計經驗的新手來說,RDD API仍然存在著一定的門檻。另一方面,資料科學家們所熟悉的R、Pandas等傳統資料框架雖然提供了直觀的API,卻侷限於單機處理,無法勝任大資料場景。為了解決這一矛盾,Spark SQL 1.3.0在原有SchemaRDD的基礎上提供了與R和Pandas風格類似的DataFrame API。新的DataFrame API不僅可以大幅度降低普通開發者的學習門檻,同時還支援Scala、Java與Python三種語言。更重要的是,由於脫胎自SchemaRDD,DataFrame天然適用於分散式大資料場景。 DataFrame是什麼?
建立DataFrame 在Spark SQL中,開發者可以非常便捷地將各種內、外部的單機、分散式資料轉換為DataFrame。以下Python示例程式碼充分體現了Spark SQL 1.3.0中DataFrame資料來源的豐富多樣和簡單易用:
-
# 從Hive中的users表構造DataFrame
-
users = sqlContext.table("users")
-
# 載入S3上的JSON檔案
-
logs = sqlContext.load("s3n://path/to/data.json", "json")
-
# 載入HDFS上的Parquet檔案
-
clicks = sqlContext.load("hdfs://path/to/data.parquet", "parquet")
-
# 通過JDBC訪問MySQL
-
comments = sqlContext.jdbc("jdbc:mysql://localhost/comments", "user")
-
# 將普通RDD轉變為DataFrame
-
rdd = sparkContext.textFile("article.txt") \
-
.flatMap(lambda line: line.split()) \
-
.map(lambda word: (word, 1)) \
-
.reduceByKey(lambda a, b: a + b) \
-
wordCounts = sqlContext.createDataFrame(rdd, ["word", "count"])
-
# 將本地資料容器轉變為DataFrame
-
data = [("Alice", 21), ("Bob", 24)]
-
people = sqlContext.createDataFrame(data, ["name", "age"])
-
# 將Pandas DataFrame轉變為Spark DataFrame(Python API特有功能)
- sparkDF = sqlContext.createDataFrame(pandasDF)
可見,從Hive表,到外部資料來源API支援的各種資料來源(JSON、Parquet、JDBC),再到RDD乃至各種本地資料集,都可以被方便快捷地載入、轉換為DataFrame。這些功能也同樣存在於Spark SQL的Scala API和Java API中。 使用DataFrame 和R、Pandas類似,Spark DataFrame也提供了一整套用於操縱資料的DSL。這些DSL在語義上與SQL關係查詢非常相近(這也是Spark SQL能夠為DataFrame提供無縫支援的重要原因之一)。以下是一組使用者資料分析示例:
-
# 建立一個只包含"年輕"使用者的DataFrame
-
young = users.filter(users.age < 21)
-
# 也可以使用Pandas風格的語法
-
young = users[users.age < 21]
-
# 將所有人的年齡加1
-
young.select(young.name, young.age + 1)
-
# 統計年輕使用者中各性別人數
-
young.groupBy("gender").count()
-
# 將所有年輕使用者與另一個名為logs的DataFrame聯接起來
- young.join(logs, logs.userId == users.userId, "left_outer")
除DSL以外,我們當然也可以像以往一樣,用SQL來處理DataFrame:
-
young.registerTempTable("young")
- sqlContext.sql("SELECT count(*) FROM young")
-
# 追加至HDFS上的Parquet檔案
-
young.save(path="hdfs://path/to/data.parquet",
-
source="parquet",
-
mode="append")
-
# 覆寫S3上的JSON檔案
-
young.save(path="s3n://path/to/data.json",
-
source="json",
-
mode="append")
-
# 儲存為SQL表
-
young.saveAsTable(tableName="young", source="parquet" mode="overwrite")
-
# 轉換為Pandas DataFrame(Python API特有功能)
-
pandasDF = young.toPandas()
-
# 以表格形式列印輸出
- young.show()
幕後英雄:Spark SQL查詢優化器與程式碼生成 正如RDD的各種變換實際上只是在構造RDD DAG,DataFrame的各種變換同樣也是lazy的。它們並不直接求出計算結果,而是將各種變換組裝成與RDD DAG類似的邏輯查詢計劃。如前所述,由於DataFrame帶有schema元資訊,Spark SQL的查詢優化器得以洞察資料和計算的精細結構,從而施行具有很強針對性的優化。隨後,經過優化的邏輯執行計劃被翻譯為物理執行計劃,並最終落實為RDD DAG。
這樣做的好處體現在幾個方面: 1. 使用者可以用更少的申明式程式碼闡明計算邏輯,物理執行路徑則交由Spark SQL自行挑選。一方面降低了開發成本,一方面也降低了使用門檻——很多情況下,即便新手寫出了較為低效的查詢,Spark SQL也可以通過過濾條件下推、列剪枝等策略予以有效優化。這是RDD API所不具備的。 2. Spark SQL可以動態地為物理執行計劃中的表示式生成JVM位元組碼,進一步實現歸避虛擬函式呼叫開銷、削減物件分配次數等底層優化,使得最終的查詢執行效能可以與手寫程式碼的效能相媲美。 3. 對於PySpark而言,採用DataFrame程式設計時只需要構造體積小巧的邏輯執行計劃,物理執行全部由JVM端負責,Python直譯器和JVM間大量不必要的跨程序通訊得以免除。如上圖所示,一組簡單的對一千萬整數對做聚合的測試中,PySpark中DataFrame API的效能輕鬆勝出RDD API近五倍。此外,今後Spark SQL在Scala端對查詢優化器的所有效能改進,PySpark都可以免費獲益。 外部資料來源API增強
從前文中我們已經看到,Spark 1.3.0為DataFrame提供了豐富多樣的資料來源支援。其中的重頭戲,便是自Spark 1.2.0引入的外部資料來源API。在1.3.0中,我們對這套API做了進一步的增強。 資料寫入支援 在Spark 1.2.0中,外部資料來源API只能將外部資料來源中的資料讀入Spark,而無法將計算結果寫回資料來源;同時,通過資料來源引入並註冊的表只能是臨時表,相關元資訊無法持久化。在1.3.0中,我們提供了完整的資料寫入支援,從而補全了多資料來源互操作的最後一塊重要拼圖。前文示例中Hive、Parquet、JSON、Pandas等多種資料來源間的任意轉換,正是這一增強的直接成果。 站在Spark SQL外部資料來源開發者的角度,資料寫入支援的API主要包括: 1. 資料來源表元資料持久化 1.3.0引入了新的外部資料來源DDL語法(SQL程式碼片段)
-
CREATE [TEMPORARY] TABLE [IF NOT EXISTS]
-
<table-name> [(col-name data-type [, ...)]
-
USING <source> [OPTIONS ...]
- [AS <select-query>]
由此,註冊自外部資料的SQL表既可以是臨時表,也可以被持久化至Hive metastore。需要持久化支援的外部資料來源,除了需要繼承原有的RelationProvider以外,還需繼承CreatableRelationProvider。 2. InsertableRelation 支援資料寫入的外部資料來源的relation類,還需繼承trait InsertableRelation,並在insert方法中實現資料插入邏輯。 Spark 1.3.0中內建的JSON和Parquet資料來源都已實現上述API,可以作為開發外部資料來源的參考示例。 統一的load/save API 在Spark 1.2.0中,要想將SchemaRDD中的結果儲存下來,便捷的選擇並不多。常用的一些包括:
- rdd.saveAsParquetFile(...)
- rdd.saveAsTextFile(...)
- rdd.toJSON.saveAsTextFile(...)
- rdd.saveAsTable(...)
-
....
可見,不同的資料輸出方式,採用的API也不盡相同。更令人頭疼的是,我們缺乏一個靈活擴充套件新的資料寫入格式的方式。 針對這一問題,1.3.0統一了load/save API,讓使用者按需自由選擇外部資料來源。這套API包括: 1.SQLContext.table 從SQL表中載入DataFrame。 2.SQLContext.load 從指定的外部資料來源載入DataFrame。 3.SQLContext.createExternalTable 將指定位置的資料儲存為外部SQL表,元資訊存入Hive metastore,並返回包含相應資料的DataFrame。 4.DataFrame.save 將DataFrame寫入指定的外部資料來源。 5.DataFrame.saveAsTable 將DataFrame儲存為SQL表,元資訊存入Hive metastore,同時將資料寫入指定位置。 Parquet資料來源增強 Spark SQL從一開始便內建支援Parquet這一高效的列式儲存格式。在開放外部資料來源API之後,原有的Parquet支援也正在逐漸轉向外部資料來源。1.3.0中,Parquet外部資料來源的能力得到了顯著增強。主要包括schema合併和自動分割槽處理。 1.Schema合併 與ProtocolBuffer和Thrift類似,Parquet也允許使用者在定義好schema之後隨時間推移逐漸新增新的列,只要不修改原有列的元資訊,新舊schema仍然可以相容。這一特性使得使用者可以隨時按需新增新的資料列,而無需操心資料遷移。 2.分割槽資訊發現 按目錄對同一張表中的資料分割槽儲存,是Hive等系統採用的一種常見的資料儲存方式。新的Parquet資料來源可以自動根據目錄結構發現和推演分割槽資訊。 3.分割槽剪枝 分割槽實際上提供了一種粗粒度的索引。當查詢條件中僅涉及部分分割槽時,通過分割槽剪枝跳過不必要掃描的分割槽目錄,可以大幅提升查詢效能。 以下Scala程式碼示例統一展示了1.3.0中Parquet資料來源的這幾個能力(Scala程式碼片段):
-
// 建立兩個簡單的DataFrame,將之存入兩個獨立的分割槽目錄
-
val df1 = (1 to 5).map(i => (i, i * 2)).toDF("single", "double")
-
df1.save("data/test_table/key=1", "parquet", SaveMode.Append)
-
val df2 = (6 to 10).map(i => (i, i * 2)).toDF("single", "double")
-
df2.save("data/test_table/key=2", "parquet", SaveMode.Append)
-
// 在另一個DataFrame中引入一個新的列,並存入另一個分割槽目錄
-
val df3 = (11 to 15).map(i => (i, i * 3)).toDF("single", "triple")
-
df3.save("data/test_table/key=3", "parquet", SaveMode.Append)
-
// 一次性讀入整個分割槽表的資料
-
val df4 = sqlContext.load("data/test_table", "parquet")
-
// 按分割槽進行查詢,並展示結果
- val df5 = df4.filter($"key" >= 2) df5.show()
-
6 12 null 2
-
7 14 null 2
-
8 16 null 2
-
9 18 null 2
-
10 20 null 2
-
11 null 33 3
-
12 null 36 3
-
13 null 39 3
-
14 null 42 3
- 15 null 45 3