
聊聊分散式鏈路追蹤
原文連結:http://lidawn.github.io/2018/12/26/distribute-tracing/
起因
最近一直在做分散式鏈路追蹤的調研和實踐,整理一下其中的知識點。
什麼是鏈路追蹤
分散式系統變得日趨複雜,越來越多的元件開始走向分散式化,如微服務、分散式資料庫、分散式快取等,使得後臺服務構成了一種複雜的分散式網路。在服務能力提升的同時,複雜的網路結構也使問題定位更加困難。在一個請求在經過諸多服務過程中,出現了某一個呼叫失敗的情況,查詢具體的異常由哪一個服務引起的就變得十分抓狂,問題定位和處理效率是也會非常低。
分散式鏈路追蹤就是將一次分散式請求還原成呼叫鏈路,將一次分散式請求的呼叫情況集中展示,比如各個服務節點上的耗時、請求具體到達哪臺機器上、每個服務節點的請求狀態等等。
Dapper
目前業界的鏈路追蹤系統,如Twitter的Zipkin,Uber的Jaeger,阿里的鷹眼,美團的Mtrace等都基本被啟發於google發表的Dapper。 Dapper闡述了分散式系統,特別是微服務架構中鏈路追蹤的概念、資料表示、埋點、傳遞、收集、儲存與展示等技術細節。
Trace、Span、Annotations
為了實現鏈路追蹤,dapper提出了trace,span,annotation的概念。
Trace的含義比較直觀,就是鏈路,指一個請求經過後端所有服務的路徑,可以用下面樹狀的圖形表示。每一條鏈路都用一個全域性唯一的traceid來標識。
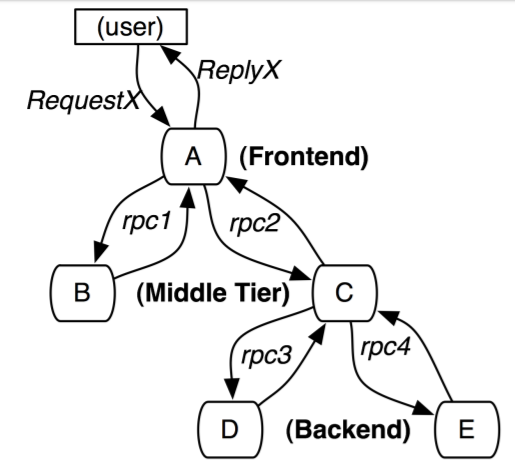
Span之間存在著父子關係,上游的span是下游的父span,例如圖中"frontend.request"會呼叫"backend.dosomething","backend.dosomething"便成為"frontend.request"的子span。

鏈路中的rpc呼叫由span來表示,對應著樹狀圖中的邊,每個span由spanid和parentid來標識,spanid在一條鏈路中唯一。
下圖是dapper論文中給出的一個"hepler.call"呼叫的span詳解。
一個span一般由client和server兩個部分的資訊組成。按照時間順序來解釋,client節點(或者是呼叫方)首先發出請求,產生"client send"(cs)事件,緊接著server節點(或者是提供方)收到請求,產生"server receive"(sr)事件,server處理完成之後回覆給client,產生"server send"事件,最後client收到回覆,產生"client receive"事件。
Client與server兩個節點的span資訊合併成一次完整的呼叫,即一個完整的span。

Dapper中還定義了annotation的概念,用於使用者自定義事件,如圖二中的"foo",用來輔助定位問題。
值得一提的是,zipkin中把cs,cr,ss,sr這幾個事件稱之為annotation,而對應dapper中的annotation在zipkin v1的資料模型中被稱之為binaryAnnotation。
帶內資料與帶外資料
鏈路資訊的還原依賴於兩種資料,一種是各個節點產生的事件,如cs,ss,稱之為帶外資料,這些資料可以由節點獨立生成,並且需要集中上報到儲存端。
另一種資料是traceid,spanid,parentid,用來標識trace,span,以及span在一個trace中的位置。這些資料需要從鏈路的起點一直傳遞到終點,稱之為帶內資料。 通過帶內資料的傳遞,可以將一個鏈路的所有過程串起來;通過帶外資料,可以在儲存端分析更多鏈路的細節。
取樣
由於每一個請求就會生成一個鏈路,為了減少效能消耗,避免儲存資源的浪費,dapper並不會上報所有的span資料,而是使用取樣的方式。通過採集端自適應地調整取樣率,控制span上報的數量,可以在發現效能瓶頸的同時,有效減少效能損耗。取樣率的概念在其他的追蹤系統中也被廣泛使用。在zipkin小節中將更具體闡述zipkin的取樣機制。
儲存
鏈路中的span資料經過收集和上報後會集中儲存在一個地方,Dapper使用了BigTable資料倉庫,如下圖所示,由於每種trace的span個數不盡相同,使得BigTable稀疏表格佈局很適合這種場景,並且分散的span進行儲存時按照traceid和spanid便可以插入到對應的行列中,使得收集程式可以無需做任何計算且無狀態。同時鏈路的查詢也十分方便,即取表中的一行。

Zipkin
Zipkin是dapper的一種開源實現,也是業界做鏈路追蹤系統的一個重要參考,其系統也可以即插即用。
架構
Zipkin的架構中包含Reporter,Transport,Colletor,Storage,API,UI幾個部分。

其中Reporter整合在每個服務的程式碼中,負責Span的生成,帶內資料(traceid等)的傳遞,帶外資料(span)的上報,取樣控制。
Transport部分為帶外資料上報的通道,zipkin支援http和kafka兩種方式。
Colletor負責接收帶外資料,並插入到集中儲存中。
Storage為儲存元件,適配底層的儲存系統,zipkin提供預設的in-memory儲存,並支援Mysql,Cassandra,ElasticSearch儲存系統。
API提供查詢、分析和上報鏈路的介面。介面的定義見zipkin-api。
UI用於展示頁面展示。

Zipkin將Colletor/Storage/API/UI打包為jar包,可以直接下載執行。
資料模型
這裡的資料模型為zipkin v2版本的資料模型。
Span
trace_id為16位或32位的hex字串,id、parent_id為16位hex字串, 如果沒有父span,parent_id為空。
kind標識服務節點的型別,有通訊模型,cs和生產者消費者模型。
name為span的名字,如rpc呼叫的名字。
timestamp為span生成的時間戳,微秒。
duration為span的持續時間,client端,即為cr-ss的時間。
local_endpoint為本地節點資訊,包含節點名稱,ip與埠。
remote_endpoint為遠端節點資訊。
annotations為事件列表,每個事件用事件時間戳和名字表示。
tags為使用者自定義的kv資訊,如{"user-id":"lidawn"}。
debug表示是否為除錯,該選項會無視取樣概率,使所有span上報。
shared這個欄位暫時沒有太理解==。
message Span {
bytes trace_id = 1;
bytes parent_id = 2;
bytes id = 3;
enum Kind {
SPAN_KIND_UNSPECIFIED = 0;
CLIENT = 1;
SERVER = 2;
PRODUCER = 3;
CONSUMER = 4;
}
Kind kind = 4;
string name = 5;
fixed64 timestamp = 6;
uint64 duration = 7;
Endpoint local_endpoint = 8;
Endpoint remote_endpoint = 9;
repeated Annotation annotations = 10;
map<string, string> tags = 11;
bool debug = 12;
bool shared = 13;
}
message Endpoint {
string service_name = 1;
bytes ipv4 = 2;
bytes ipv6 = 3;
int32 port = 4;
}
message Annotation {
fixed64 timestamp = 1;
string value = 2;
}帶內資料與取樣機制
Zipkin中對帶內資料的傳遞有更加詳細的描述。帶內資料被稱為b3-propagation,包含TraceId,SpanId,ParentSpanId,Sampled四個欄位,每個server在生成span之後會得到TraceId,SpanId,ParentSpanId,穿遞到下游server之後,下游server可以知道自己接下來要生成的span屬於哪一條trace,並處在trace的哪一個位置。
由於帶內資料涉及到程序之間通訊,所以一般是由框架來做帶內資料傳遞,這樣可以減少程式碼的侵入性。如果服務之間使用http通訊,則可以使用X-開頭的自定義http head來傳遞帶內資料。或者如grpc框架,使用clientContext機制在呼叫之間傳遞自定義的欄位。目前開源的zipkin客戶端一般只支援http和grpc兩種方式。
Zipkin的取樣欄位Sampled有四種狀態Defer/Deny/Accept/Debug,取樣的一個重要前提是下游要尊重上游的取樣決定,不能隨意更改sampled欄位。
Defer代表該span的取樣狀態還未決定,下游收到該狀態時則可以對sampled欄位重新賦值。
Deny代表該span不上報。
Accept代表span需要上報。
Debug一般用於開發環境,強制上報。
Root_span的sampled欄位由系統的取樣率來決定。如取樣率為50%,則一半的帶內資料中sampled欄位為accept,其他為deny。
資料埋點及上報過程
根據zipkin的span定義,模擬一個簡單的呼叫過程,分析資料埋點和上報過程。

- server-1發起對server-2的呼叫,生成一個root_span, 生成trace_id,id,parent_id為空,並記錄kind為CLIENT,name,timestamp,local_endpoint(server-1)資訊,並將trace_id,id,parent_id,sampled資訊傳遞給server-2。
- server-2收到server-1的請求,並收到trace_id,id,parent_id,sampled資訊,生成一個相同的span,並記錄kind為SERVER,name,timestamp,local_endpoint(server-2)資訊。
- server-2發起對server-3的呼叫,生成一個新的span,該span為root_span的子span。 並記錄kind為CLIENT,name,timestamp,local_endpoint(server-2)資訊,並將trace_id,id,parent_id,sampled資訊傳遞給server-3。
- server-3收到server-2的請求,並收到trace_id,id,parent_id,sampled資訊,生成一個相同的span,並記錄kind為SERVER,name,timestamp,local_endpoint(server-3)資訊。
- server-3回覆server-2的呼叫,記錄duration,並上報span。
- server-2收到server-3的回覆,記錄duration,並上報span。
- server-2回覆server-1的呼叫,記錄duration,並上報span。
- server-1收到server-2的回覆,記錄duration,並上報span。
整個過程中上報4個臨時的span,最終在zipkin中被合併和儲存為兩個span。
Open-Tracing
由於各種分散式追蹤系統層出不窮,且有著相似的API語法,但各種語言的開發人員依然很難將他們各自的系統和特定的分散式追蹤系統進行整合。在這種情況下,OpenTracing規範出現了。
OpenTracing通過提供平臺無關、廠商無關的API,使得開發人員能夠方便的新增(或更換)追蹤系統的實現。OpenTracing通過定義的API,可實現將監控資料記錄到一個可插拔的tracer上。
Opentracing api的定義可以檢視中文文件, 其並沒有具體的實現。對於現有的系統,如zipkin適配opentracing,則需要額外基於現有的client編寫適配程式碼。
以上。
參考
- Zipkin - https://zipkin.io
- Dapper - https://storage.googleapis.com/pub-tools-public-publication-data/pdf/36356.pdf
- Jaeger - https://www.jaegertracing.io/
- 鷹眼 - https://cn.aliyun.com/aliware/news/monitoringsolution
- Mtrace - https://tech.meituan.com/mt_mtrace.html
- Zipkin-b3-propagation - https://github.com/openzipkin/b3-propagation
- Zipkin-api - https://zipkin.io/zipkin-api/#/default/post_spans
- Zipkin-proto - https://github.com/openzipkin/zipkin-api/blob/master/zipkin.proto
- OpenTracing - https://opentracing.io
- OpenTracing中文 - https://wu-sheng.gitbooks.io/opentracing-io/content/
原文連結:http://lidawn.github.io/2018/12/26/distribute-tracing/