
HIVE瞭解及SQL基礎命令
hive(資料倉庫工具)
Hive是一個數據倉庫基礎工具在Hadoop中用來處理結構化資料。它架構在Hadoop之上,總歸為大資料,並使得查詢和分析方便。並提供簡單的sql查詢功能,可以將sql語句轉換為MapReduce任務進行執行。術語“大資料”是大型資料集,其中包括體積龐大,高速,以及各種由與日俱增的資料的集合。使用傳統的資料管理系統,它是難以加工大型資料。因此,Apache軟體基金會推出了一款名為Hadoop的解決大資料管理和處理難題的框架。
SQL
結構化查詢語言(Structured Query Language)簡稱SQL,是一種資料庫查詢和程式設計語言,用於存取資料以及查詢、更新和管理關係資料庫系統;同時也是資料庫指令碼檔案的副檔名。
結構化查詢語言是高階的非過程化程式語言,允許使用者在高層資料結構上工作。它不要求使用者指定對資料的存放方法,也不需要使用者瞭解具體的資料存放方式,所以具有完全不同底層結構的不同資料庫系統, 可以使用相同的結構化查詢語言作為資料輸入與管理的介面。結構化查詢語言語句可以巢狀,這使它具有極大的靈活性和強大的功能。
常見SQL命令
SELECT 語句
作用:用於從表中選取資料,結果被儲存在一個結果表中
語法:select 列名稱 from 表名稱
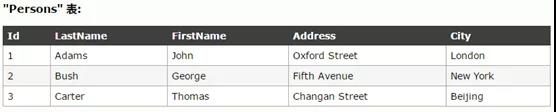
舉例:select LastName from Person 或 select * from Person
WHERE 子句
作用:如需有條件地從表中選取資料,可將 WHERE 子句新增到 SELECT 語句
語法:SELECT 列名稱 FROM 表名稱WHERE 列 運算子 值
舉例:SELECT * FROM Persons WHERE FirstName='John'
ORDER BY 語句
作用:ORDER BY 語句用於根據指定的列對結果集進行排序,預設按照升序對記錄進行排序;如需按照降序,可使用DESC關鍵字
舉例:ORDER BY SELECT LastName, FirstName FROM Persons ORDER BY FirstName
SELECT DISTINCT
作用:關鍵字DISTINCT 用於返回唯一不同的值
語法:SELECT DISTINCT 列名稱 FROM 表名稱
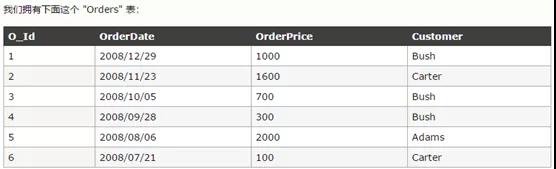
舉例:要從Company列中僅選取唯一不同的值,
SELECTDISTINCT Company FROM Orders
AND 和 OR 運算子
作用: AND 和 OR 可在 WHERE 子語句中把兩個或多個條件結合起來。
如果第一個條件和第二個條件都成立,則 AND 運算子顯示一條記錄。
如果第一個條件和第二個條件中只要有一個成立,則 OR 運算子顯示一條記錄
舉例:使用 AND 來顯示所有姓為 "Carter" 並且名為 "Thomas" 的人
SELECT* FROM Persons WHERE FirstName='Thomas' AND LastName='Carter'
SUM() 函式
作用:SUM 函式返回數值列的總數(總額)
語法:SELECT SUM(column_name) FROM table_name
舉例:
我們希望查詢 "OrderPrice" 欄位的總數
SELECTSUM(OrderPrice) AS OrderTotal FROM Orders
GROUP BY 語句
“GroupBy”從字面意義上理解就是根據“By”指定的規則對資料進行分組,所謂的分組就是將一個“資料集”劃分成若干個“小區域”,然後針對若干個“小區域”進行資料處理
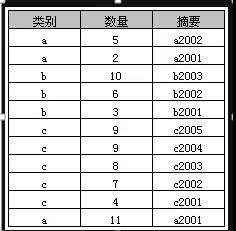
舉例:
select類別, sum(數量) as 數量之和fromA
groupby 類別
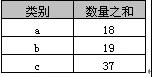
返回結果如下表,實際上就是分類彙總。



例項介紹:
1. 從persona_data_info 表中,查詢job_id=279 的每個gender類別的人數總和
select gender,sum(persona_count) from persona_data_info where job_id=279 group by gender;
2. 從persona_data_city ,persona_city_map兩個表中查詢job_id=279且citycode= map.code
SELECTjob_id,citycode,persona_count,province,region,city_level FROM persona_data_city,persona_city_map where job_id=279 AND persona_data_city.citycode =persona_city_map.`code`;