
莫煩pytorch學習筆記(十一)——Optimizer優化器
阿新 • • 發佈:2019-01-07
建造第一個神經網路——Optimizer優化器
要點
這節內容主要是用 Torch 實踐,中起到的幾種優化器。
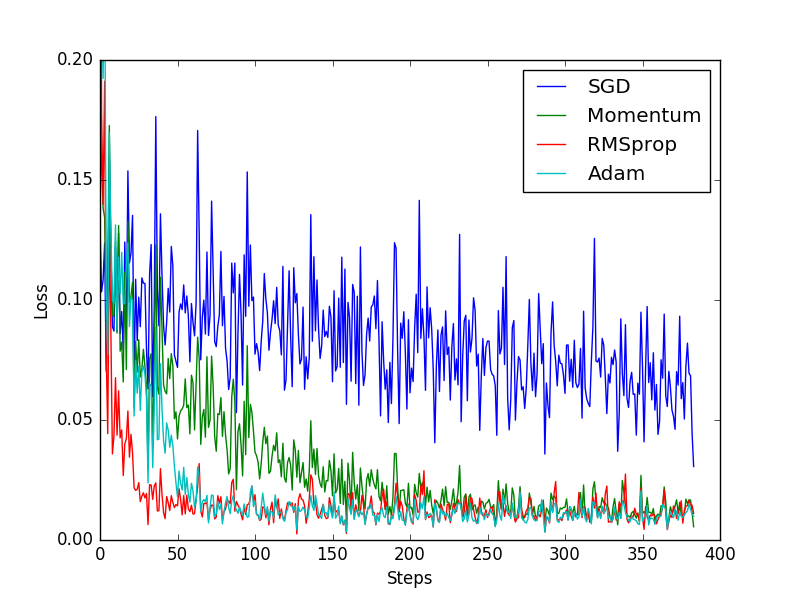
下圖就是這節內容對比各種優化器的效果:
偽資料
為了對比各種優化器的效果, 我們需要有一些資料, 今天我們還是自己編一些偽資料, 這批資料是這樣的:
import torch import torch.utils.data as Data import torch.nn.functional as F import matplotlib.pyplot as plt torch.manual_seed(1) # reproducible LR = 0.01 BATCH_SIZE = 32 EPOCH = 12 # fake dataset x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1) y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size())) # plot dataset plt.scatter(x.numpy(), y.numpy()) plt.show() # 使用上節內容提到的 data loader torch_dataset = Data.TensorDataset(x, y) loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)
每一個優化器優化一個神經網路
為了對比每一種優化器, 我們給他們各自建立一個神經網路, 但這個神經網路都來自同一個 Net 形式.
# 預設的 network 形式 class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.hidden = torch.nn.Linear(1, 20) # hidden layer self.predict = torch.nn.Linear(20, 1) # output layer def forward(self, x): x = F.relu(self.hidden(x)) # activation function for hidden layer x = self.predict(x) # linear output return x # 為每個優化器建立一個 net net_SGD = Net() net_Momentum = Net() net_RMSprop = Net() net_Adam = Net() nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
優化器 Optimizer
接下來在建立不同的優化器, 用來訓練不同的網路. 並建立一個 loss_func 用來計算誤差. 我們用幾種常見的優化器, SGD, Momentum, RMSprop, Adam.
# different optimizers opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR) opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8) opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9) opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99)) optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam] loss_func = torch.nn.MSELoss() losses_his = [[], [], [], []] # 記錄 training 時不同神經網路的 loss
訓練/出圖
接下來訓練和 loss 畫圖
for epoch in range(EPOCH):
print('Epoch: ', epoch)
for step, (b_x, b_y) in enumerate(loader):
# 對每個優化器, 優化屬於他的神經網路
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.data.numpy()) # loss recoder即上面那張圖。
SGD 是最普通的優化器, 也可以說沒有加速效果, 而 Momentum 是 SGD 的改良版, 它加入了動量原則. 後面的 RMSprop 又是 Momentum 的升級版. 而 Adam 又是 RMSprop 的升級版. 不過從這個結果中我們看到, Adam 的效果似乎比 RMSprop 要差一點. 所以說並不是越先進的優化器, 結果越佳. 我們在自己的試驗中可以嘗試不同的優化器, 找到那個最適合你資料/網路的優化器.