
深入理解GlusterFS之資料均衡
GlusterFS是一個免費的開源分散式檔案系統,具有無中心節點、堆疊式設計、全域性統一名稱空間、高可用、高效能和橫向擴充套件等特點,在業界被廣泛使用。本文主要介紹GlusterFS的資料均衡功能(即rebalance),內容涉及資料均衡的產生背景、使用場景、基本原理、程式實現剖析、操作命令實踐、存在的問題以及需要優化的地方等,希望能夠拋磚引玉,為讀者深入學習和理解GlusterFS起到一定的參考作用。
本文假定讀者已經熟悉了GlusterFS的一些基本概念術語以及架構組成。
1. 問題引入
1.1. 問題背景
在當今大資料時代,人們每天都在產生大量的資料,其中需要持久化的資料也越來越多,而一臺計算機的儲存容量是比較有限的,儘管可以為其增加更多的記憶體和磁碟,但再怎麼增加也是有上限的,因此分散式儲存系統便應運而生。分散式儲存系統就是利用多個獨立的計算機來解決單個計算機無法解決的儲存資料量大的問題,對於這種系統而言,擴容(增加節點)和縮容(減少節點)是不可避免會遇到的情況,GlusterFS、Ceph、HDFS和OpenStack Swift等分散式儲存系統均如此。
以擴容為例,這是一個十分常見的場景,隨著資料量的增多,必然要對系統進行擴容來滿足實際需求,而擴容系統後會出現叢集內資料分佈不均衡的情況,已有資料只存在原有節點上,新增節點只會儲存後續新增的資料,這樣發展下去會造成原有節點負載過高,而新增節點可能還有很多可用空間,這就產生了不均衡(如圖1),為了解決該問題,很多分散式儲存系統都支援資料均衡(即rebalance)功能,GlusterFS、Ceph、HDFS和Swift等也是如此,執行資料均衡後,可以使叢集中的資料進行重新分佈,並且分佈的更加均勻(如圖2)。
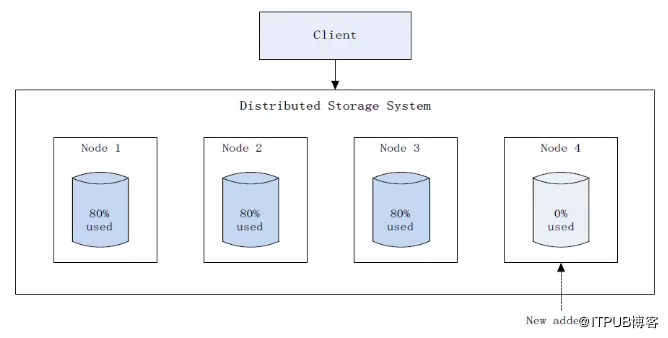
圖1 擴容後資料均衡前示意圖
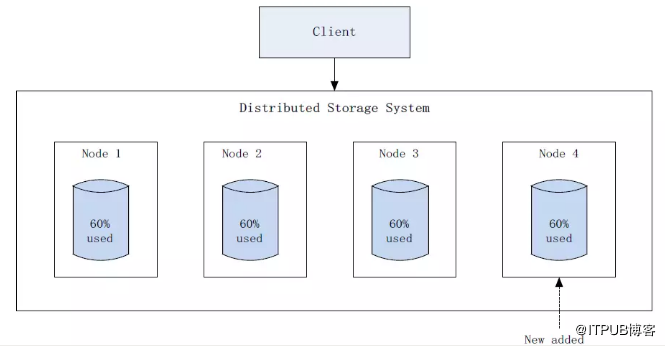
圖2 擴容後資料均衡後示意圖
本文主要討論GlusterFS資料均衡,接下來先介紹下GlusterFS資料均衡涉及到的相關內容,尤其是DHT(Distributed Hash Table)部分,因為資料均衡和DHT結合的非常緊密。
GlusterFS使用DHT模組來聚合多臺機器的物理儲存空間,形成一個單一的全域性名稱空間,並使用卷(Volume)這一邏輯概念來表示這樣的空間。每個卷可以包含一個或多個子卷(Subvolume),子卷也可稱為DHT子卷,同樣是一個邏輯概念,一個子卷可以是單個brick、一個副本卷(Replica)或一個EC(Erasure Coding)卷,而副本卷和EC卷自身又都是由一組brick構成。而brick則是GlusterFS中的最基本儲存單元,表示為一個機器上的本地檔案系統匯出目錄。例如,GlusterFS分散式副本卷(雙副本)的簡化組成如圖3所示。

圖3 GlusterFS分散式副本卷示意圖
DHT模組使用基於32位雜湊空間的一致性雜湊演算法(Davies-Meyer演算法)計算檔案的雜湊值,並將檔案儲存到其中一個DHT子卷,而目錄是GlusterFS中雜湊分佈(layout)的基本單位,會在所有DHT子卷中都建立,雜湊範圍儲存在目錄的擴充套件屬性中。根據DHT演算法原理,每一個DHT子卷的目錄都會被分配一個雜湊子空間,即32位雜湊空間(十六進位制表示為0x00000000~0xffffffff)中的一段雜湊範圍,例如,0x00000000~0x55555554。
為了在叢集內均衡地分佈檔案,GlusterFS在每個目錄層次上重新劃分一次雜湊空間,並且子目錄層和父目錄層的雜湊分佈並無關聯。而檔案的實際儲存位置,只由其父目錄上的雜湊範圍決定,與其他目錄層次無關。子卷的目錄雜湊空間分佈示意圖如圖4所示。
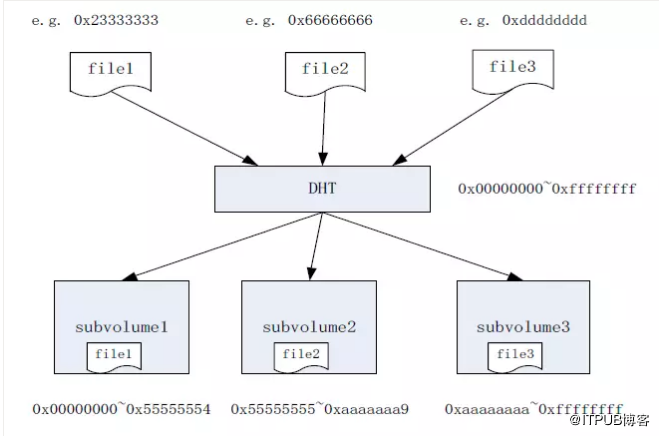
圖4 GlusterFS卷目錄雜湊空間分佈示意圖
根據以上介紹,可以概括GlusterFS中檔案訪問的一般流程如下:
1、首先,DHT根據檔名稱計算出一個雜湊值(假設圖4中file1雜湊值為0x23333333);
2、其次,根據該雜湊值找到其所在的目錄雜湊子空間(即0x00000000~0x55555554),也就是找到了對應的DHT子卷(即subvolume1);
3、最後,訪問對應的DHT子卷(即subvolume1)。
1.2. 使用場景
理想情況下,在一個GlusterFS卷中,會盡可能地在DHT子卷之間均衡地儲存檔案,這樣可以充分發揮GlusterFS的高可靠性、高可用性和高效能。但現實中總有一些特殊情況存在,比如,叢集需要擴容等,從而導致檔案分佈不均勻,因此也就需要進行資料均衡。
那麼GlusterFS中資料均衡具體指的是什麼呢?簡而言之,GlusterFS資料均衡就是必要的時候,在DHT各子卷之間遷移資料的過程,其目的是使資料在叢集中的不同節點之間儘量均勻分佈,從而使得叢集處於最佳狀態。
那麼問題來了,何時才是資料均衡的“必要的時候”呢?主要有如下兩類場景:
(一)擴容或縮容檔案系統
(二)重新命名檔案
1.2.1 擴容或縮容
擴容或縮容GlusterFS按照子卷為單位來做增減,這會使得DHT子卷的數量發生變化,從而導致每個子卷的目錄雜湊範圍會被重新計算和分配,即每個子卷的目錄雜湊範圍會改變。而檔案的雜湊值並沒有變化,如果此時有一些檔案的雜湊值落到了其他子卷(即不同於檔案當前所在子卷),那麼這些檔案應該被遷移到正確的子卷。
值得注意的是,在擴容GlusterFS後,需要手動執行gluster rebalance命令來觸發資料均衡功能。前文已經介紹了,擴容後會帶來新舊節點資料不均衡的問題,進一步發展可能會導致舊節點負載過高而出現效能問題,甚至最終影響到資料可靠性和可用性,因此,擴容後進行資料均衡是非常必要的。
而在縮容GlusterFS後,並不需要手動執行命令,縮容時會自動觸發執行資料均衡過程,這是因為如果縮容時沒有自動進行資料均衡,那麼被剔除掉的節點或子捲上的資料將不再可用,從而會導致資料的丟失,這對於使用者來說是不可接受的,因此資料均衡在縮容時是不可或缺的,程式實現採用自動觸發方式也就理所當然了。
下面分別給出擴容和縮容後,並且執行資料均衡後的子卷目錄雜湊空間分佈變化示意圖,如圖5和圖6所示。

圖5 擴容後子卷的目錄雜湊空間分佈變化

圖6 縮容後子卷的目錄雜湊空間分佈變化
1.2.2. 重新命名檔案
在GlusterFS中,重新命名檔案會導致該檔案的雜湊值發生變化,假設此時DHT子卷的數量並沒有變化,即沒有擴容和縮容,那麼每個子卷的目錄雜湊範圍也就沒有變化,根據DHT演算法判斷該檔案的新儲存位置,如果檔案的新儲存位置與當前所在子卷不同(如圖7),則該檔案應該被遷移到正確的子卷。
重新命名檔案後,系統不會自動進行均衡,而是會在目標子捲上產生一個同名的內容為空的連結檔案(Link file),該連結檔案的擴充套件屬性上會記錄檔案的實際儲存位置(也就是原來所在的子卷)。假設此時客戶端訪問重新命名後的檔案,根據前面介紹的檔案訪問流程,則DHT會先將請求轉到雜湊計算得出的子捲去查詢該檔案,並獲取到連結檔案資訊,DHT模組懂得連結檔案的意義,從連結檔案資訊中得出檔案的實際位置,然後再到實際的子卷獲取檔案。
可以發現,如果重新命名檔案後不進行資料均衡,則客戶應用程式在訪問檔案時會增加額外的步驟,從而造成一定程度的訪問延遲,當系統有大量連結檔案時,則會導致訪問效能的大幅下降,對應用程式造成影響。而執行資料均衡後則會將檔案遷移到正確的位置,消除了連結檔案帶來的訪問延遲問題,因此資料均衡對於檔案重新命名來說也是很有必要的。
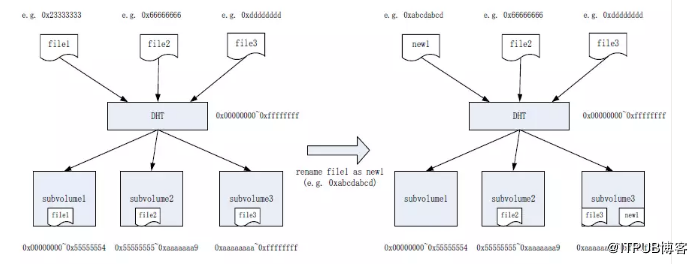
圖7 重新命名檔案導致的檔案位置變化
2. 基本原理
前面簡要介紹了DHT模組的基本作用和檔案的一般訪問流程,目的是為了讀者能夠更好地理解GlusterFS資料均衡。本節將介紹當前資料均衡功能是如何工作的。
隨著GlusterFS專案的發展,其資料均衡功能也在不斷的完善,其最初的工作機制和現在的工作機制已經相去甚遠,下面高度概括了資料均衡當前的流程,如圖8所示:
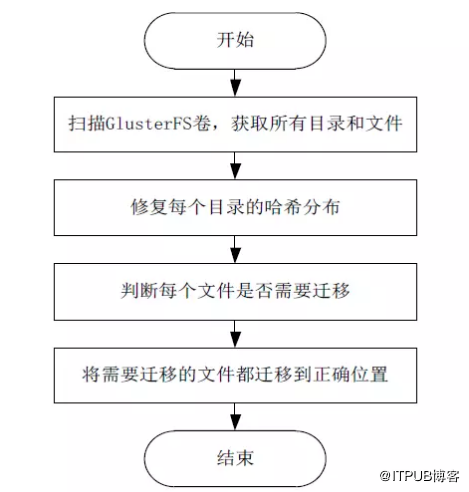
圖8 資料均衡的概括流程
為了便於理解,以上流程是站在叢集的視角,對資料均衡流程的高度總結,具體如下:
1、掃描整個GlusterFS卷,獲取到卷中所有目錄和檔案;
2、對每一個目錄,修復該目錄的雜湊分佈;
3、對每一個檔案,判斷該檔案是否需要遷移;
4、對於需要遷移的檔案,將其遷移到正確的位置。
可以看到,概括總結後的流程非常簡單,但是實際程式碼實現卻比較複雜,一方面是考慮了各種異常情況後,會有大量的細節需要處理,另一方面是資料均衡功能的程式碼與DHT的程式碼結合的非常緊密,從而增加了程式碼的複雜度,不便於理解。後面的實現剖析部分會具體介紹程式碼級別的處理流程。
本節接下來先介紹資料均衡功能稍微細化後的工作機制,然後再給出一個例項分析,用於幫助讀者理解。
2.1. 工作機制
在GlusterFS的資料均衡功能實現中,每個節點採用單程序多執行緒的實現方式,其中,主執行緒使用類似深度優先演算法,從根目錄開始,遍歷GlusterFS卷在本節點上的目錄並修復其雜湊分佈,同時爬取目錄下的所有檔案,根據演算法將相應檔案放到遷移佇列裡,並通知等待的工作執行緒進行遷移處理。
而工作執行緒則負責檢查遷移佇列裡是否有檔案待遷移,若佇列不空則遷移其中的檔案,一次遷移一個檔案;若佇列為空則自我睡眠,等待主執行緒喚醒。
主執行緒的檔案爬取工作和工作執行緒的資料遷移工作同時進行,並且支援多個執行緒並行遷移檔案。當主執行緒完成修復目錄和爬取檔案工作後,將等待其他工作執行緒完成資料遷移工作,當遷移佇列裡的所有檔案都被遷到正確位置後,所有工作執行緒結束退出,主執行緒收到所有工作執行緒的退出訊息後,做一些清理工作,然後結束本節點的資料均衡程序。
下面給出稍微細化後的資料均衡主執行緒和遷移執行緒的工作流程如圖9和圖10所示。
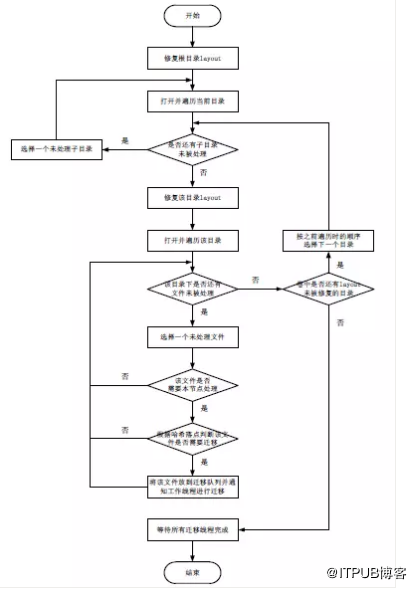
圖9 資料均衡主執行緒的工作機制
啟動資料均衡功能後,每個節點的資料均衡程序的主執行緒都按照上圖流程進行,並且每個節點只處理屬於本地brick上的檔案,上述流程簡要說明如下:
1、首先,修復卷的根目錄雜湊分佈;
2、開啟並遍歷當前目錄,獲取到所有子目錄;
3、對於當前目錄中的每個子目錄,按照如下步驟遞迴處理:
3.1、如果有未被處理的子目錄,從中選擇一個目錄,並返回到步驟2處理該子目錄;否則,下一步;
3.2、所有子目錄都已經被處理過了或者沒有子目錄,修復當前目錄的雜湊分佈;
3.2.1、開啟並遍歷當前目錄,獲取所有檔案;
3.2.2、對於當前目錄中的每個檔案,按照如下步驟處理:
3.2.2.1、如果有未被處理的檔案,從中選擇一個檔案,進入下一步,否則,轉到步驟3.2.2.4;
3.2.2.2、如果檔案應該由本節點處理,則進入下一步,否則,轉到步驟3.2.2;
3.2.2.3、如果檔案滿足遷移條件,則將檔案放到一個遷移佇列,並通知遷移執行緒執行遷移,否則,返回步驟3.2.2;
3.2.2.4、當前目錄的所有檔案已被處理過了,轉入下一步;
4、如果本節點還有目錄的雜湊分佈未被修復,選擇其中的一個目錄(按照之前遍歷時的順序),並轉到步驟3,否則,進入下一步;
5、等待所有遷移執行緒完成資料遷移工作,然後做些清理工作,最後結束資料均衡程序。
工作執行緒的處理流程如下:
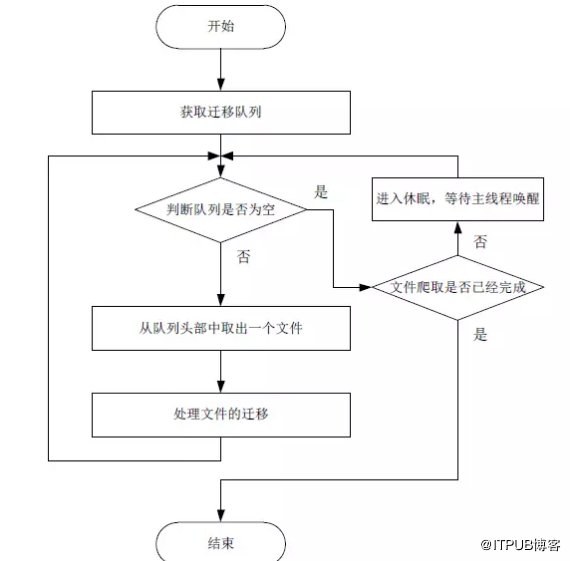
圖10 資料均衡遷移執行緒的工作機制
資料均衡的遷移執行緒處理流程簡介如下:
1、獲取到資料均衡程序的遷移佇列;
2、檢查佇列是否為空;
2.1、如果佇列不空,則從佇列頭部取出一個檔案,並處理該檔案的具體遷移過程,遷移完成後返回步驟2;
2.2、如果佇列為空,則繼續判斷主執行緒是否已經完成對整個卷的檔案爬取;
2.2.1、如果主執行緒未完成檔案爬取,則遷移執行緒進入休眠狀態,等待主執行緒的喚醒;
2.2.2、如果主執行緒已完成檔案爬取,則退出執行緒。
2.2. 例項分析
以上內容可能有些晦澀難懂,為了便於理解,下面舉個例子,假設GlusterFS卷中的目錄檔案佈局如圖11所示:
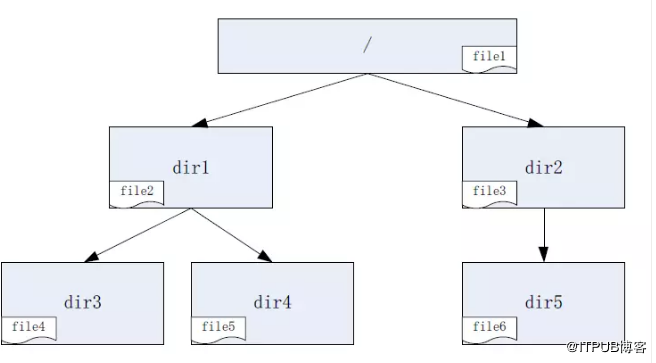
圖11 GlusterFS卷的目錄檔案佈局示意圖
根據上述資料均衡的工作機制,其處理順序如下:
1、資料均衡程序啟動,主執行緒首先修復根目錄的雜湊分佈;
2、開啟並遍歷根目錄,獲取到檔案file1、目錄dir1和dir2;
3、選擇根目錄的一個子目錄,假設選擇dir1;
4、開啟並遍歷dir1,獲取到檔案file2、目錄dir3和dir4;
5、選擇dir1目錄的一個子目錄,假設選擇dir4;
6、開啟並遍歷dir4,獲取到檔案file5;
7、因為dir4沒有子目錄,所以不再進行遞迴遍歷,而是修復dir4的雜湊分佈;
8、遍歷dir4,獲取其下所有檔案,本例為file5;
9、判斷file5是否應該由本節點處理,假設由本節點處理;
10、判斷file5是否需要遷移,假設需要遷移;
11、將file5放到遷移佇列,通知工作執行緒進行遷移(遷移執行緒負責處理具體的遷移過程);
12、dir4目錄下沒有其他檔案需要處理了,即對dir4的處理完成了,按照之前的遍歷順序,繼續處理下一個雜湊分佈未修復的目錄,也就是優先選擇與dir4同一層次的其他目錄;
13、選擇dir3,由於dir3也沒有子目錄,修復dir3的雜湊分佈;
14、開啟並遍歷dir3,獲取到檔案file4,然後同file5的處理流程一樣,不再贅述;
15、處理完dir3後,則當前同一層次的目錄都處理完了(即dir3和dir4),開始處理當前目錄層次的父目錄,即dir1;
16、完成對dir1的修復目錄、遍歷檔案和遷移檔案,具體步驟同dir4,不再贅述;
17、接著上面的步驟3,對dir1的同一層次的其他目錄(本例為dir2)進行處理,過程與dir1類似,即先修復dir5雜湊分佈,遷移其下檔案file6,再修復dir2雜湊分佈,遷移檔案file3,具體過程不再贅述;
18、最後處理根目錄的檔案file1,不再贅述;
19、資料均衡程序等待所有遷移執行緒完成資料遷移,然後正常結束。
以上處理順序的簡化示意圖如下圖12所示:

圖12 目錄處理與檔案遷移順序
總結一下,資料均衡的當前工作機制就是多個節點同時參與處理,每個節點以單程序多執行緒的方式,同時掃描檔案和遷移檔案,並且掃描檔案和遷移檔案分別由不同執行緒處理,每個節點可以並行遷移檔案,相比以往的資料均衡流程,大大增加了並行度,並且更加可擴充套件,使得叢集資料均衡時的系統負載分佈的更加均勻,同時效率也更高了。
3. 最佳實踐
GlusterFS為資料均衡功能提供了相應的命令列程式,通過該程式可以和glusterd服務程序之間進行通訊,用於查詢資料均衡狀態資訊和控制資料均衡相關操作,可以輔助相關人員更好地控制管理資料均衡過程。
3.1. 操作命令
命令格式為:
gluster volume rebalance <VOLNAME> {{fix-layout start} | {start [force]|stop|status}}
常用命令介紹如下:
(1)只修復目錄layout命令
gluster v rebalance VOL_NAME fix-layout start
例如:
(2)開啟資料均衡命令
gluster v rebalance VOL_NAME start
例如:
也可以使用強制選項,這樣可以忽略一個容量限制,即不帶強制選項時會比較檔案所在的原子卷和目標子卷的剩餘容量,如果原子卷大於目標子卷,則不遷移該檔案。使用強制選項則會跳過這個限制,命令如下:
gluster v rebalance VOL_NAME start force
例如:
(3)設定資料均衡遷移速度
為了良好的遷移效能,資料均衡程序中使用了多執行緒,並且支援並行遷移多個檔案,但是這樣佔用一定的系統資源,對儲存系統本身效能帶來一定影響,因此,GlusterFS提供了相關控制命令,用於調控實際遷移速度的快慢,目前主要有三種模式,lazy、normal和aggressive。顧名思義,lazy是懶惰的慢速模式(較少執行緒遷移),normal是正常模式(執行緒數量適中),aggressive是激進模式(較多執行緒遷移),預設採用normal模式,可以根據實際需要去做具體設定,命令格式如下:
gluster volume set <VOLNAME> rebal-throttle lazy|normal|aggressive
例如:
(4)檢視資料均衡狀態等資訊
gluster v rebalance VOL_NAME status
例如:
可以檢視到資料均衡在每個節點的當前狀態(status)、運行了多久(run time)、掃面的檔案數量(scanned)、已經遷移的檔案數量(rebalanced-files)、已經遷移的資料量(size)、遷移失敗的檔案數量(failures)和跳過的檔案數量(skipped)。
(5)停止資料均衡程序
gluster v rebalance VOL_NAME stop
例如:
3.2. 均衡建議
當叢集需要進行資料均衡時,建議參考如下內容:
(1)儘量提前做規劃,例如,別等到叢集儲存空間快用完了才擴容,一方面會導致時間緊迫,部署準備時間匆忙,容易忙中出錯;另一方面也容易導致舊節點之間的檔案遷移失敗,最好預留出一定的剩餘空間;
(2)確保叢集所有節點處於正常狀態,卷處於啟動狀態,glusterd服務程序和brick程序狀態正常,節點之間通訊正常;
(3)檢查GlusterFS卷中是否有檔案損壞,如果有,則先對其進行修復;
(4)在執行資料均衡時,確保叢集沒有自修復操作正在進行,否則會影響到資料正確性和遷移效率;
(5)如果允許的話,在執行資料均衡前,停止客戶端應用,可以提高均衡效率;
(6)先執行fix-layout操作,再執行資料遷移,可以在一定程度上提高遷移效率;
(7)根據實際需要選擇遷移模式,預設是normal模式,aggressive模式可能佔用的系統資源較多,進而影響到儲存效能;
(8)資料均衡過程中,通過命令列程式定時關注均衡的當前狀態,以便及時發現問題並做相應調整;
(9)當叢集規模較大時,可能偶爾會出現某個節點均衡失敗的情況,一般重新開始執行均衡即可;
(10)如果執行資料遷移對應用程式影響較大,可以只執行fix layout,這樣可以只修復目錄的雜湊分佈,並不會實際遷移檔案,此時新檔案可以儲存到新增節點(或brick)上,之後再找適當時機(系統比較空閒的時候)執行資料遷移操作。
4. 實現剖析
GlusterFS資料均衡功能的程式碼與DHT層程式碼緊密結合在一起,主要的功能邏輯程式碼位於dht-rebalance.c檔案中,剩餘部分程式碼包含在DHT層的其他程式碼邏輯中。在資料均衡程式碼的實現中,採用了syncop框架,這是一套基於協程的合作式多工同步框架,它的存在簡化了資料均衡功能的實現。
前面的工作機制部分介紹了資料均衡的基本流程,本節則主要側重程式碼級別的討論,首先簡要介紹資料均衡功能中涉及的程序互動,然後討論syncop框架,最後給出資料均衡的幾個關鍵流程。限於時間原因,忽略了很多程式碼處理細節,留給讀者自行分析實踐。
4.1. 程序互動過程
下面以命令列手動觸發資料均衡為例,簡要說明其中涉及的程序互動步驟,在命令執行的節點上,簡化的程序互動過程如下圖13所示。
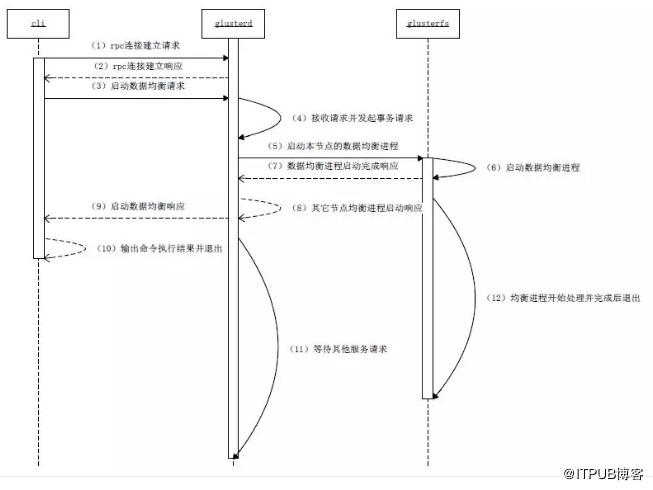
圖13手動觸發資料均衡的程序互動過程
互動過程主要涉及到cli、glusterd和glusterfs三個程序,簡要說明如下:
1、在叢集的一個節點上,執行gluster rebalance start命令(即啟動cli程序),該命令向本節點glusterd服務程序發起rpc連線建立請求;
2、本節點glusterd程序接收到該請求,與之建立rpc連線並回復響應;
3、cli命令程序收到rpc連線建立響應,然後向本節點glusterd程序發起啟動資料均衡請求;
4、本節點glusterd程序收到請求後,做一些初始化等準備工作,並以事務方式向叢集其他相關節點(當前GlusterFS卷的所有其他節點)的glusterd程序,發起啟動資料均衡的請求;
5、與此同時,本節點glusterd程序啟動本節點的資料均衡程序;
6、資料均衡程序以gluster客戶端程序(即glusterfs)的形式啟動,該程序使用的客戶端配置檔案(即.vol檔案)與正常客戶端配置檔案不同,去掉了其中的效能相關模組;
7、本節點的資料均衡程序啟動完畢後,返回響應給glusterd程序;
8、本節點glusterd程序等待並接收所有其他相關節點的響應,即資料均衡程序已經啟動完畢的訊息;
9、本節點glusterd程序返回啟動資料均衡的響應,通知命令列程式啟動已經完成;
10、命令列程式從本地glusterd程序接收響應,列印輸出命令執行結果,然後退出cli程式;
11、本節點glusterd程序完成了對命令列請求的處理,等待其他請求到來;
12、本節點資料均衡程序開始處理,具體處理流程參見前文中的工作原理部分,均衡程序在處理完成後退出。
4.2. syncop框架
在GlusterFS的幾乎所有執行緒中,檔案操作(fops)都是非同步執行的,使用的基本原語是STACK_WIND和STACK_UNWIND這一類巨集定義,這類巨集定義像呼叫函式和回撥函式一樣工作,有效地實現了叢集和並行環境下的檔案操作。
但在資料均衡功能中,如果直接採用這類巨集定義實現相關操作,則會使程式變得非常複雜而不好控制,因此,GlusterFS開發人員引入了syncop同步框架,並廣泛使用於程式中,以方便資料均衡功能的實現,例如,用於檔案爬取程式和流程控制等方面。
4.2.1. syncop術語
-
syncenv
Syncenv是同步環境物件,該物件擁有一個可排程的工作執行緒池,同步任務(synctask)在該環境中排程執行。
-
synctask
Synctask是同步任務物件,可以理解為一對C語言函式指標,即呼叫函式指標synctask_fn_t(如syncop_lookup)和回撥函式指標synctask_cbk_t(如syncop_lookup_cbk)。
Synctask有兩種操作模式:
(1)呼叫執行緒等待synctask完成;
(2)呼叫執行緒排程synctask,使之繼續執行;
Synctask能夠確保一個函式呼叫完成後,其對應的回撥函式也會被執行到。
4.2.2. synctask生命週期
一個synctask的完整生命週期包括如下幾個階段:
-
CREATED
當呼叫synctask_create或synctask_new函式建立一個synctask時;
-
RUNNABLE
當把synctask加入到syncenv的runq佇列時;
-
RUNNING
當syncenv的工作執行緒呼叫synctask_switch_to函式時;
-
WAITING
當呼叫synctask_yield函式將一個synctask加入到syncenv的waitq佇列時;
-
DONE
當一個synctask完成執行時。
以上幾個階段的狀態轉換如下圖14所示:
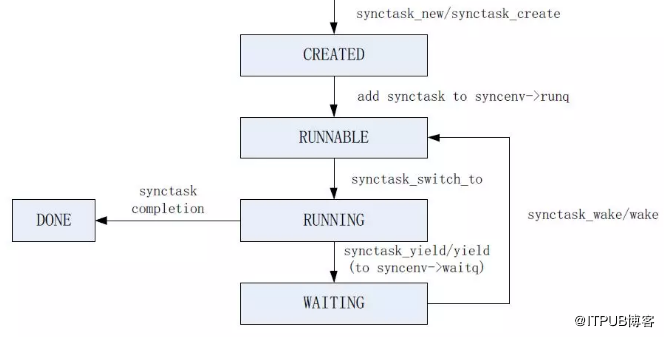
圖14 synctask狀態轉換
需要注意的是,在synctask的生命週期內,並不能保證該任務是一直在同一個執行緒中執行,每次呼叫synctask_yield函式時,可能會使其運行於一個不同的執行緒中。
總之,可以這樣簡單地理解,使用syncop框架執行一個任務時(例如syncop_opendir函式用於開啟目錄),呼叫函式會等待該任務完成後(目錄已被開啟),再繼續往下進行。相對而言,syncop框架大大簡化了資料均衡功能的實現。
4.3. 關鍵處理流程
每個節點的資料均衡程序,在處理流程上都是一樣的,下面結合實際程式碼,分別簡要分析一下資料均衡功能的主執行緒與遷移執行緒的處理流程。
主執行緒的入口函式是gf_defrag_start,該函式主要就是使用syncop框架建立一個synctask,用於本次資料均衡的處理工作。建立synctask同步任務時,指定了實際處理函式gf_defrag_start_crawl及其完成後的回撥函式gf_defrag_done,下面首先給出從gf_defrag_start_crawl函式開始的一些主要處理流程,如圖15、圖16和圖17所示。然後再列出遷移執行緒的主要處理流程,如圖18所示。
4.3.1. 主執行緒處理流程
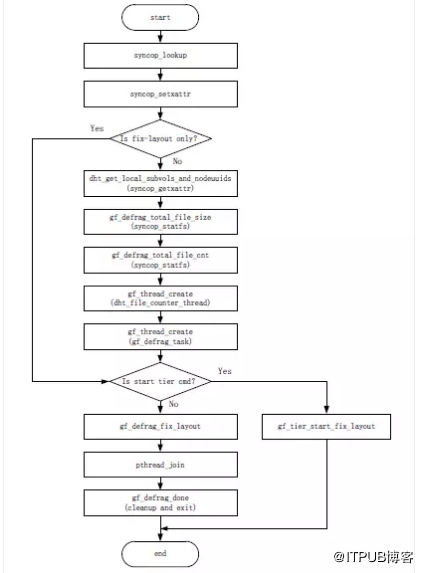
圖15 gf_defrag_start_crawl函式處理流程
1、呼叫syncop_lookup,查詢根目錄的相關資訊,位置、元資料和父目錄等資訊;
2、呼叫syncop_setxattr,修復根目錄的雜湊分佈;
3、根據命令型別判斷,如果命令型別只是修復目錄雜湊分佈,則跳過遷移檔案相關函式,轉到步驟9;否則,下一步;
4、呼叫dht_get_local_subvols_and_nodeuuids,其內部使用了同步函式syncop_getxattr,獲取本節點參與的子卷和每個相關子卷中涉及到的節點的uuid資訊,並且在每個節點上的相同子卷返回的節點uuid的順序一致;
5、呼叫gf_defrag_total_file_size,其內部使用了syncop_statfs,獲取本節點參與子卷的總共檔案大小;
6、呼叫gf_defrag_total_file_cnt,其內部使用了syncop_statfs,獲取本節點參與子卷的總共檔案數量;
7、呼叫gf_thread_create,建立一個檔案計數執行緒,用於在資料均衡過程中統計檔案遷移數量,方便使用者命令列檢視;
8、呼叫gf_thread_create,根據節點cpu活動processor的數量,建立多個遷移執行緒,負責具體檔案遷移工作,其入口函式為gf_defrag_task,後面會給出該函式處理流程(圖18);
9、根據命令型別判斷,如果命令型別是開啟分層(tier),則呼叫tier相關處理函式,由於本文不考慮tier相關操作,在此略過;否則,下一步;
10、呼叫gf_defrag_fix_layout,開始進行目錄的修復與檔案的爬取,這也是主執行緒的主要工作,下面會單獨給出該函式的處理流程(圖16);
11、在修復目錄和爬取檔案完成後,呼叫pthread_join,等待所有遷移執行緒完成;
12、所有遷移執行緒已經完成並返回,做些清理工作,並呼叫gf_defrag_done,結束均衡程序。
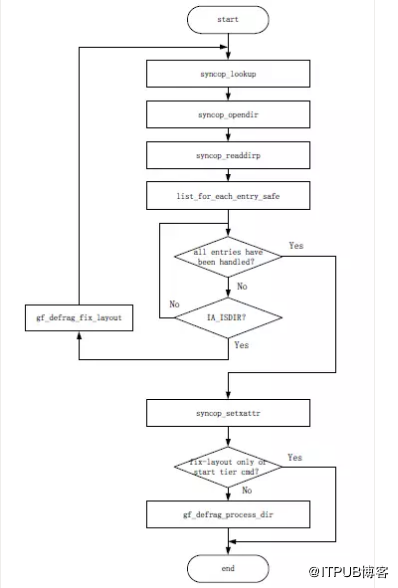
根據以上流程的說明,並結合前面介紹的工作機制等內容,要理解下面給出的gf_defrag_fix_layout和gf_defrag_process_dir函式處理流程並不會很難,具體過程不再贅述。
圖16 gf_defrag_fix_layout函式處理流程
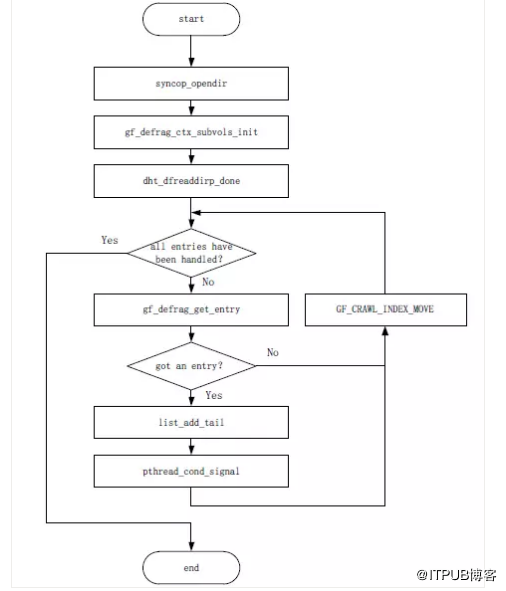
圖17 gf_defrag_process_dir函式處理流程
4.3.2. 遷移執行緒處理流程
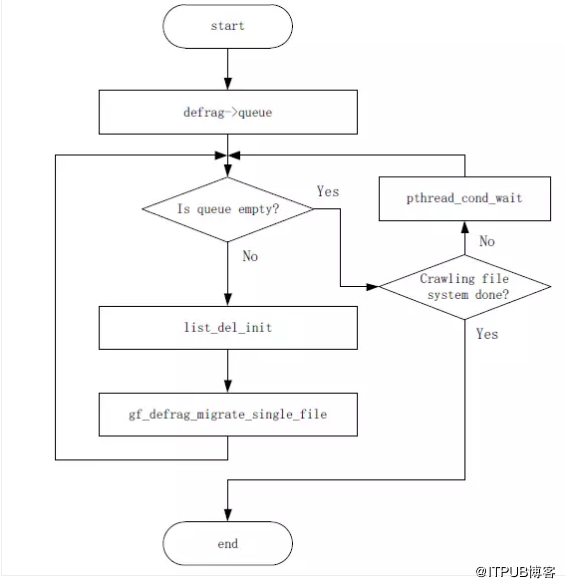
圖18 gf_defrag_task函式處理流程
多個遷移執行緒同時執行,每個執行緒的處理流程都由gf_defrag_task函式負責,簡要說明如下:
1、獲取待遷移檔案的佇列defrag->queue;
2、進入如下while迴圈模式;
3、判斷佇列是否為空,如果不空,下一步;否則,轉到步驟7;
4、呼叫list_del_init,從佇列頭取出一個檔案,並更新相關計數;
5、呼叫gf_defrag_migrate_single_file,該函式負責單個檔案遷移的整個過程,包括判斷是否需要遷移、資料內容遷移、各種屬性遷移、特殊檔案處理和遷移後的清理工作等內容,此部分內容需要讀者自行分析,不再贅述;
6、gf_defrag_migrate_single_file函式完成後,返回到步驟3;
7、判斷檔案爬取任務是否完成,如果沒完成,則呼叫pthread_cond_wait,等待新檔案遷移任務到來的通知;否則,下一步;
8、遷移任務都已完成,執行緒返回。
5. 問題與優化
儘管資料均衡功能經過了不斷的完善,已經具有了良好的效能和擴充套件性,同時大大加快了擴容或縮容後集群資料均衡的進度,但仍然存在一些限制和問題,具體說明如下:
(1)資料遷移速度可進一步提升
原因是在遷移資料的時候,工作執行緒在讀取原始檔案和寫入目標檔案是序列的,如果能夠將兩者有效的分開獨立進行,則可以進一步提升遷移速度;
(2)擴容或縮容時的資料遷移量大
在增加brick或刪除brick的時候,需要對整個卷做資料均衡,這樣一來,增加或刪除很少brick時,也會觸動整個叢集均衡一次,給人一種牽一髮而動全身的感覺,並且需要遷移的資料量較大,而在OpenStack Swift的資料均衡中則採用了帶有虛擬節點的一致性雜湊,可以一定程度減少資料的遷移量,因此可以考慮借鑑這種做法。
(3)資料遷移速度控制能力較弱
雖然目前命令列有三種模式(lazy、normal和aggressive),用於控制遷移速度,但還是屬於比較粗略的控制,當有大量檔案遷移時,還是會佔用較多的系統資源,影響到儲存系統性能。
(4)程式碼存在bug
例如,在GlusterFS的3.12系列之前的版本中,對分散式EC卷做擴容後做資料遷移的時候,每組EC卷只有一個節點在遷移檔案,組內其他節點並沒有參與該過程,這是和其預期工作機制是不相符的,並且影響了一部分檔案的遷移。
上面只是列出了資料均衡目前存在一些限制,可能還有其他問題,等待讀者去發現和解決。總之,未來還是有很多工作要做的,結合GlusterFS社群的討論,列出主要內容如下:
(1)優化遷移速度,遷移資料的時候,讀檔案和寫檔案並行化;
(2)更精細地控制資料遷移,根據實際需要靈活地調控遷移速度;
(3)優化目錄雜湊分佈,減少每次擴容或縮容後需要遷移的資料量;
(4)支援遷移暫停功能,再次開啟後可以繼續從當前暫停位置開始遷移;
(5)在資料均衡程序中增加效能模組(xlator),提高遷移效率;
(6)修復資料均衡程式碼中的bug。
6. 總結與展望
本文介紹了GlusterFS當前的資料均衡功能,內容包括資料均衡的產生背景、使用場景、基本原理、程式實現剖析、操作命令實踐、存在的問題以及需要優化的地方等,同時結合例項說明了資料均衡的工作機制。
GlusterFS資料均衡功能還在不斷的完善中,相信未來的資料均衡功能一定會更加高效和可控,並且佔用較少的系統資源。
由於時間和精力有限,文中省略了很多細節,也包括一些重要的演算法和流程,期望讀者能夠給予補充,同時理解不正確的地方也在所難免,歡迎指正。
(文章來自: 大魏分享 郭忠秋)
參考資料
[1] https://docs.gluster.org/
[2] http://pl.atyp.us/hekafs.org/index.php/2012/03/glusterfs-algorithms-distribution/
[3] http://staged-gluster-docs.readthedocs.io/en/release3.7.0beta1/Features/rebalance/
[4] https://github.com/gluster/glusterfs-specs/blob/master/done/GlusterFS%203.7/Improve%20Rebalance%20Performance.md
[5] glusterfs v3.12.9 source code
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/31547898/viewspace-2168800/,如需轉載,請註明出處,否則將追究法律責任。