
巧用C#webbrowser以及Application.DoEvents()實現採集動態網頁的爬蟲機器人
http://www.cnblogs.com/finallyliuyu/archive/2010/10/28/1863691.html
作者:finallyliuyu (轉載請註明作者:finallyliuyu,出處:部落格園)
從事網路資料抓取採集從本科畢設算起已有一年多的時間,最開始是針對靜態網頁,寫正則表示式,從網路上抓取資訊。但是隨著工作的深入,
發現很多網頁單單用正則表示式並不能完成抓取工作,比如很多網頁的下一頁連結是由JavaScript函式生成的比如
<li><a href="#" onclick="javascript:gotoPage('2')">2</a></li>這樣的網頁,即便你用正則表示式,提取到了
另外 如果url中還有“#”欄位的,用httpresponse,httprequest獲取的網頁原始碼流與你在瀏覽器中所看到的頁面檢視也是不同的,因此單單用正則表示式,則處理起還有js指令碼的動態網頁就顯得力不從心了。
怎麼辦?
可以採用DOM+正則+瀏覽器元件來解決上面的問題。
DOM (Document Object Model),是一個介面標準,該介面是將html網頁解析成為樹的格式,關於DOM的教程,請見:http://www.w3.org/DOM/ 雖然上面講的是JavaScript的 DOM 介面函式,但是由於DOM是一個介面標準,其他語言實現的DOM介面也是大同小異的。
正則表示式:在完成文字匹配方面有著不可或缺的作用,這個powerful的工具,DOM是無法取代的。
瀏覽器元件: 包含解釋JS語句的功能,有了瀏覽器元件的幫忙,我們的工作會更加省力(另外:園子裡有網友建議什麼Xpath,webrequest等等,沒有用過,如果有人在這方面比較熟悉不妨交流下)
本功能採用VS2008 C# Winform 平臺
在此平臺下呼叫正則要在程式的頭部加入宣告:
using System.Text.RegularExpressions;
呼叫DOM元件,需要在工程的引用中加入Microsoft.mshtml
瀏覽器元件用的是webbrowser
首先我們要在程式中構造一個簡單的瀏覽器,要有一個combobox列表框(顯示當前網頁的URL),前進和後退按鈕,控制瀏覽器重新整理檢視 實現程式碼如下:

 privatevoid btnGo_Click(object sender, EventArgs e)
privatevoid btnGo_Click(object sender, EventArgs e){
string url = comboBox1.Text.Trim();
webBrowser1.Navigate(url);
}
privatevoid btnBack_Click(object sender, EventArgs e)
{
webBrowser1.GoBack();
}
光有前進和後退還不夠,我們希望當瀏覽器檢視重新整理後,combobox裡面的URL也跟著重新整理,所以要再給瀏覽器新增一個Navigated事件,更新combobox顯示的文字。程式碼如下:
privatevoid webBrowser1_Navigated(object sender, WebBrowserNavigatedEventArgs e){
comboBox1.Text = webBrowser1.Url.ToString();
}
這還不夠,當你實現上述程式碼時你會發現,你點選webbrowser裡面的連結時,會在本地IE中顯示新網頁,所以我們還需要新增一個NewWindow事件程式碼如下
privatevoid webBrowser1_NewWindow(object sender, CancelEventArgs e){
e.Cancel =true;
if (webBrowser1.Document.ActiveElement !=null)
{
webBrowser1.Navigate(webBrowser1.Document.ActiveElement.GetAttribute("href"));
comboBox1.Text = webBrowser1.Document.ActiveElement.GetAttribute("href");
}
}
實現瞭如上程式碼,那麼程式中就配置好了一個簡易的IE瀏覽器了。剩下的問題就是如何設計爬蟲邏輯,形成自動爬蟲機器人了(這裡宣告一下:本篇博文僅提供一個自動爬蟲機器人的框架性思路,至於如何捕獲具體的網頁資訊塊兒BOI(block of interest)還需要根據網頁的具體情況配置不同的模板。
為了方便大家理解,下面給出我的任務需求
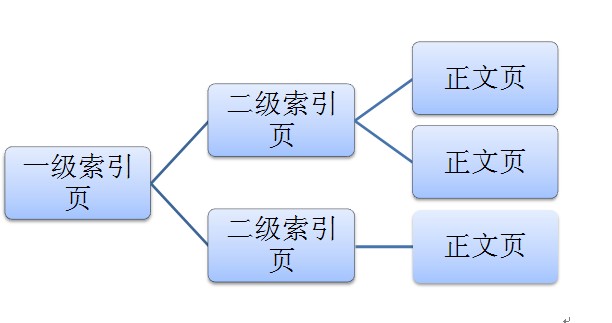
一級索引頁面包括若干指向二級索引頁面的連結,二級索引頁面又包含若干指向正文頁的連結,我們的目的是從一級索引頁獲取指向二級索引頁的連結,並且遍歷所有二級索引頁,提取出其指向正文的連結,儲存下來。 其中難點在於一級索引頁指向的是二級索引頁的首頁,二級索引頁還有若干後續頁。二級索引頁的首頁以及後續頁上都有指向正文頁的連結。可以這麼打個比方,比如一個小論壇(可以視為一級索引頁) 有三個板塊 生活(視為二級索引頁),美食,IT。不同板塊內部又分了N多頁,每個頁面上都有正向具體內容(正文頁)的連結。
所以,實現需求需要在二級索引頁的首頁進行向下翻頁。下面給出二級索引頁體現連結到下一頁的形式:

或者:

並且,所有的URL 都是用javascript函式生成的,這樣就沒有辦法用正則來解決了。
我的思路是這樣的,定位當前頁,用DOM 定位當前頁下一頁的anchor並且模擬點選。
方法是首先定位當前頁面的頁碼(這個不難辦到,因為所有的頁碼連結資訊在一個塊中,並且當前頁面對於當前頁面沒有連結),然後取出當前頁面的所有頁碼,並且按照從大到小排序,
並且比較curpageId+1與當前頁面最大頁碼之間的關係,如果curpage+1<<maxPageId,則說明在當前頁面能夠定位到當前頁的下一頁;反之,就看是否有還有Next的aTag,如果有則Next就是當前頁面的下一頁,如果不存在含有Next的aTag,則說明已經到了尾頁。
完成上面的功能,最複雜的部分是處理Webbrowser的非同步更新問題,在網上找了若干資料,覺得講得比較好的還是:http://www.hackpig.cn/post/28.html
本文的方法就是參照了連結中的博文內容,並進行改進。 下面上個圖片,說一下我的程式的工作機制
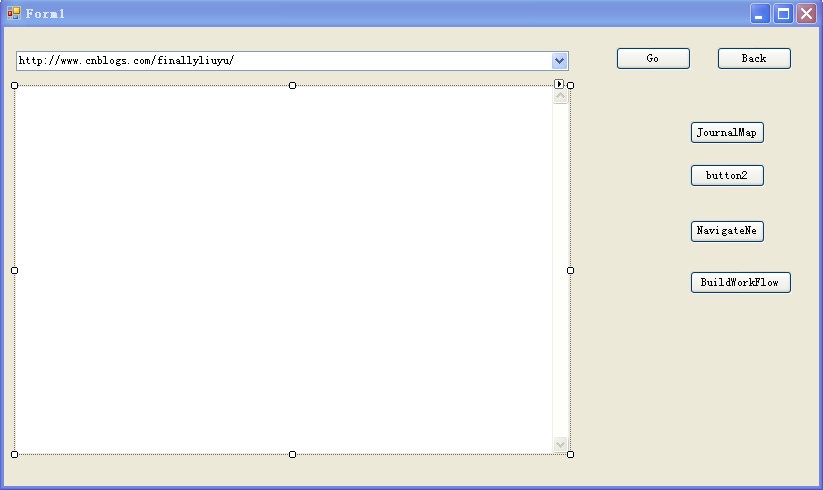
實際工作中僅用到了兩個按鈕,journapmap 和buildwokflow
按下journalmap,則獲取了一個全域性資料結構,存放各個二級索引頁的首頁地址
按下buildworkflow,則爬蟲開始自動遍歷所有二級索引頁的首頁地址,翻頁爬取正文頁的URL
在工作中,要先按journalmap按鈕,提示二級索引頁首頁地址提取出後,在按下buildworkflow按鈕,讓程式自動工作。
為了保證程式執行邏輯,為窗體宣告四個訊號變數
publicbool mysignal1;//btnworkflow按鈕是否被點選publicbool mysignal2;publicbool loading;//工作流按鈕與webbrowser進行互動的通訊按鈕publicbool subloading;
並做如下初始賦值:
public Form1(){
InitializeComponent();
mysignal1 =false;
mysignal2 =false;
loading =true;
subloading =true;
issuesMap =new List<string>();
}
下面給出BuidWorkFlow和webbrowser.documentcompleted的程式碼,看看這兩者是如何互動工作的
privatevoid btnworkflow_Click(object sender, EventArgs e){
mysignal1 =true;
List<ArticlePage> arListCurrentPage;
foreach (string s in issuesMap)
{
loading =true;
string tmpurl = s;
webBrowser1.Navigate(tmpurl);
while (loading ==true)
{
Application.DoEvents();
}
arListCurrentPage = GetArticlePageInfoFromCurrentDirpage();
if (arListCurrentPage !=null)
{
InsertTitleUrlToDataBase(arListCurrentPage);
}
mysignal2 =true;
while (AnchorNextPage())
{
subloading =true;
while(subloading)
{
Application.DoEvents();
}
arListCurrentPage = GetArticlePageInfoFromCurrentDirpage();
if (arListCurrentPage !=null)
{
InsertTitleUrlToDataBase(arListCurrentPage);
}
}
mysignal2 =false;
//獲得當前頁面的下一頁連結
}
}
privatevoid webBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e){
if (webBrowser1.ReadyState ==WebBrowserReadyState.Complete)
{
if (mysignal1)
{
if (!mysignal2)
{
loading =false;
}
else
{
subloading =false;
}
}
}
}
解釋一下 btnworkflow和webbrowser互動工作的原理。 按下btnworkflow按鈕,mysingal1的值就為真,這時候 webbrowser文件載入完畢後給loading賦值為假,使btnworkflow迴圈後面的程式碼得以執行,即將二級索引頁首頁中所包含的正文URL提取出來儲存到資料庫,之後mysignal2的值為真,這時候,webbrowser文件載入完畢後給subloading賦值為假,使得btnworkflow中子迴圈得以不斷執行,周而復始地完成提取當前頁正文URL連結,翻到下一頁,直到沒有下一頁可翻了,btnworkflow的子迴圈退出,mysignal2被賦值為假,webbrowser文件載入完畢後更新loading為假,使得下一個二級索引首頁的內容能夠提取出來。
幾點要說明的是:我在完成此功能的時候,參考了網路上很多程式碼片段,很多的程式碼片段在webbrowser_documentcompleted函式中,完成解析內容,獲取下一頁連結,翻頁的程式碼。這樣做
很容易出現資訊提取重複(即一個頁面提取了兩到三次)。
最後給出程式中利用DOM點選下一頁的程式碼:
privatebool AnchorNextPage(){ bool rstStatus=false;
.......中間的程式碼是利用正則表示式和DOM函式(如GetElementByTagName,GetElementById等)定位到當前頁的下一頁連結
if (htmlElemNext !=null)
{
mshtml.IHTMLElement anchor = (mshtml.IHTMLElement)htmlElemNext.DomElement;
anchor.click();//模擬點選 rstStatus=true;
}
return rstStatus;
}